介绍利用Neo4j Aura和Neo4j Desktop存储向量索引,并在LangChain框架辅助下构建高效的检索增强生成(RAG)应用。

Neo4j 通过集成原生的向量搜索功能,增强了其对检索增强生成(RAG)应用的支持,这标志着一个重要的里程碑。这项新功能通过向量索引搜索处理非结构化文本,增强了 Neo4j 在存储和分析结构化数据方面的现有优势,进一步巩固了其在存储和分析结构化数据方面的领先地位。
本文详细介绍如何利用 Neo4j Desktop(本地版)和 Neo4j Aura(云服务版)来存储向量索引,并构建一个基于纯文本数据的 RAG 应用。
1 云服务部署
要使用基于云的 Neo4j Aura,需要按照以下步骤操作:
首先,点击链接创建一个实例(https://neo4j.com)。在设置过程中,系统会提示输入默认的用户名(neo4j)和实例的密码。请务必记下这个密码,因为设置后将无法再次查看。
创建账户后,会看到这样的界面:
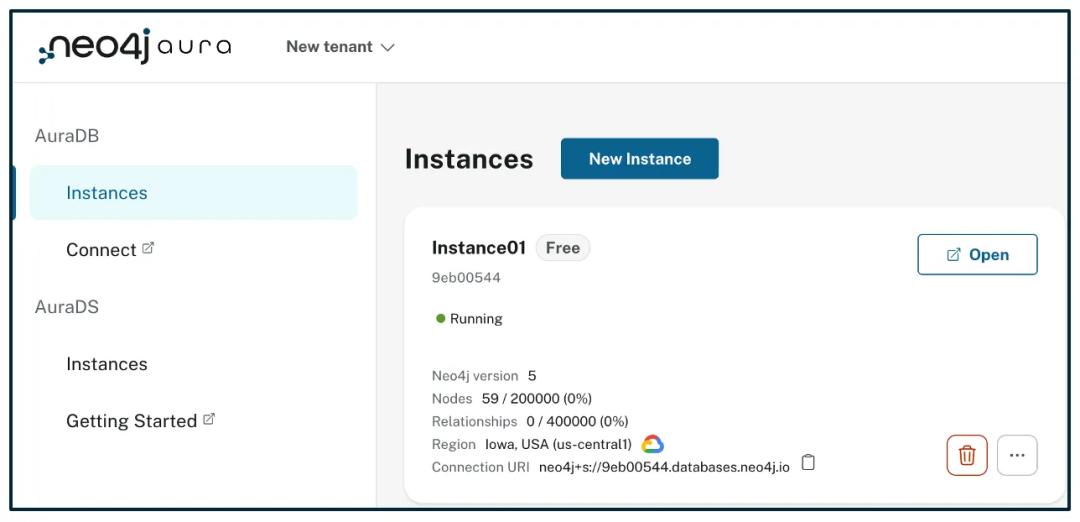
实例启动并运行后,接下来的任务是生成嵌入向量并将其存储。这里采用OpenAI的嵌入技术,这需要一个OPENAI_API_KEY。
为了将这些嵌入向量上传到Neo4j Aura实例,需要准备好以下环境变量:NEO4J_URI(Neo4j实例的URI)、NEO4J_USERNAME(用户名)和NEO4J_PASSWORD(密码)。
使用LangChain的WikipediaLoader功能,直接从Wikipedia网页中导入文章内容。
然后,将文章拆分成多个段落,并去除所有元数据,因为我们不需要存储这些信息。
importos
fromlangchain.vectorstoresimportNeo4jVector
fromlangchain.embeddings.openaiimportOpenAIEmbeddings
fromlangchain.document_loadersimportWikipediaLoader
fromlangchain.text_splitterimportCharacterTextSplitter
fromlangchain_core.promptsimportChatPromptTemplate
fromlangchain_core.output_parsersimportStrOutputParser
fromlangchain_core.promptsimportChatPromptTemplate
fromlangchain_core.runnablesimportRunnablePassthrough
#OPENAIAPI密钥
os.environ["OPENAI_API_KEY"]="sk-G7F8rdGxxXOWegj5nxxx3BlbkFJj7AuFUP5yyyAKKxSVTGQw"
#neo4j凭证
NEO4J_URI="neo4j+s://9cb33544.databases.neo4j.io"
NEO4J_USERNAME="neo4j"
NEO4J_PASSWORD="rexxxJJOzDt4kjaaKgM_VyWUdT9GE4hNBXXGMNubg"
#加载数据和分块
#读取Wikipedia文章
raw_documents=WikipediaLoader(query="LeonhardEuler").load()
#定义分块策略
text_splitter=CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000,chunk_overlap=20
)
#分块文档
documents=text_splitter.split_documents(raw_documents)
#从元数据中移除摘要
fordindocuments:
deld.metadata['summary']
以下代码片段可将嵌入向量导入 Neo4j 实例:
#实例化Neo4j向量
neo4j_vector=Neo4jVector.from_documents(
documents,
OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD
)
