|
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin-right: auto;margin-bottom: 1em;margin-left: auto;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(250, 81, 81);color: rgb(63, 63, 63);">Llama3-70B微调上下文8K到1M+ 
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 4em auto 2em;padding-right: 0.2em;padding-left: 0.2em;background: rgb(250, 81, 81);color: rgb(255, 255, 255);">Llama-3-70B-Instruct-Gradient-1048k介绍ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;">近日Gradient团队发布了一款名为:gradientai/Llama-3-70B-Instruct-Gradient-1048k的LLM模型。这是一个使用Llama3作为基础模型的微调版本。Llama-3-70B-Instruct-Gradient-1048k这个模型将Llama-3 70B的上下文长度从 8k 扩展到 > 1048K。同时该模型也展示了 SOTA LLM 通过适当调整RoPE theta参数情况下,就可以在最小的训练下学习操作长上下文。研发团队在这个阶段训练使用了 34M 令牌,所有阶段总共训练了约 430M Token令牌,这不到 Llama-3 最初预训练数据的 0.003%。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.1em;font-weight: bold;margin-top: 2em;margin-right: 8px;margin-bottom: 0.75em;padding-left: 8px;border-left: 3px solid rgb(250, 81, 81);color: rgb(63, 63, 63);">训练方法:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">同时研发团队也提供了训练方法细节:•以meta-llama/Meta-Llama-3-70B-Instruct作为微调模型的基础base模型 •遵循LLM scaling laws 法则进行NTK-aware 插值,以设置RoPE theta的最优时间表 •类似于Large World Model的逐步训练,增加模型窗口上下文长度。Large World Model:https://huggingface.co/LargeWorldModel
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.1em;font-weight: bold;margin-top: 2em;margin-right: 8px;margin-bottom: 0.75em;padding-left: 8px;border-left: 3px solid rgb(250, 81, 81);color: rgb(63, 63, 63);">训练基础设施ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">在本次模型微调中,Gradient团队是基于EasyContext Blockwise RingAttention库构建,以在Crusoe Energy高性能 L40S集群上可扩展和高效地训练非常长的上下文。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">并且团队在Ring Attention上增加了并行性,并使用自定义网络拓扑以更好地利用大型 GPU 集群,来解决设备之间传递许多KV块的网络瓶颈。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.1em;font-weight: bold;margin-top: 2em;margin-right: 8px;margin-bottom: 0.75em;padding-left: 8px;border-left: 3px solid rgb(250, 81, 81);color: rgb(63, 63, 63);">训练数据:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">在训练数据上,Gradient团队通过增强SlimPajama生成长上下文,同时还基于UltraChat的聊天数据集进行了微调,遵循下面图表中数据增强的类似配方,逐步训练细节如下: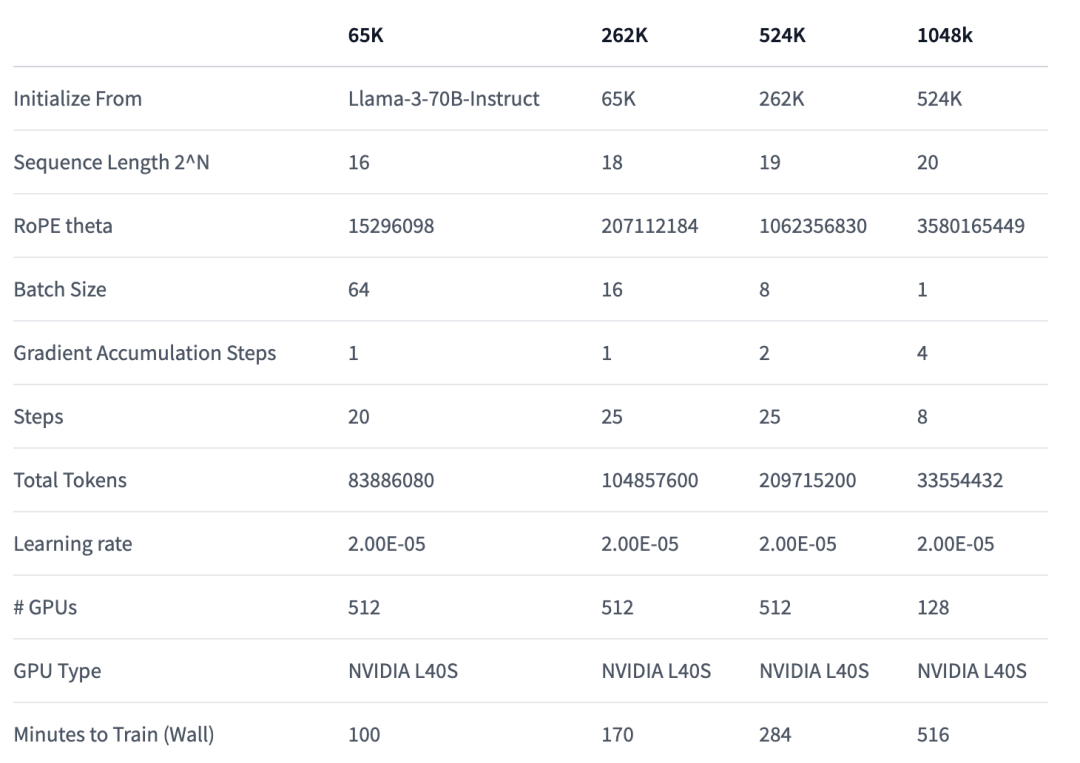
Ollama体验当前社区已有Ollama版本支持,可以使用Ollama快速体验:https://ollama.com/library/llama3-gradient 
关于Ollama使用,请参见之前文章: •Ollama:LLM大语言模型本地部署利器 •Ollamac:开源Ollama集成macOS客户端 •Llama3:开源LLM新里程碑,Ollama和OpenWebUI本地部署指南 •ChatOllama:支持Ollama&OpenAI多种LLM模型的本地私有AI知识库助手
ollamarunllama3-gradient 附录 |










