|
近期,Qwen2系列模型家族发布了系列GGUF格式模型。通过llama.cpp/Ollama等生态的发展,很多大语言模型都支持GGUF格式,极大地简化了大语言模型的应用流程,让即便是模型领域的初学者,只有一台CPU笔记本,也能轻松上手顶尖的AI技术。我们希望分析GGUF模型的使用方式,并逐一介绍当下主流的生态系统工具(llama.cpp,Ollama, lmstudio, Open-Webui),从下载、解析到部署运行,全方位解锁GGUF模型的便捷玩法,帮助开发者丝滑的体验最新的大模型技术。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;">
GGUF通常可以通过单模型文件完成推理,魔搭社区可以通过命令行CLI,Python SDK,页面下载等多个方式下载单个模型。
命令行CLI下载使用ModelScope命令行工具下载单个模型,以Qwen2-7B的GGUF格式为例:
modelscopedownload--model=qwen/Qwen2-7B-Instruct-GGUF--local_dir.qwen2-7b-instruct-q8_0.gguf
PythonSDK下载
from modelscope.hub.file_download import model_file_download
model_dir=model_file_download(model_id='qwen/Qwen2-7B-Instruct-GGUF',file_path='qwen2-7b-instruct-q8_0.gguf')
页面下载 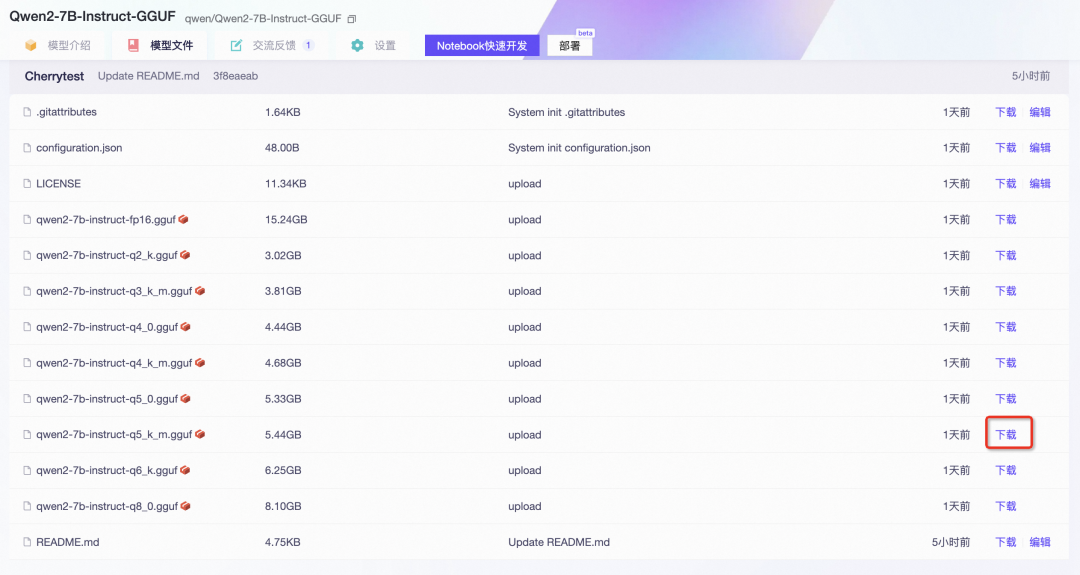
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;">
