Meta最近发布的LLAMA3模型迅速成为最强大的大型语言模型(LLM)系列,引起了研究人员的极大兴趣。基于这一势头,全面评估LLAMA3在各种低比特权量化技术中的性能,包括后训练量化和LoRA微调量化:8bit 量化基本无损失;AWQ 4bit量化对8B模型来说有2%性能损失,对70B模型只有0.05%性能损失;参数越大的模型,低bit量化损失越低,AWQ 3bit 70B 也只有2.7%性能损失。
LLaMA3-8B/LLaMA3-70B实证研究的概述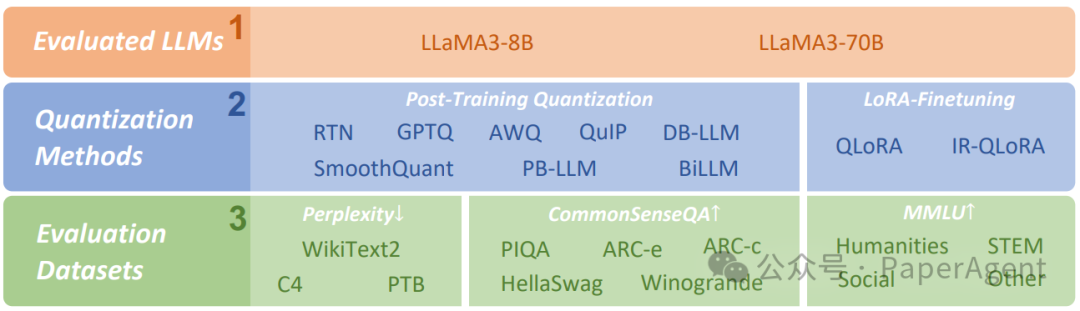
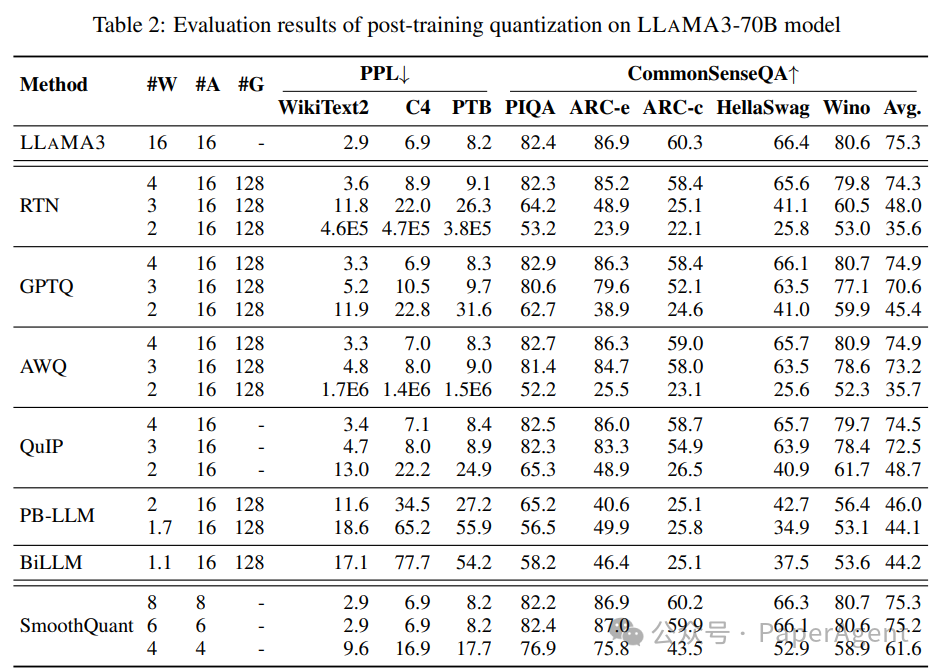
?主要关注两种主要的量化方法:后训练量化(Post-Training Quantization,PTQ)和LoRA微调(LoRA-FineTuning,LoRA-FT)量化。? 评估了多种最先进的量化方法,涵盖了一系列比特宽度(从1到8位)。这包括RTN(四舍五入到最近)、GPTQ、AWQ、SmoothQuant、PB-LLM、QuIP、DB-LLM、BiLLM、QLoRA和IR-QLoRA等方法。每种方法都采用不同的技术来量化权重和激活,旨在在最大化压缩的同时最小化精度损失。? 评估是在多样化的数据集上进行的,包括WikiText2、C4、PTB、常识问答数据集(PIQA、ARC-e、ARC-c、HellaSwag、Winogrande)和MMLU基准测试。这确保了结果代表了LLAMA3在不同任务和领域的表现。? 