时间是检验技术实力的最佳方式之一。 DeepSeek Coder,作为深度求索首次亮相的开源模型,仅三个月便在HuggingFace上获得了超8.5万次下载!
自DeepSeek Coder一经开源,最常被问到的便是:什么时候发布技术报告? 今天,我们终于交卷了!文后将深度解读其后的关键技术。 DeepSeek Coder论文地址: https://arxiv.org/abs/2401.14196 
 技术报告Highlights 技术报告Highlights
- 数据:首次构建了仓库级代码数据,并用拓扑排序解析文件之间依赖,显著增强了长距离跨文件的理解能力。
- 训练:在传统的预测下一个单词任务基础上,增加了Fill-In-Middle方法,大幅提升了代码补全的能力。
- 效果:对比开源模型,DeepSeek Coder的各尺度模型在代码生成、跨文件代码补全、以及程序解数学题等多个任务上均超过开源标杆CodeLllama。对比闭源模型,DeepSeek-Coder-33B-Instruct甚至超越了最新闭源模型GPT-3.5-Turbo,是最接近GPT-4-Turbo能力的开源代码模型。

数据
DeepSeek Coder的训练数据集构成如下:- 87%代码数据:主要来自2023年2月前的GitHub,覆盖87种编程语言
- 10%代码相关的英文语料:主要来自GitHub的Markdown格式文件以及StackExchange
- 3%非代码相关的中文语料:旨在提高模型对中文理解能力
代码数据过滤结合了规则、编译器和质量打分模型,来去除含有语法错误、可读性差和模块化低的代码,最终得到798G大小的高质量代码数据,共6亿个代码文件。为了确保预训练数据不被来自测试集数据污染(比如类似HumanEval和MBPP等普遍存在于GitHub上),我们采纳了一个n-gram过滤方法:如果一段代码包含与测试数据中任何10-gram字符串相同的内容,则会被从预训练数据中删除。为了处理在实际应用中项目级别(Repo-Level)的代码场景,我们在提出了一个全新的拓扑排序方法,来利用同一代码库中文件之间的依赖关系,构建能反映真实的编码实践和结构的数据集。去重策略也是基于Repo-Level数据。
训练训练包含三个阶段,先在Code和中英混合数据上预训练了1.8T Tokens,再进行长度插值外扩继续训练了200B Tokens,最后进行指令微调了2B Tokens。 训练任务由于编程语言中的特定依赖性,仅根据上文预测下文是不够的,典型的常见如代码补全,需要基于给定上文和后续文本生成相应插入代码。因此我们沿用前人提出的提出了FIM(Fill-in-the-Middle)方法,即:填补中间代码的预训练方法。 这种方法涉及将文本随机分成三部分(Prefix、Middle、Suffix),然后将Prefix和Suffix顺序打乱来预测Middle。具体来说,我们采用了两种不同新的数据拼接模式:PSM(Prefix-Suffix-Middle)和SPM(Suffix-Prefix-Middle)。这两种模式对于增强模型处理代码中各种结构排列的能力非常重要。考虑到尽量保持自然序列关系,最终我们选择了PSM模式。 上图设计了消融实验对比FIM数据占比对训练的影响,发现FIM数据50%占比(红色)能更好兼顾代码生成(HumanEval、MBPP)和代码补全(HumanFIM)类任务。训练超参 DeepSeek Coder全系列模型训练超参数如下:长度外扩为了支持仓库级的代码训练,我们重新配置了RoPE的参数,并采用了线性缩放策略,将缩放因子从1增加到4,并将基础频率从10000改为100000。修改了配置的模型使用了512的Batch Size和16K的序列长度继续训练了1000步。理论上,最终的模型能够处理64K的上下文。但我们实验发现,16K内窗口内的模型结果比较可靠。
