|
 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;"/> ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;"/>
论文《Retrieval-Augmented Generation for Large
Language Models: A Survey》对检索增强生成(RAG)总结了如下三种方式:
推荐阅读该论文的详解:
LLM之RAG理论(二)| RAG综述论文详解 高级RAG旨在解决Naive RAG的局限性。本文把这些技术,可分为预检索(pre-retrieval)、检索(retrieval)和检索后(post-retrieval)优化。 在下半部分中,首先使用Llamaindex实现一个简单的RAG管道,然后通过选择以下高级RAG技术将其增强为高级RAG管道: 检索前优化:语句窗口检索 检索优化:混合搜索 检索后优化:重新排序
一、高级RAG 高级RAG与Naive RAG对比,如下图所示:
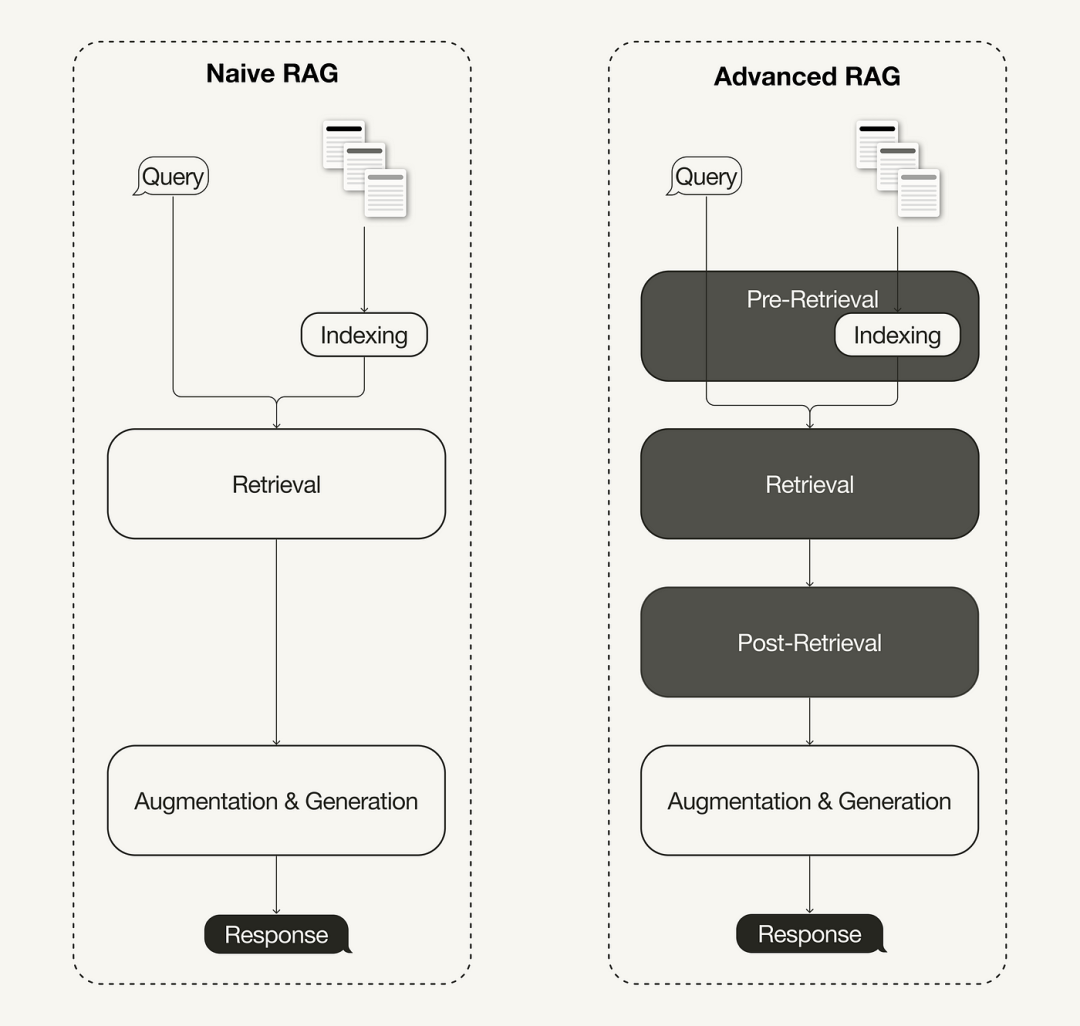
1.1 预检索优化 预检索优化侧重于数据索引优化和查询优化。数据索引优化技术旨在提高存储数据的检索效率,例如: 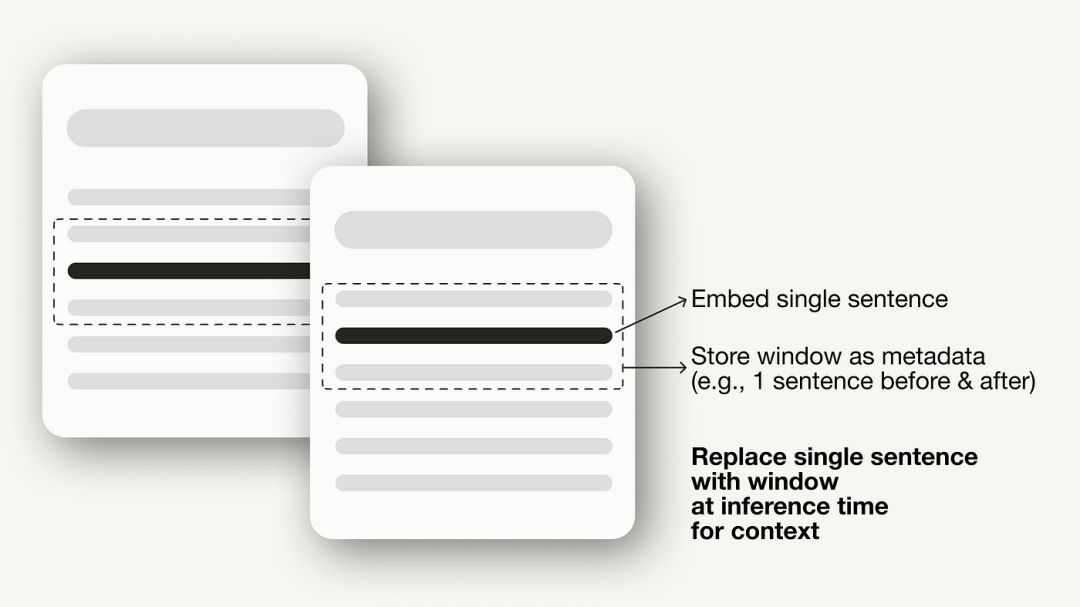
此外,预检索技术并不局限于数据索引,还可以涵盖推理时的技术,如查询路由、查询重写和查询扩展。 1.2 检索优化 检索阶段旨在识别最相关的上下文。通常,检索是基于向量搜索的,向量搜索计算查询和索引数据之间的语义相似性。因此,大多数检索优化技术都围绕着嵌入模型[1]:
除了矢量搜索之外,还有其他检索技术,例如混合搜索,是指将矢量搜索与基于关键字的搜索相结合。如果您的检索需要精确的关键字匹配,那么混合搜索是非常合适的。
1.3 检索后优化 有时候需要对检索到的上下文进行额外的处理,比如检索到的内容超出上下文窗口限制或引入了噪声之类的问题。下面介绍一些检索后处理技术: 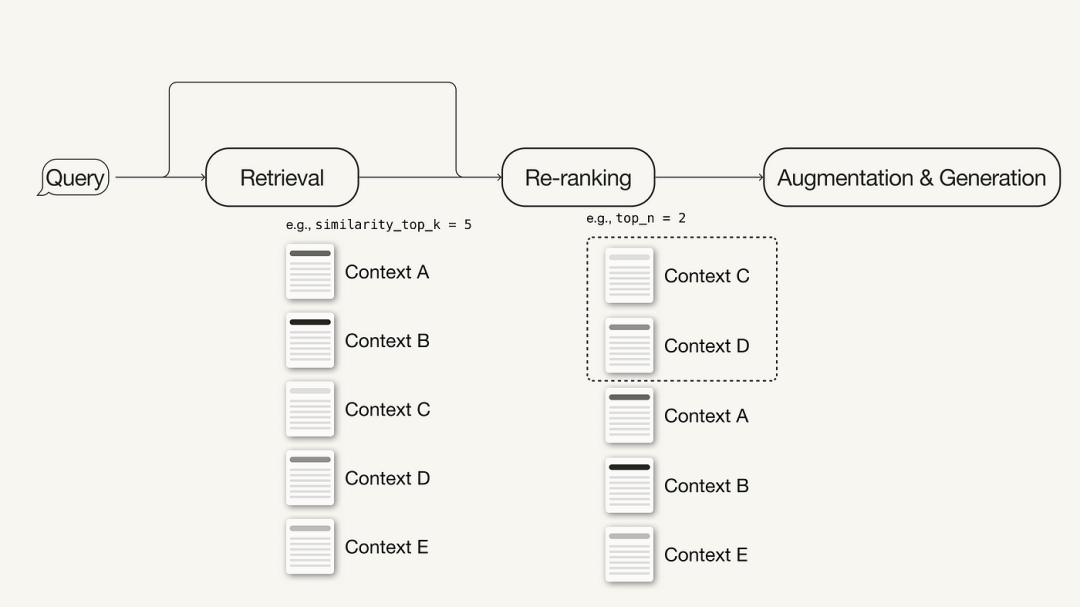
二、代码实现 2.1 安装所需的包 在本文中,我们将使用LlamaIndex v0.10。如果您是从较旧的LlamaIndex版本升级,则需要运行以下命令才能正确安装和运行LlamaIndex: pipuninstallllama-indexpipinstallllama-index--upgrade--no-cache-dir--force-reinstall LlamaIndex提供了一种将矢量嵌入存储在本地JSON文件中以进行持久存储的功能,这对快速构建想法的原型非常有用。然而,在生产环境中,我们将使用矢量数据库进行持久存储。 由于除了存储矢量嵌入之外,我们还需要元数据存储和混合搜索功能,因此我们将使用支持这些功能的开源矢量数据库Weaviate(v3.26.2)。 pipinstallweaviate-clientllama-index-vector-stores-weaviate 2.2 API密钥 我们将使用Weaviate嵌入式,您可以在不注册API密钥的情况下免费使用。然而,本教程使用了来自OpenAI的嵌入模型和LLM,为此您需要一个OpenAI API密钥。要获得一个,您需要一个OpenAI帐户,然后在API密钥下“创建新密钥”。 接下来,在根目录中创建一个本地.env文件,并在其中定义API密钥: OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>" 之后,使用以下代码加载API密钥: # !pip install python-dotenvimport osfrom dotenv import load_dotenv,find_dotenv
