|
今天最大的瓜莫过于:斯坦福 Llama3-V PK清华 MiniCPM-Llama3-V-2.5,详细证据: https://github.com/OpenBMB/MiniCPM-V/issues/196 吃瓜之余,来看一下多模态大模型架构演变! 一篇优秀的论文综述了多模态AI架构——包含了一个全面的分类法和对任意到任意模态模型发展的分析。 ? 综合分类法:首次明确识别并分类四种广泛的多模态架构类型(A型、B型、C型、D型),有助于简化对模型架构的理解和选择。? 比较分析:对每种架构类型的优势和劣势进行了详细审查,考虑了训练数据、计算需求、可扩展性和模态整合。? 任意到任意模态模型:突出了构建任意到任意模态模型所涉及的主要架构类型,有助于模型的选择和发展。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;display: table;border-bottom: 1px solid rgb(248, 57, 41);">综合分类法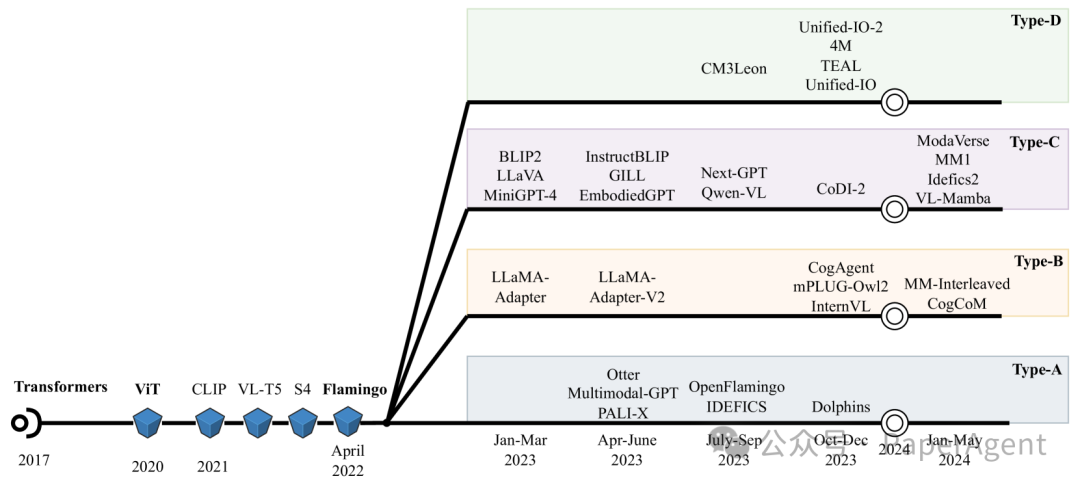
多模态模型架构的分类。四种不同类型的多模态架构及其子类型被概述。各种模型被系统地分类到类型和子类型中。深度融合:类型A和类型B在模型的内部层融合多模态输入。早期融合:类型C和类型D在输入阶段促进融合。类型A使用标准的交叉注意力机制,而类型B则利用定制设计的交叉注意力或专门的层。类型C是一种非标记化的多模态模型架构,而类型D则采用输入标记化(离散标记)。SCDF:基于标准交叉注意力的深度融合。CLDF:基于定制层的深度融合。NTEF:非标记化的早期融合。TEF:标记化的早期融合。 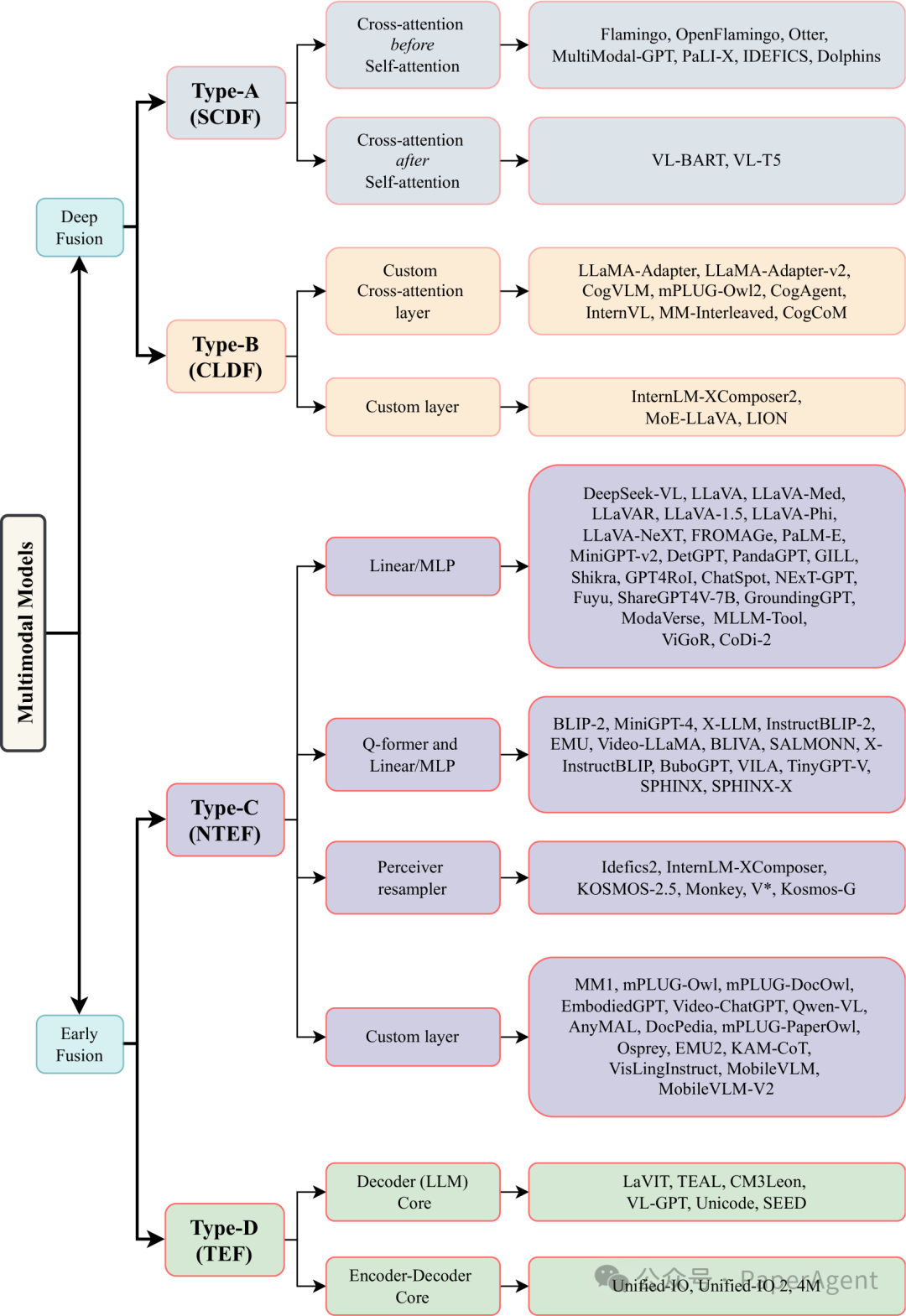
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;display: table;border-bottom: 1px solid rgb(248, 57, 41);">比较分析- Type-A (SCDF:Standard Cross-Attention based Deep Fusion) - 标准交叉注意力深度融合:使用标准的交叉注意力层在模型的内部层进行多模态输入的深度融合。这种类型可能在自注意力层之前或之后添加交叉注意力层。
