ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;">1.ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;visibility: visible;">面向实际场景的实现逻辑 GraphRAG不仅提供了一种强大的文本分析工具,而且通过其知识模型和工作流程的灵活性和可配置性,能够适应不同的应用场景和用户需求。GraphRAG知识模型和默认配置工作流程可以总结为以下几个核心逻辑步骤,以实现文本数据的高效处理和知识提取: ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;letter-spacing: 0.5px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">索引数据流图形化知识模型(GraphRAG Knowledge Model)默认配置工作流程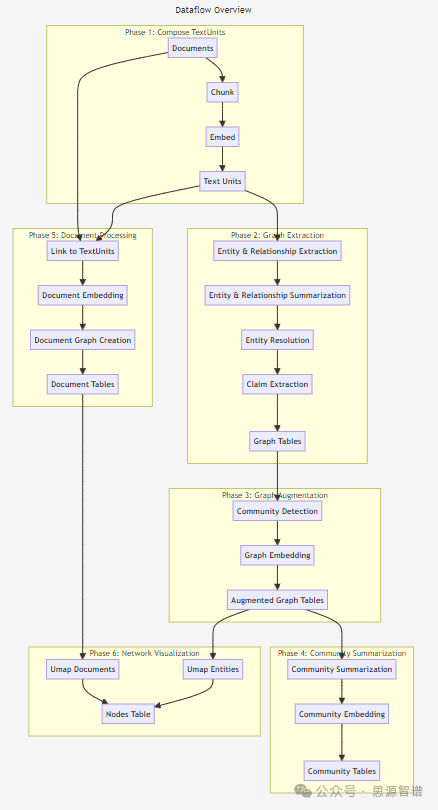
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;visibility: visible;">2.阶段详解第1阶段:组合文本单元(Compose TextUnits)第2阶段:图形提取(Graph Extraction)第3阶段:图形增强(Graph Augmentation)第4阶段:社区总结(Community Summarization)第5阶段:文档处理(Document Processing)第6阶段:网络可视化(Network Visualization)
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;visibility: visible;">3.总结
Graph RAG的知识模型和工作流程提供了一种系统化的方法来处理和分析文本数据,提取知识,并以图形化的方式展示数据关系,为文本密集型领域提供了一种强大的知识提取和分析工具。结构化解决方案流程简述如下: 文本分割: 接收原始文本数据,执行预处理和文本单元化。 知识提取: 通过LLM自动提取实体和关系,提取并评估文本中的声明,确保知识真实性。 图形增强: 应用社区检测和图形嵌入技术,增强对数据结构的理解。 社区分析: 生成社区报告,提供高层次的图形理解。 文档整合: 构建文档表,链接文本单元,整合文档信息。 网络可视化: 应用UMAP等降维技术,实现数据的二维图形展示。
| 