load_dotenv(find_dotenv())
2.3 用LlamaIndex实现Naive RAG 本节讨论如何使用LlamaIndex实现一个简单的RAG管道,完整的Naive RAG管道可以参考这个Jupyter笔记本[2]。对于使用LangChain实现Naive RAG管道,可以参考[3]。 步骤1:定义嵌入模型和LLM 首先,可以在全局设置对象中定义嵌入模型和LLM。这样做意味着不必再次在代码中显式指定模型。 嵌入模型:用于为文档块和查询生成矢量嵌入。 LLM:用于根据用户查询和相关上下文生成答案。 from llama_index.embeddings.openai import OpenAIEmbeddingfrom llama_index.llms.openai import OpenAIfrom llama_index.core.settings import Settings
Settings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)Settings.embed_model = OpenAIEmbedding()
步骤2:加载数据 接下来,将在根目录中创建一个名为data的本地目录,并从LlamaIndex GitHub存储库(MIT许可证)[4]下载一些示例数据。 !mkdir-p'data'!wget'<https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt>'-O'data/paul_graham_essay.txt' 之后,可以加载数据以进行进一步处理: from llama_index.core import SimpleDirectoryReader
# Load datadocuments = SimpleDirectoryReader(input_files=["./data/paul_graham_essay.txt"]).load_data()
步骤3:将文档分块到节点中 由于整个文档太大,无法放入LLM的上下文窗口,因此需要将其划分为较小的文本块,这些文本块在LlamaIndex中称为Nodes。使用SimpleNodeParser将加载的文档解析为块大小为1024的节点。 from llama_index.core.node_parser import SimpleNodeParser
node_parser = SimpleNodeParser.from_defaults(chunk_size=1024)
# Extract nodes from documentsnodes = node_parser.get_nodes_from_documents(documents)
步骤4:建立索引 接下来,需要构建一个索引,将所有外部知识存储在开源矢量数据库Weaviate中。 首先,需要连接到Weaviate实例。在这种情况下,我们使用WeaviateEmbedded,它允许您在没有API密钥的情况下免费在笔记本中进行实验。对于生产就绪的解决方案,建议自己部署Weaviate,例如通过Docker或使用托管服务。 import weaviate