本文主要介绍llama.cpp, ollama,LM Studio三个工具,以下是比较不同工具的总结图。我根据自己的快速主观体验做了一些星级评定——希望这对您的比较有所帮助。
| UI | 文件上传(RAG) | 命令行 | 页面友好度 | 安装友好度 | 是否开源 | llama.cpp | 支持 | 不支持 | 支持 | 
| 友好 | 是 | Ollama | 需要额外安装Open-WebUI | Open-WebUI支持 | 支持 |
| 命令行友好/WebUI一般 | 是 | LMStudio | 支持 | 不支持 | 支持 |
| 非常友好 | 否 |
llama.cpp环境安装
git clone https://github.com/ggerganov/llama.cpp.gitcd llama.cppmake -j# GPU机型需要cuda加速推理build# make -j LLAMA_CUDA=1
模型推理 要运行 Qwen2,您可以使用 llama-cli(主程序)或 llama-server(主程序)。建议使用 llama-server,因为它简单且与 OpenAI API 兼容。例如:
./llama-server-m/mnt/workspace/qwen2-7b-instruct-q8_0.gguf-ngl28-fa 更多参数说明可参照官方文档:https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md
接口调用然后就可以很容易地使用 OpenAI API 访问已部署的服务: import openai
client = openai.OpenAI(base_url="http://127.0.0.1:8080/v1",api_key = "sk-no-key-required")
