|

? 全新llama3:ollama与lobe-chat的结合使用指南 ?
???开启你的AI助手新纪元!
最新动态:今天要介绍一个令人激动的新进展---全新llama3模型的一键部署,以及如何利用ollama和lobe-chat作为Agents,让你的AI体验更上一层楼!

? 什么是llama3?
llama3是meta的最新力作,一个具有海量参数和卓越性能的AI大模型。它不仅能够执行复杂的任务,还能提供更加精准和个性化的结果。
? 为什么要用ollama?
ollama是一个开源工具,它可以让你在本地运行AI大模型,保护隐私的同时享受AI的便利。
关于部署
ollama的部署随便搜索都有,真的很简单,windows用户,下载EXE文件,双击文件,一路下一步即可。具体可以参考以往的文章:
一键部署大模型,Windows用户的福音!
ollama run llama3
? lobe-chat:你的私人Agents
lobe-chat是一个先进的聊天界面,它可以作为你的私人Agents,帮助你与llama3模型进行交互。无论是日常咨询还是专业问题,lobe-chat都能提供即时、智能的反馈。
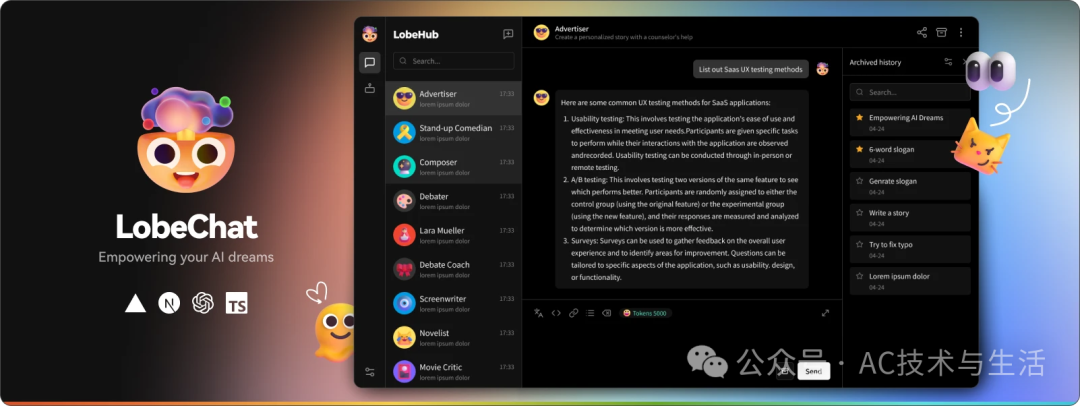
? 个性化你的体验
lobe-chat不仅支持基本的聊天功能,还可以根据你的需要进行个性化设置。无论是界面风格还是对话模式,都能按照你的喜好来调整。

? 自定义体验
• 多模型支持:选择适合你需求的模型。 • 视觉识别:利用llm的视觉识别能力。 • 语音会话:TTS & STT,让交流更自然。 • 文生图:将文本想法转化为图像。
关于部署
只要一句命令即可开启它们的交互:
docker run -d -p 3210:3210 -e OLLAMA_PROXY_URL=http://host.docker.internal:11434/v1 lobehub/lobe-chat
具体还有更多功能或设定,请继续查阅文章的最后,参考资料哟。
? 注意事项
说起硬件配置
如何才能运行起这些的AI服务呢?
极摩客K8 迷你主机
| 特性 |
描述 |
| 处理器 |
AMD R7 8845HS,具备强大的计算能力,适合执行AI相关任务 |
| 架构 |
Zen 4,先进的架构设计,有助于提升AI处理效率 |
| 核心数 |
8核心,多核心设计有利于进行多任务AI计算 |
| 线程数 |
16线程,高线程数有助于提高并行处理能力 |
| 频率 |
最大加速时钟频率5.1GHz,高频率有助于快速处理AI数据 |
| 缓存 |
16MB L3缓存,大缓存有助于提高数据访问速度,对AI计算有益 |
| 集成显卡 |
Radeon 780M,具备一定的图形处理能力,可支持基础的AI视觉任务 |
| 内存支持 |
DDR5 5600 / SO-DIMM*2,高速内存支持,有助于提升AI计算性能 |
| 存储 |
PCIe 4.0*4 M.2 2280 SSD,高速存储,有利于AI模型的快速加载 |
| 连接性 |
WiFi 6 & 蓝牙5.2,快速的无线连接能力,便于远程AI数据交互 |
| 接口 |
丰富的接口支持,便于连接AI外设或高速数据传输 |
| 性能测试 |
在多线程跑分和综合性能测试中表现出色,证明其AI处理能力强 |
| 用户评价 |
用户普遍认为性价比高,性能强劲,适合包括AI在内的多种应用 |
| 适用场景 |
游戏电竞、商用办公、AI计算等 |
这主机在2024年非常适合家用及小公司使用。
家用
配合27寸2K显示器,又不占位置,给老人/小孩使用相当合适,用个3-5年不是问题。
公司
两个网口,安装PVE虚拟化系统,运行软防火墙,交换机等小型服务,妥妥的办公小能手。


个人使用
无论搞计算机编程还是一般的游戏,它完全可以驾驭。

有钱的朋友还可以加个显卡扩展坞,直接把性能拉满,作为养家糊口的工具。
一起学习,一起进步,一起飞!
? 记得点赞、分享,让更多的朋友一起探索这个IT世界的新奇!?
记得按时休息
? 推荐阅读
https://ollama.com/library/llama3
https://github.com/lobehub/lobe-chat
https://lobehub.com/docs/usage/providers/ollama
https://lobehub.com/docs/self-hosting/examples/ollama
欢迎关注我的公众号“AC技术与生活”,原创技术文章第一时间推送。

| 