# Connect to your Weaviate instanceclient = weaviate.Client(embedded_options=weaviate.embedded.EmbeddedOptions(), )
接下来,将从Weaviate客户端构建一个VectorStoreIndex,用于存储数据并与之交互。 from llama_index.core import VectorStoreIndex, StorageContextfrom llama_index.vector_stores.weaviate import WeaviateVectorStore
index_name = "MyExternalContext"
# Construct vector storevector_store = WeaviateVectorStore(weaviate_client = client, index_name = index_name)
# Set up the storage for the embeddingsstorage_context = StorageContext.from_defaults(vector_store=vector_store)
# Setup the index# build VectorStoreIndex that takes care of chunking documents# and encoding chunks to embeddings for future retrievalindex = VectorStoreIndex(nodes,storage_context = storage_context,)
步骤5:设置查询引擎 最后,将把索引设置为查询引擎。 #TheQueryEngineclassisequippedwiththegenerator#andfacilitatestheretrievalandgenerationstepsquery_engine=index.as_query_engine() 步骤6:运行一个简单的RAG查询 现在,可以对数据运行一个简单的RAG查询,如下所示: #RunyournaiveRAGqueryresponse=query_engine.query("WhathappenedatInterleaf?")2.4 用LlamaIndex实现高级RAG 接下来,我们如下高级RAG技术来提高Naive RAG管道效果:
预检索优化:语句窗口检索 检索优化:混合搜索 检索后优化:重新排序
a)索引优化示例:语句窗口检索 对于语句窗口检索技术,需要进行两个调整:首先,必须调整数据的存储和后处理方式,使用PensioneWindowNodeParser替换SimpleNodeParser。 from llama_index.core.node_parser import SentenceWindowNodeParser
# create the sentence window node parser w/ default settingsnode_parser = SentenceWindowNodeParser.from_defaults(window_size=3,window_metadata_key="window",original_text_metadata_key="original_text",)
PensioneWindowNodeParser主要实现如下两个步骤: 它将文档分隔为单个句子,这些句子将被嵌入; 对于每个句子,它都会创建一个上下文窗口。如果指定window_size=3,则生成的窗口将有三个句子长,包括嵌入句子的前一个句子和后面一个句子。该窗口将作为元数据存储。