completion = client.chat.completions.create(model="qwen", # model name can be chosen arbitrarilymessages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "tell me something about michael jordan"}])print(completion.choices[0].message.content)
CLI调用使用 llama-cli,ChatML 模板中-cml 已被删除。改用--in-prefix 和--in-suffix 来解决此问题。 ./llama-cli-mqwen2-7b-instruct-q5_k_m.gguf\-n512-co-i-if-fprompts/chat-with-qwen.txt\--in-prefix"<|im_start|>user\n"\--in-suffix"<|im_end|>\n<|im_start|>assistant\n"\-ngl24-fa
Webui访问在浏览器中输入:http://127.0.0.1:8080 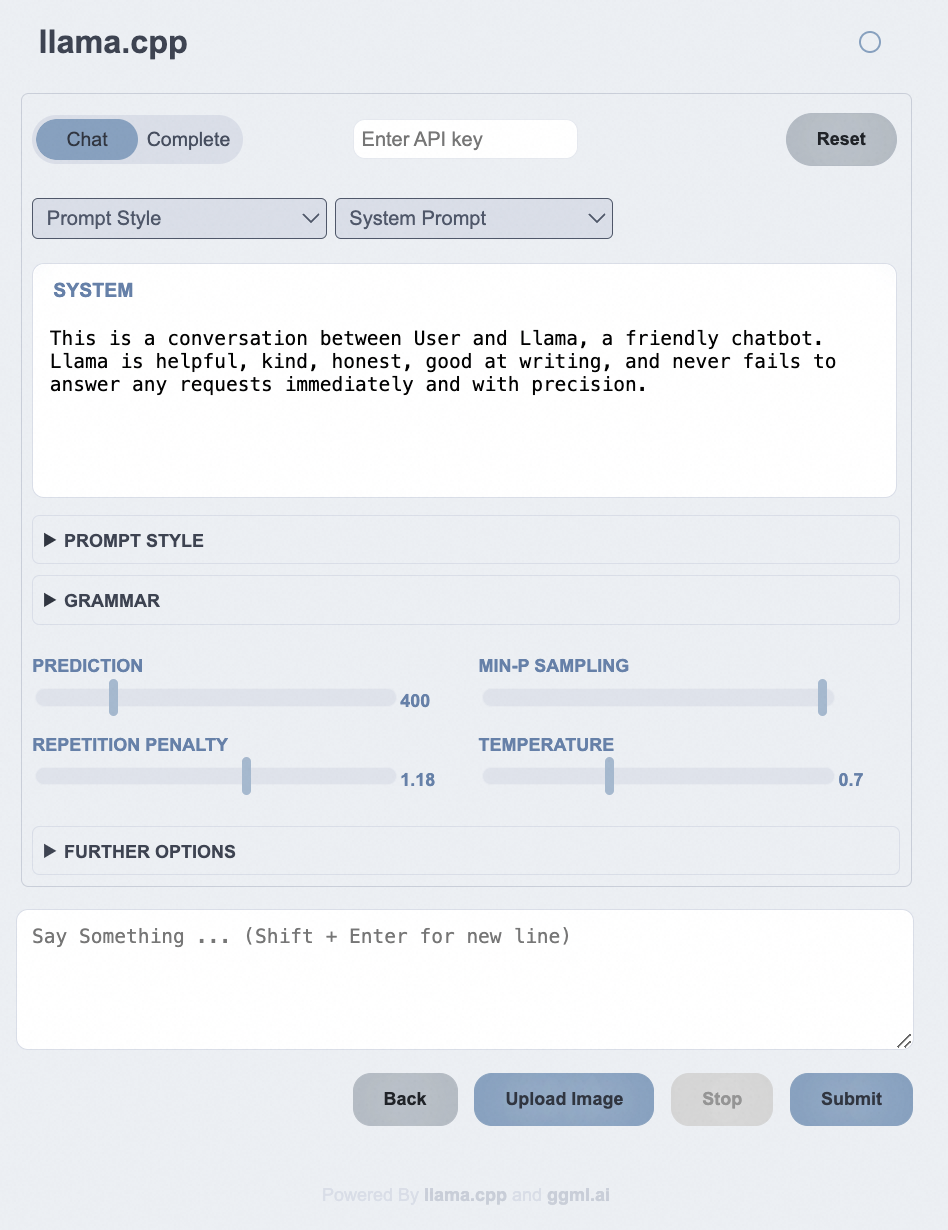
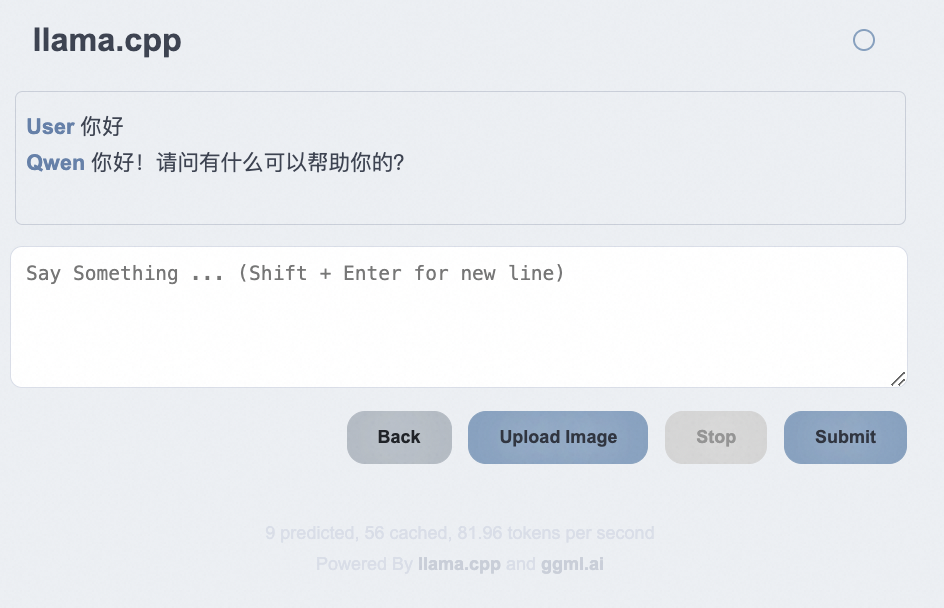
OllamaOllama 是一款极其简单的基于命令行的工具,用于运行 LLM。它非常容易上手,可用于构建 AI 应用程序。
本文使用Ollama Modelfile,结合魔搭ModelScope社区CLI模型下载,并分别在魔搭Notebook环境和Mac环境几行代码轻松体验大语言模型。
Linux环境使用Liunx用户可使用魔搭镜像环境安装【推荐】 gitclonehttps://www.modelscope.cn/modelscope/ollama-linux.gitcdollama-linuxsudochmod777./ollama-modelscope-install.sh./ollama-modelscope-install.sh
