1. 训练时词表大小过大,输出层过大,有什么优化方法
本质是在考word2vec中用到的经典词向量优化算法——层次 softmax(hierachical softmax) 和负采样( negative sampling)
来源是word2vec中,由于词库中词的数量V非常大,导致最后在计算softmax时的计算量非常大,因此提出了负采样和层次softmax方法来进行优化这一过程。
这里需要注意的是:负采样和层次softmax是两种独立的优化方法,具体实施时根据问题场景只选用一种方法就可以,基本上没有同时采用这两种方法进行优化的。
下面具体介绍这两种方法。
1)适用场景
负采样适用的场景是结果中正例比较少而负例比较多的情形。
如word2vec,无论是CBOW模式还是skip-gram模型,整个词库词语数量为V,CBOW预测中间词,输出中只有中间词为1,其余词都为0;
skip-gram预测周围词,只有周围有限的n个词为1,其余都为0;
这两种模式下都是正例数很少,而负例数很多的情形。
2)算法原理
在上述实际情况下,负采样的思想就是取所有正样本和部分负样本,比如按照1比10的比例选取负样本,然后整个预测输出的规模就变小了,这样再去计算softmax的时候计算量就很小了。
使用过程中,一个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
1)重温sigmod函数和softmax函数的区别
sigmoid函数
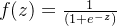
sigmod函数接收一个数值类型的输入值z,输出为一个0-1的值,所以sigmoid函数被用来进行二分类,输出大于0.5的为正例,小于0.5的为反例。
softmax函数
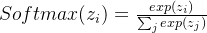
softmax计算的是某一项zj在所有可能的结果中出现的概率,一般类别大于2,分母的计算要用到所有类别项。
softmax函数常被用来进行多分类,计算每一个或某一个类别出现的概率。另外softmax可以由多个sigmod函数组合达到同样的效果,即二分类一直切分达到多分类的效果。
2)算法原理
层次softmax名字里带着个softmax,其实跟softmax几乎没啥关系了。利用的就是前面提到的,用多个sigmoid函数,进行多次二分类以达到多分类的效果。
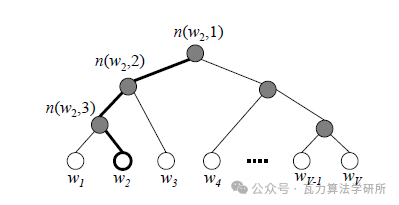
层次softmax首先利用树结构的叶节点表示词库中的每一个词,从根节点到叶节点的路径,每一个中间路径都对应着一个概率,某个词出现的概率的计算方式改为路径上所有中间路径概率的乘积,那么现在有一个问题就是中间路径的概率是怎么得到的,其实它们正是要学习的参数,但是它们是怎么表示的呢?
我们先看一下原本计算每个词出现的概率应该怎么算:
有一个或多个1* V的one-hot向量,经过输入层 V*D 的矩阵(CBOW模式多个输入取平均)变为 1*D ,再经过隐层(D*V)得到(1*V)的输出,再经softmax计算出各个词出现的概率;
改为层次softmax后:
输入 1*V 的one-hot向量,经 V*D 的矩阵得到 1*D ,然后就要改变了,每一个中间路节点(上图中实心球)对应一个向量,该向量的形状为(D,1),然后上面得到的 1*D 的向量与中间路径向量相乘,得到一个数值z,z输入到sigmoid函数得到一个0-1的数值,就是该节点到下一节点向左(或向右)的概率,另外一侧概率是1-sigmod(z),这样就得到了中间路径的概率。
前面说到,叶子节点(某个词)的概率就是从根节点到叶子节点中间路径概率的乘积;
同时层次softmax的目标函数也做出了改变,它的目标函数变为最大化目标词的路径概率,就是只关注目标词所在路径的概率,其他路径不再关注,也无需计算,这是层次softmax优化计算量的关键。
层次化softmax的树是二叉树,要学习的参数是中间节点向量,目标函数的计算只关注目标词的路径,计算复杂度只和路径长度有关,路径长度也就是树的高度,假设是满二叉树,则树高=V取2为底的对数值,远远小于V,另外还可以进一步优化,表示词语的树结构采用赫夫曼树,词频高的词语出现在最前面。路径最短,词频低的词语路径较长,这样在实际中可以进一步减少整体的计算量。赫夫曼树的相关知识不在本文讨论范围内,可自行了解。
总结一下,Hierarchical softmax通过构造一棵二叉树将目标概率的计算复杂度从最初的V降低到了logV的量级。但是也缺点是增加了词与词之间的耦合性;比如一个word出现的条件概率的变化会影响到其路径上所有非叶子节点的概率变化。间接地对其他word出现的条件概率带来影响。