要在 Neo4j Aura 中访问和检查嵌入向量,需点击界面上的打开图标,会在浏览器中新开一个标签页。在这个新标签页中,可以查看到块和向量索引的详细信息。我们共有56个块,在系统中被识别为节点。此外,还可以在这个标签页中查看每个块对应的嵌入向量及其具体细节。

向量检索
这段代码片段通过使用 Neo4jVector 对象并进行相似性搜索,帮助检索与查询“Euler 在哪里长大?”相关的前 4 个相关块。这段代码默认采用余弦相似性方法来识别和排序向量之间的相似度。
query="WheredidEulergrowup?"
results=neo4j_vector.similarity_search(query=query,k=4)
print(results)
#检索到的四个文档
#[Document(page_content='==Earlylife==\nLeonhardEulerwasbornon15April1707,inBaseltoPaulIIIEuler,apastoroftheReformedChurch,andMarguerite(néeBrucker),whoseancestorsincludeanumberofwell-knownscholarsintheclassics.Hewastheoldestoffourchildren,havingtwoyoungersisters,AnnaMaria',metadata={'title':'LeonhardEuler','source':'https://en.wikipedia.org/wiki/Leonhard_Euler'}),...]
创建链
我们构建了一个名为final_chain的处理链,旨在高效地处理问题并生成答案。这个链的工作原理是:首先,它接收并传递上下文信息给Neo4jVector retriever,以便从Neo4j数据库中检索相关的向量。随后,链会利用一个OpenAI模型(版本为gpt-4-1106-preview)处理接收到的提示。最终,通过一个解析器对模型的输出进行处理,以提炼出精确的答案。final_chain的设计实现了在特定上下文中对问题的智能处理和答案生成,提高了整个操作的自动化和效率。
prompt=ChatPromptTemplate.from_template(
"""Answerthequestionbasedonlyonthecontextprovided.
Context:{context}
Question:{question}"""
)
#创建一个lambda函数将上下文传递给Neo4jVectorretriever
context_to_retriever=lambdax:x["question"]
#创建链,将上下文赋值给Neo4jVectorretriever
final_chain=(
RunnablePassthrough.assign(context=context_to_retriever,target=lambdax:neo4j_vector)
|prompt
|ChatOpenAI(model="gpt-4-1106-preview")
|StrOutputParser()
)
result=final_chain.invoke({'question':query})
#最终结果
print(result)
# Euler 在瑞士巴塞尔长大。
2 本地部署
如果想在本地的Neo4j Desktop中存储嵌入向量,可以直接在本地环境中运行该应用。操作起来非常简单,只需对凭证信息进行更新,其余的步骤则无需更改。
具体来说,需要分别为数据库和数据库管理系统设置用户名和密码。完成这些设置后,就可以在本地的Neo4j Desktop上顺利地执行应用程序了。
NEO4J_URI="bolt://localhost:7687"
NEO4J_USERNAME="neo4j"
NEO4J_PASSWORD="newpassword"
其余部分与上述相同。
3 总结
总结来说,Neo4j 通过整合其内置的向量搜索功能,显著提升了对检索增强生成(RAG)应用的支持能力。这不仅加强了其在传统结构化数据分析方面的优势,还使其能够更有效地处理非结构化文本数据。本文详细介绍了如何利用Neo4j Aura和Neo4j Desktop来存储向量索引,并在LangChain框架的辅助下,构建出高效的RAG应用。