启动Ollama服务
创建ModelFile复制模型路径,创建名为“ModelFile”的meta文件,内容如下: FROM /mnt/workspace/qwen2-7b-instruct-q8_0.gguf
# set the temperature to 0.7 [higher is more creative, lower is more coherent]PARAMETER temperature 0.7PARAMETER top_p 0.8PARAMETER repeat_penalty 1.05TEMPLATE """{{ if and .First .System }}<|im_start|>system{{ .System }}<|im_end|>{{ end }}<|im_start|>user{{ .Prompt }}<|im_end|><|im_start|>assistant{{ .Response }}"""# set the system messageSYSTEM """You are a helpful assistant."""
创建自定义模型使用ollamacreate命令创建自定义模型 ollamacreatemyqwen2--file./ModelFile
通过使用 ollama list 列出可用模型来验证自定义模型的创建。 
运行模型:
测试自定义模型,使用终端与您的自定义模型聊天,以确保其行为符合预期。验证它是否根据自定义的系统提示和模板做出响应。 
显存占用: 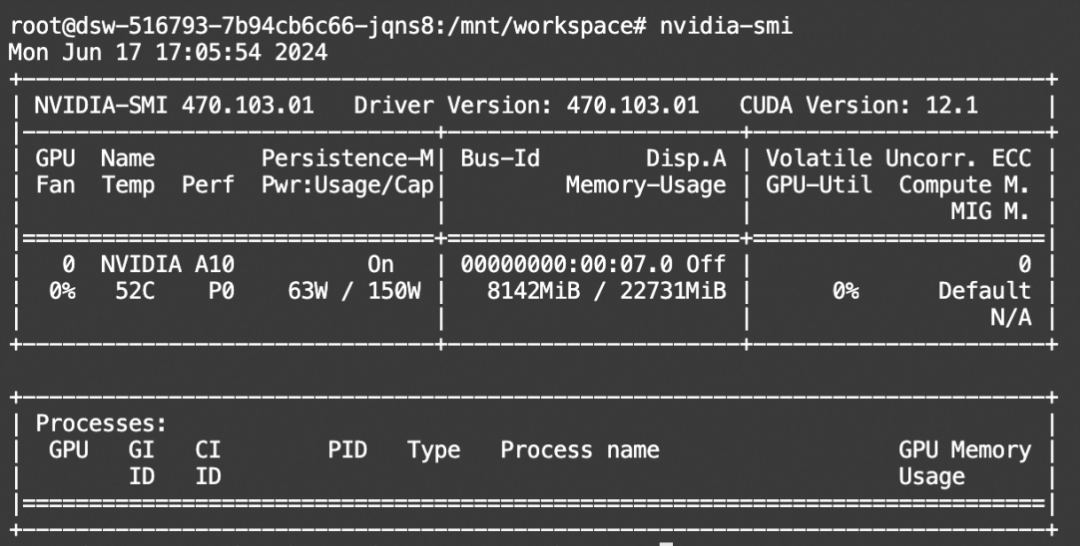
Mac环境安装在官网下载Mac安装包,并解压安装,启动Ollama服务 
模型下载并使用Ollama创建推理下载和创建推理和上文一致,我们在Mac上创建一个myqwen2的模型并通过Ollama运行。