在检索过程中,将返回与查询最匹配的句子。检索后,您需要通过定义MetadataReplacementPostProcessor并在node_postprocessors列表中使用它,将句子替换为元数据中的整个窗口。 from llama_index.core.postprocessor import MetadataReplacementPostProcessor
# The target key defaults to `window` to match the node_parser's defaultpostproc = MetadataReplacementPostProcessor(target_metadata_key="window")
...
query_engine = index.as_query_engine( node_postprocessors = [postproc],)
b)检索优化示例:混合搜索 如果底层矢量数据库支持混合搜索查询,那么在LlamaIndex中实现混合搜索就像对query_engine进行两个参数更改一样容易。alpha参数指定矢量搜索和基于关键字的搜索之间的权重,其中alpha=0表示基于关键字的检索,alpha=1表示纯矢量搜索。 query_engine=index.as_query_engine(...,vector_store_query_mode="hybrid",alpha=0.5,...) c)检索后优化示例:重新排序 在高级RAG管道中添加重新排序只需三个简单步骤: 首先,定义一个重新排序模型。在这里,我们使用Huggingface中的BAAI/bge-reranker-base; 在查询引擎中,将reranker模型添加到node_postprocessors列表中; 增加查询引擎中的similarity_top_k以检索更多的上下文段落,重新排序后可以减少到top_n。
# !pip install torch sentence-transformersfrom llama_index.core.postprocessor import SentenceTransformerRerank
# Define reranker modelrerank = SentenceTransformerRerank(top_n = 2, model = "BAAI/bge-reranker-base")
...
# Add reranker to query enginequery_engine = index.as_query_engine(similarity_top_k = 6,...,node_postprocessors = [rerank],...,)
三、总结 本文介绍了高级RAG的概念,其中包括一组技术来解决原始RAG范式的局限性。在概述了高级RAG技术(可分为预检索、检索和后检索技术)之后,本文使用LlamaIndex进行编排,实现了一个简单而高级的RAG管道。 RAG管道组件是OpenAI的语言模型、托管在Hugging Face上的BAAI的重新排序模型和Weaviate矢量数据库。 我们在Python中使用LlamaIndex实现了以下技术选择: 检索前优化:语句窗口检索 检索优化:混合搜索 检索后优化:重新排序
| 