类型A多模态模型架构。输入模态通过使用标准交叉注意力层深入融合到LLM的内部层。交叉注意力可以添加在自注意力层之前或之后。模态特定的编码器处理不同的输入模态。使用重采样器来输出固定数量的模态(视觉/音频/视频)标记,给定输入时变量数量的输入标记。类型B多模态模型架构。输入模态通过使用定制设计的层深入融合到LLM的内部层。定制交叉注意力层或其他定制层用于模态融合。线性层/多层感知器/Q-former被用来将不同模态与解码层对齐。类型C多模态模型架构。(非标记化的)输入模态直接输入到模型的输入端,而不是其内部层,从而实现早期融合。不同类型的模块被用来将模态编码器的输出连接到LLM(模型),例如线性层/多层感知器、Q-former和线性层/多层感知器、Perceiver重采样器、定制的可学习层。类型D多模态模型架构。标记化的输入模态直接输入到模型的输入端。在这个架构中,使用仅解码器变换器或编码器-解码器风格的变换器作为多模态变换器。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;display: table;border-bottom: 1px solid rgb(248, 57, 41);">任意到任意模态模型任意到任意多模态模型的发展时间线。从单一模态模型(左侧)到任意到任意模态模型(右侧)的演变过程被描绘出来。图中注明了属于C型和D型的任意到任意多模态模型。底部的绿线展示了非基于变换器的模型(如SSM,状态空间模型)的另一条发展时间线。Mamba是一个语言模型。VL-mamba和Cobra是视觉-语言模型。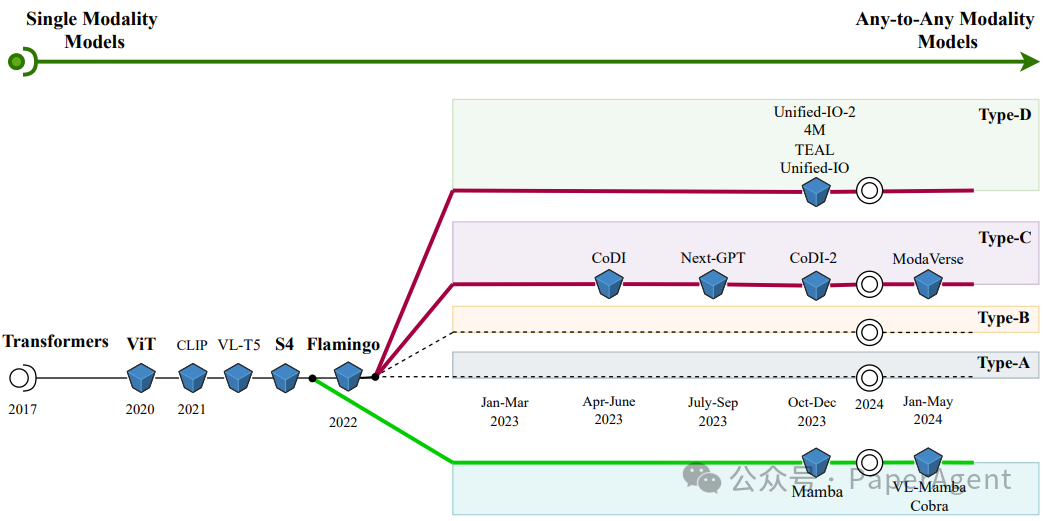
https://arxiv.org/pdf/2405.17927TheEvolutionofMultimodalModelArchitectures | 