结果显示,当量化到较低比特宽度时,LLAMA3会经历明显的性能下降。虽然仍然优于其他模型,但这突出了在资源有限的设备上部署LLAMA3的挑战。? 像PB-LLM、DB-LLM和BiLLM这样的二值化LLM量化方法在超低比特宽度(≤2位)下显示出实现更高准确性的希望,与GPTQ和AWQ等方法相比。这些方法采用混合精度量化、双重二值化和残差近似等技术,在实现高压缩的同时保持准确性。? 有趣的是,LLAMA3在LoRA-FT量化下的性能并没有像预期的那样提高。研究表明,LLAMA3在庞大数据集上的预训练使得在较小数据集上进行的低秩微调难以弥补量化误差。这对像LLAMA3这样的强大模型的LoRA-FT量化技术提出了新的范式要求。LLAMA3-8B模型后训练量化的评估结果 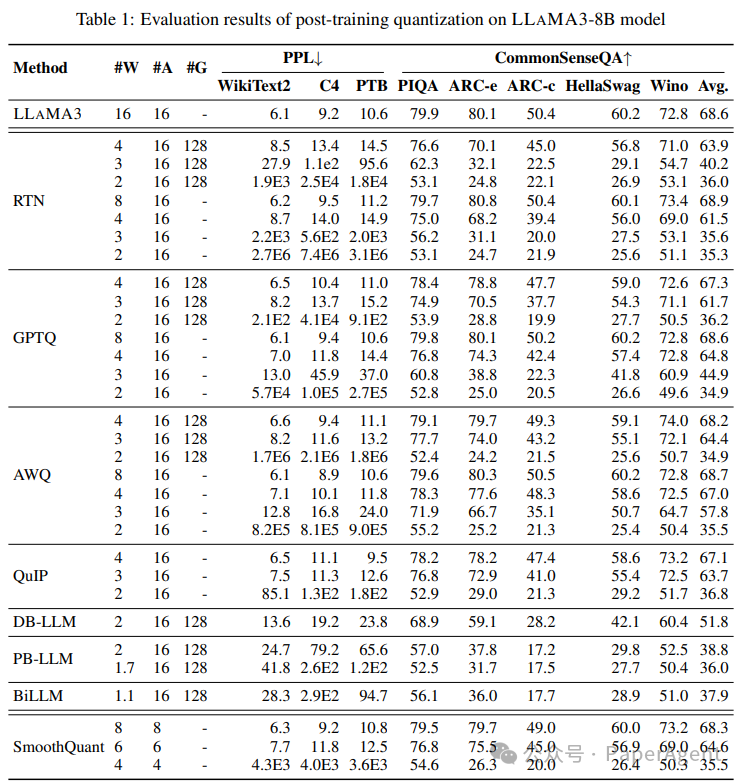
在Alpaca数据集上对LLAMA3-8B模型进行LoRA-FT(低秩微调)量化 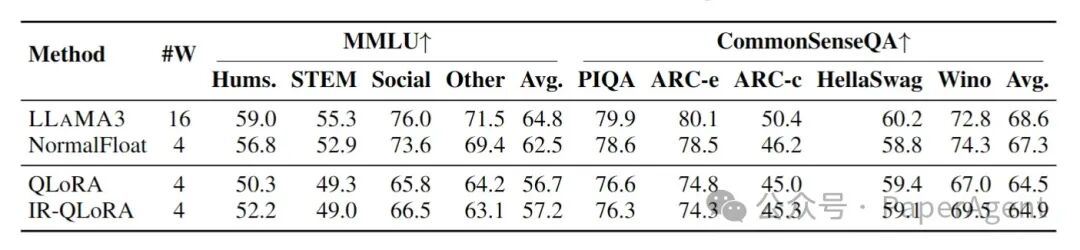
HowGoodAreLow-bitQuantizedLLAMA3Models?AnEmpiricalStudyhttps://arxiv.org/pdf/2404.14047https://github.com/Macaronlin/LLaMA3-Quantizationhttps://twitter.com/9hills/status/1783271853790015828
| 









