ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;background-color: rgb(255, 255, 255);visibility: visible;line-height: 1.6em;margin-bottom: 24px;margin-left: 8px;margin-right: 8px;">上周,PingCAP AI Lab 数据科学家孙逸神的文章《当前都在堆长窗口,还需要 RAG 吗?》从用户的角度谈了长窗口 & RAG 的看法,引起了众多同行的围观。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;background-color: rgb(255, 255, 255);visibility: visible;line-height: 1.6em;margin-bottom: 24px;margin-left: 8px;margin-right: 8px;">本周我们采访了张粲宇,看看搞向量数据库的业内人士,是怎么看待这个问题的?
作者简介 张粲宇,Zilliz Senior Product Manager。Milvus 产品负责人,主导向量数据库 Milvus 关键特性的定义与产品路线图的规划,Ask AI 项目负责人。 Ask AI,一个基于 RAG 技术搭建的企业级产品文档问答机器人。
ingFang SC", "Helvetica Neue", "Microsoft YaHei UI", "Microsoft YaHei", "Noto Sans CJK SC", Sathu, EucrosiaUPC, Arial, Helvetica, sans-serif;letter-spacing: 0.034em;">01 探索大模型的打开方式:RAG 与长文本
随着 GPT-4o 与 Astra 在 Google IO 大会上的发布,生成式人工智能(AIGC)的进程再次加速。在大模型的多模态能力与效果百花齐放的同时,性价比已然成为各大模型公司竞争的主要策略。 经过这一年多的狂飙,相较于过去简单粗暴地依赖 Scaling Law 无视成本地堆积算力,现在 AIGC 的发展更加贴近实际应用,使用场景也逐渐明晰。人们开始以更务实和落地的视角来探索大模型的正确使用方式。 在众多大模型的打开方式中,检索增强生成技术(Retrieval-Augmented Generation,简称 RAG)受到广泛关注,并被应用在许多实际场景中,如知识库问答、学习助手、情感陪伴机器人等。 一个典型的 RAG 框架由检索器(Retriever)和生成器(Generator)两部分组成。在检索之前,需要对原始数据进行预处理,包括为数据(如 Documents)进行切分、嵌入向量(Embedding)并构建索引(Chunks Vectors)。 在检索阶段,通过向量检索以召回相关结果,而在生成阶段则利用基于检索结果(Context)增强的 Prompt 来激活 LLM 以生成回答(Result)。 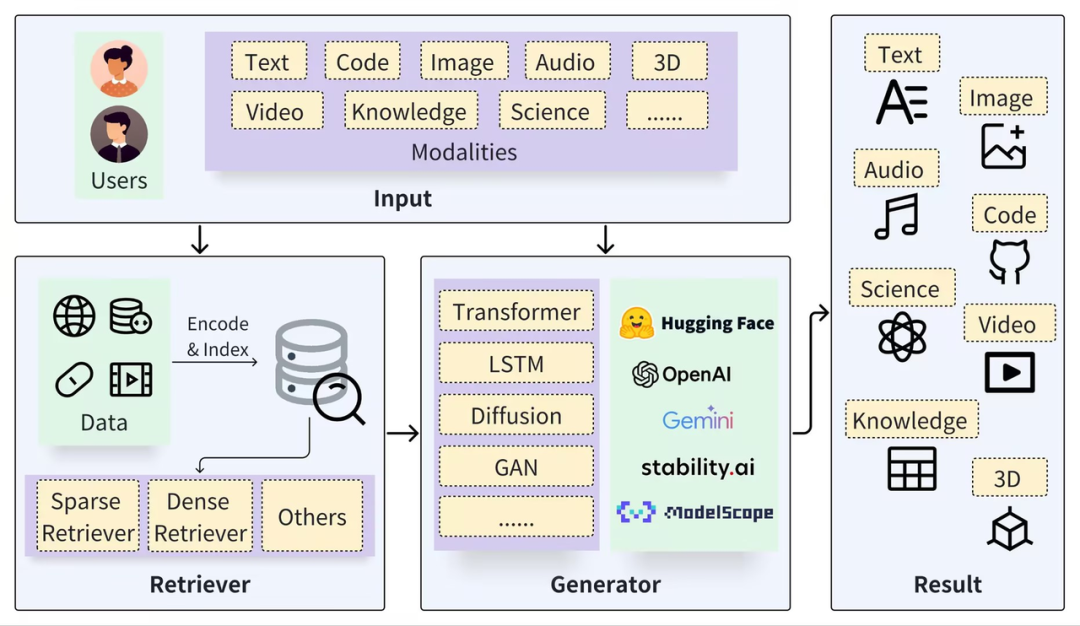
https://arxiv.org/pdf/2402.19473 RAG 技术的关键在于其结合了检索系统与生成模型的优点:检索系统能提供具体、相关的事实和数据,而生成模型则能够灵活地构建回答,并融入更广泛的语境和信息。 这是一种典型取的取长补短、解耦分治的思想。这种结合使得 RAG 模型在处理复杂的查询和生成信息丰富的回答方面表现出强大的能力,因此 RAG 在问答系统、对话系统和其他需要理解和生成自然语言的应用中极具价值。 相较于原生的大型模型,RAG 提供了以下天然的优势: - 减轻 “幻觉” 问题:RAG 通过检索外部信息作为输入,辅助大型模型回答问题,这种方法能显著减少生成信息不准确的问题,同时增加回答的可追溯性。