本地安装OpenWebUI并体验环境要求:condacreate--namewebuipython=3.11condaactivatewebuicondaconfig--addchannelsconda-forgecondainstallnodejs
下载安装open-webui并运行 git clone https://github.com/open-webui/open-webui.gitcd open-webui/
# Copying required .env filecp -RPp .env.example .env
# Building Frontend Using Nodenpm inpm run build
# Serving Frontend with the Backendcd ./backendpip install -r requirements.txt -Ubash start.sh
打开本地运行的webUI地址0.0.0.0:8080就可以体验啦! 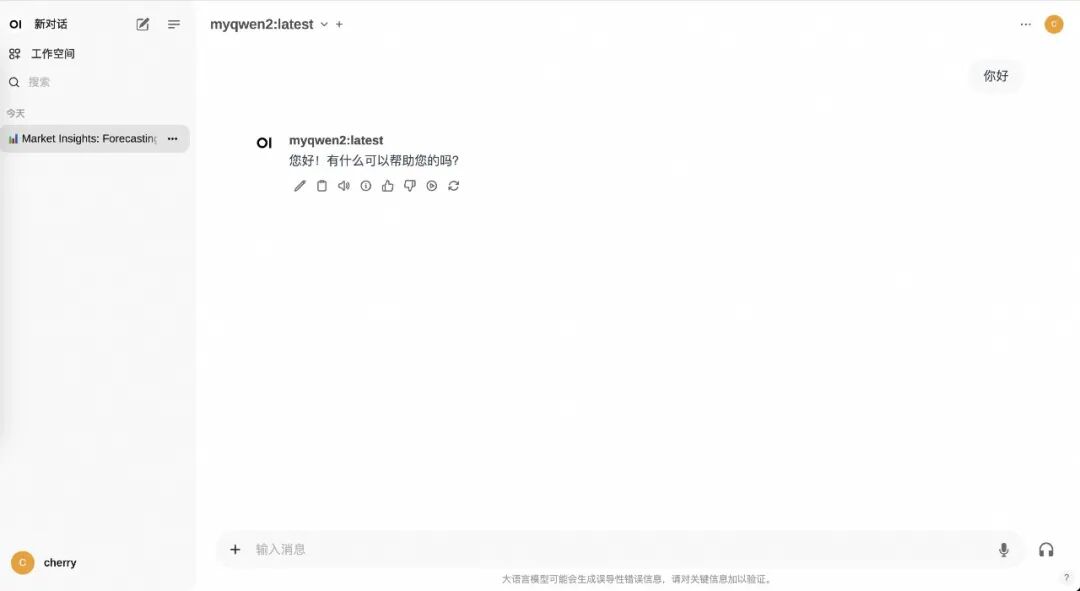
LMStudioLM Studio 有一个不错的 GUI,可用于与 LLM 交互。LM Studio是唯一一个非开源的项目,但可以免费下载。
下载链接: https://lmstudio.ai/
模型gguf文件在魔搭社区下载的时候,设置保存路径为:~/.cache/lm-studio/models/Publisher/Repository/,就可以被LMStudio加载。
对话UI 如下所示: 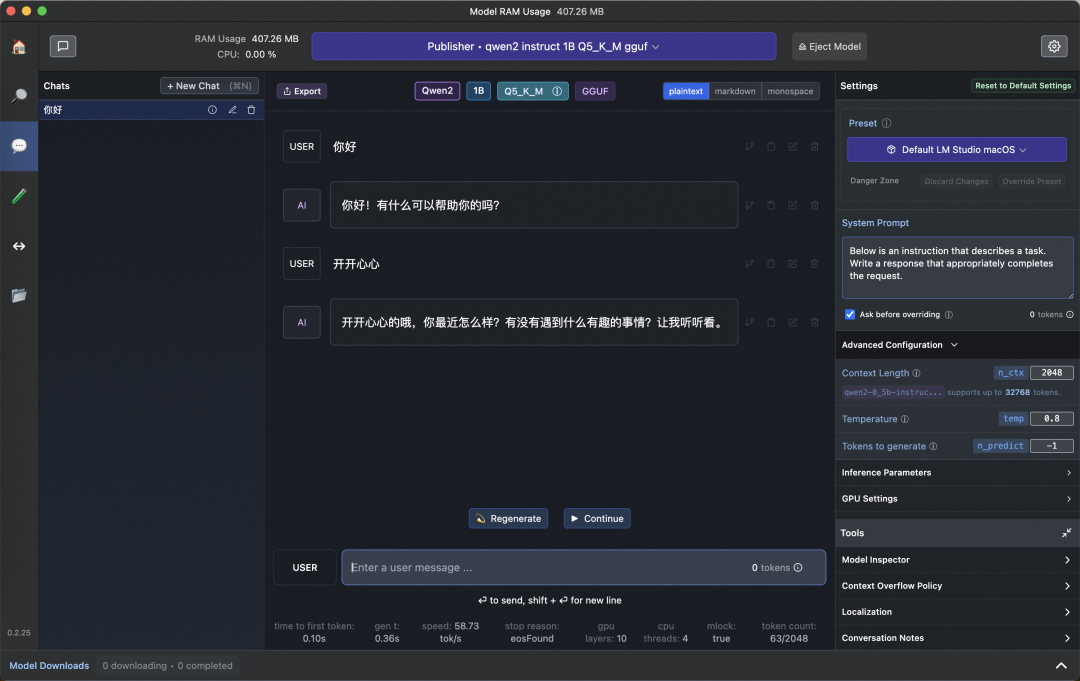
模型管理界面: 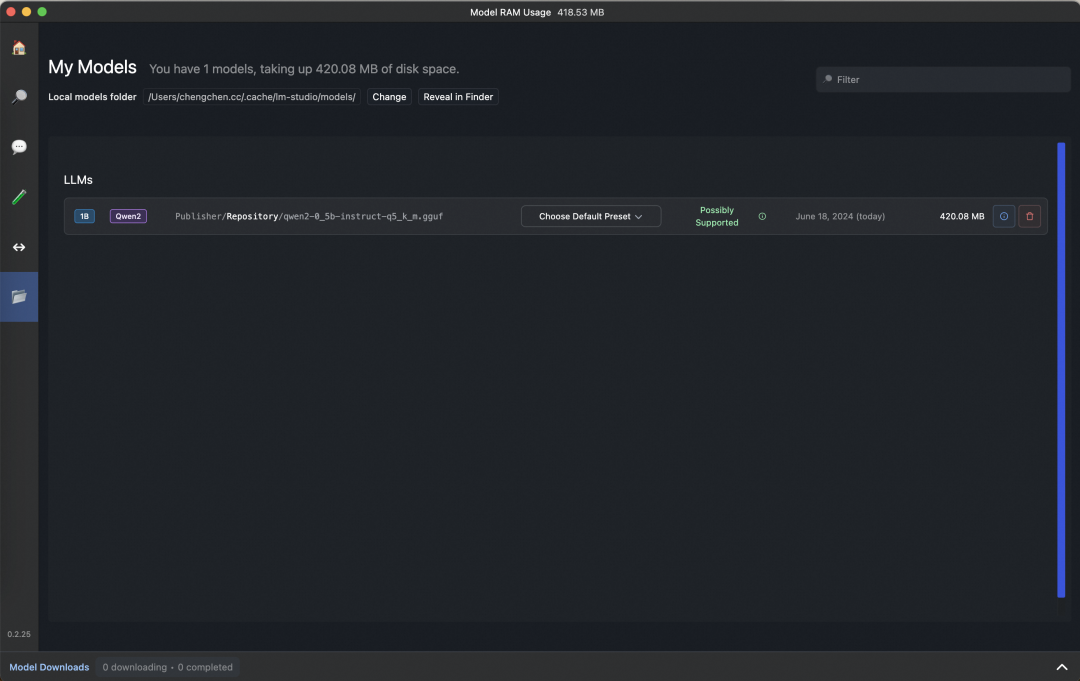
LMStudio包括Open-Webui,Llama.cppUI还在底部显示了token生成速度,在M1芯片上,0.5B的Qwen2这个模型速度是58.73tok/s | 