实验对于Base模型,DeepSeek-Coder-Base 33B在HumanEval基准测试中的多个代码语言上均能大幅超越目前开源代码模型。惊艳的是,DeepSeek-Coder-Base 6.7B也超过了CodeLlama 34B的性能,但参数量仅为后者的20%。 在经过指令微调后,我们的模型在HumanEval基准测试中超过了闭源的GPT-3.5-Turbo模型,是目前最接近GPT-4的性能的开源代码模型。 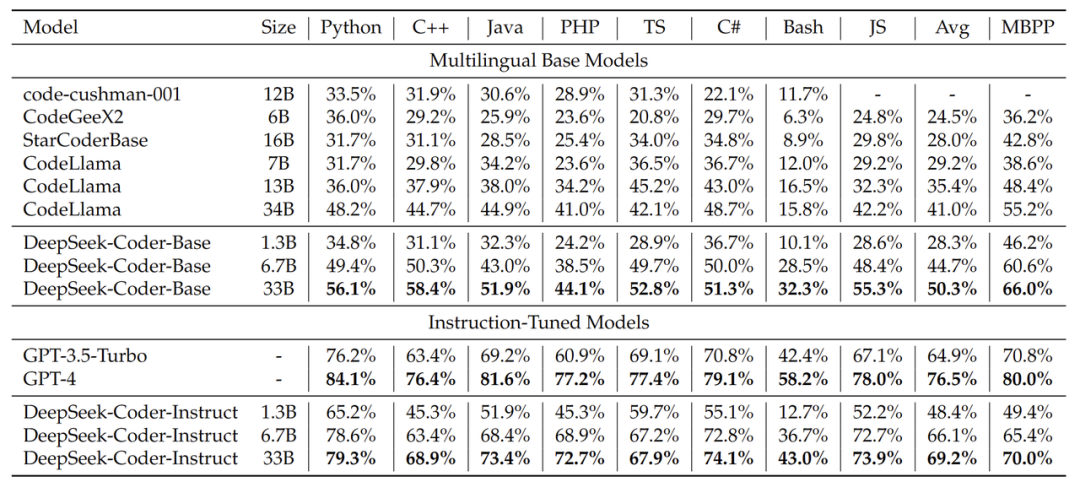
为了验证模型在样本外下真实的代码理解和生成能力,我们构造了一个全新的数据集,题目均来自LeetCode每周更新的编程题,按照难度区分为:Easy、Medium、Hard。 上图可以看出,33B的DeepSeek-Coder同样超过了GPT-3.5-Turbo,并且我们发现COT(Chain-of-Thought)的方式可以更好增加我们模型的代码能力。故而强烈推荐在一些复杂的代码任务上使用DeepSeek Coder模型的时候,简单在Prompt里面增加一句: You need first to write a step-by-step outline and then write the code.
跨文件代码补全能力在实际代码补全应用中,理解跨众多依赖代码文件之间的关系是至关重要的。 受益于Repo-Level的预训练任务,DeepSeek-Coder-Base 6.7B的跨文件代码补全在大部分语言上都表现更佳。 基于程序的数学推理能力基于程序的数学推理可以评估大模型通过编程理解和解决数学问题的能力。
上图展示了在七个不同的数学能力基准测试中,DeepSeek-Coder-Base多尺度的各个模型都取得了出色的表现,尤其是更大尺度的33B模型,展示了复杂数学计算和问题解决的潜力。 公开竞赛超过GPT3.5逼近4在诸多代码能力公开竞赛榜单上,都能看到DeepSeek Coder是目前最贴近GPT4-Turbo版本(绿线)的开源模型,在同等非COT设置下,也超过了CPT-3.5-Turbo(红线)。 案例分析与经过指令微调的DeepSeek-Coder-Instruct进行对话,可以轻松创建小型游戏或进行数据分析,并且在多轮对话中满足用户的需求。 全新代码模型v1.5开源伴随此次技术报告还有一个模型开源,DeepSeek-Coder-v1.57B:在通用语言模型DeepSeek-LLM7B的基础上用代码数据进行继续训练了1.4T Tokens,最终模型全部训练数据的组成情况如下: 
相比上次开源的同尺度的6.7B的Coder,DeepSeek-Coder-v1.5获得了更好的语言理解、代码编程和数学推理等能力。更大尺度、更强综合能力的Coder模型正在训练中,我们会持续贡献给开源社区! https://huggingface.co/deepseek-ai 关于DeepSeek回顾下DeepSeek目前开源模型列表: 下一步,深度求索会继续开源更大尺度、创新框架、以及复杂推理能力更好的模型!
—end— | 