- 数据隐私和安全:RAG 可以将知识库作为外挂数据库来管理企业或机构的私有数据资产,避免数据在模型学习后以不可控的方式泄露。
- 信息的实时性:RAG 允许从外部数据源实时检索信息,因此可以获取最新的、领域特定的知识,解决知识时效性问题。
同时,随着大模型技术的不断迭代,长上下文技术(Long-Context,简称长文本)能帮助大模型在每轮对话中处理更多上下文和背景知识,从而生成更佳的回答。随着上下文窗口长度的增加,模型可以获取更丰富的语义信息,有助于降低大型语言模型的错误率和产生 "幻觉" 的可能性,从而提高用户体验。正因为此,长文本能力在近一年的时间里一路狂飚,OpenAI 从最初 GPT-3.5 的 4k token 增加到 GPT-4 Turbo 的 128k,OpenAI 的最强竞争对手 Anthropic 发布的 Claude 3 Opus 一次性将上下文长度提高到了 100 万 token,谷歌宣布今年晚些时候将模型的现有上下文窗口再增加一倍,达到 200 万 token。这将使其能够同时处理 2 小时的视频、22 小时的音频、超过 60,000 行代码或超过 140 万个单词。这意味着它几乎可以一次性读完任何一本长篇小说,理解并梳理小说脉络,并且可以做到针对具体问题 “大海捞针” 般神奇地找到细节片段和相关描述。业界人士普遍认为,上下文长度的增加对模型能力的提升具有重大意义。正如 OpenAI 的开发者关系主管 Logan Kilpatrick 所说,“上下文就是一切,是唯一重要的事”。提供充足的上下文信息是获取有意义回答的关键。随着大模型公司对长文本技术的竞争加剧,上下文窗口的上限也在不断被挑战和突破。这种突破让人们看到了全新的信息检索的可能性。因此,有人提出了一个问题:随着大模型长文本能力的进步,如果长文本能够完全替代 RAG,那么 RAG 是否还有存在的必要呢?对此,我的个人观点是,长文本模型并不能取代 RAG,两者将共同进步、互补发展。在 AI 时代,它们将协同工作,帮助人们更加有效地管理以及利用数据和知识。
ingFang SC", "Helvetica Neue", "Microsoft YaHei UI", "Microsoft YaHei", "Noto Sans CJK SC", Sathu, EucrosiaUPC, Arial, Helvetica, sans-serif;font-weight: 600;min-height: 1rem;border-width: initial;border-style: none;border-color: initial;text-align: justify;line-height: 1.6em;">02 长文本为何无法取代 RAG?长文本在一些简单任务上(如读一篇研报、总结一篇论文等)确实可以很好满足需求且能提供更简单的使用体验,然而在更复杂的 toC 和 toB 端使用场景下长文本无法取代 RAG。长文本无法取代 RAG 的原因主要有两方面:一个是从原理推导出的物理限制,另一个则是实际场景中会面临的各类挑战。在分布式系统领域有着著名的 CAP 定理,即一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)三个基本保证无法同时得到满足。而在长文本方面,同样也存在文本长度、注意力和算力的 “不可能三角”,这表现为:文本越长,越难聚集充分注意力,难以完整消化;而在注意力限制下,短文本无法完整解读复杂信息;而要精准地处理长文本需要大量算力,进而提高成本。在实际应用中,大模型的调用成本和上下文文本长度的平方成正比,其计算代价和响应延迟都会受到上下文的影响。在保证精度不丢失的前提下,使用超长文本作为上下文输入的消耗是巨大的,因此实际应用中很难找到能承受如此高代价的应用进行大规模落地。即便抛开成本和响应延时不谈,若要直接把长文本应用到实际场景中,依旧会遇到诸多方面的限制和问题。- 首先,在可扩展性方面,即使是以业内翘楚 Google Gemini 的数百万 token,在大型企业和互联网的大数据面前也显得微不足道。关于大模型的记忆结构,一个简单的类比是:大模型的参数是寄存器,长文本是内存,而 RAG 则是硬盘。无论内存有多大,终究无法一次性装下整个世界的数据。因此在扩展性方面,不是长文本不好用,而是 RAG 更具有性价比。
- 其次,数据的管控和安全性也是 RAG 系统的优势。长文本可以很好地理解知识,但管理和维护知识的能力却相对较弱。例如,在企业对部分规章或制度做了变更的情况下,这在 RAG 系统里可以只是少量数据的部分更新,但在长文本里却需要重新开始。这就体现了在信息更新和修改灵活度上的差异。再举一个具体的例子,企业不同角色的员工应该有不同的访问权限。例如,薪酬专员可以访问各部门员工薪资,而其他员工则不能,这里的身份验证和权限管理是 RAG 数据管理系统的强项,而大模型的 prompt 目前很难做到精确的权限管理。此外,通过 RAG 企业可以在本地管理和控制自己的数据,同时利用外部的推理模型进行查询和生成,解耦的系统结构可以更好的确保数据安全性。
- 此外,在可解释性方面,长文本的 “黑盒” 模型使得调优很难下手。而在医疗、金融、法律等高风险领域,AI 系统的溯源性至关重要。RAG 的分阶段模型可以提供清晰的推理链条,每个阶段的结果都可以审核、分析、调试,在必要情况下可以引入人工干预,这种人机协同既可以弥补算法的不足,消除幻觉提升答案质量,又有助于发现数据问题并进行及时纠正和后续处理,这对许多严肃场景是更为系统的解法。
因此,在更通用的场景下,RAG 依然是一个稳定、可靠且性价比高的选择。实际上,在综合考虑成本、效果、安全性等诸多方面因素后,大量 AIGC 应用也还是采用 RAG 的方式来构建服务的,这里也包括我们自家产品Milvus 官方文档站的Ask AI就是基于 RAG 来构建的,欢迎大家试用看看效果。ingFang SC", "Helvetica Neue", "Microsoft YaHei UI", "Microsoft YaHei", "Noto Sans CJK SC", Sathu, EucrosiaUPC, Arial, Helvetica, sans-serif;font-weight: 600;min-height: 1rem;border-width: initial;border-style: none;border-color: initial;text-align: justify;line-height: 1.6em;">03 展望未来:相得益彰的 RAG 与长文本从上述的分析来看,在信息检索领域长文本并不能完全取代 RAG,也不应该直接替代。我们需要根据实际需求和条件,选择最合适的工具和方法。展望未来,长文本和 RAG 其实都还有很多工作可以做。长文本的未来会向着更长、更快、更便宜的方向发展。随着技术的进步,长文本将能够处理更长的上下文,这将使 AI 能够理解更复杂的对话和问题,生成更长和更深入的文本。在这个过程中,性价比的优化方案也将成为重要的研究方向。如何通过更先进的算法和硬件创新来保证模型性能的同时,降低长文本的计算成本,这将是长文本被更广泛应用,在各种场景中发挥更大作用的关键。而RAG 的发展方向则是:更准确、更体系、信息密度更高。由于RAG 的检索准确率是保证回答质量的基石,因此检索一定是朝着更精准的方向探索,业界对于更高级的混合检索等技术手段都还在积极探索。此外,RAG 的发展也将更加注重知识结构的优化。例如,我们可以利用层次结构和图结构来组织和管理知识,使得信息检索和生成更为准确和高效。同时,通过一些前沿的技术手段如知识蒸馏,我们可以将大量重复了冗余的信息浓缩成知识进行管理,因此更高效的处理检索问题。同时,长文本模型和 RAG 模型的结合将成为一种可能的发展趋势。长文本决定了大模型能处理的窗口长度即信息数量,而 RAG 则帮助优化了和大模型交互的信息质量,这两者的有机结合才是大模型在未来正确的打开方式。 |










