|
RAG的评估是比较难的,目前一般有以下几种评估方式: 人工评估:使用多人评估进行投票通常是最准的,但这种方式在实际工作中成本过高,效率非常低,基本上不具备可操作性 使用LLM出现前的BLEU、ROUGE等指标评估:这种方式需要参考答案,较少考虑语义,目前在RAG的评估中比较少用 使用RAGAS评估:这种方式是在论文RAGAS:Automated Evaluation of Retrieval Augmented Generation中提出的自动化测评方法,这种方式不需要参考答案,基本上是目前RAG评估的主流方法 使用GPT-4进行打分:这种方法虽然有争议,但实际应用中,只要Prompt优化几轮,与人工评估的一致性还是比较高的,这种方式需要参考答案 使用语义相似度+关键词进行加权打分:这种方式一般应用在竞赛中,实际企业级文档问答开发中较少使用,因为需要有正确答案,而且答案需要有关键词列表
通常的认知是,自动化评估精度并不高,在吴恩达的DeepLearning.AI网站中的Building and Evaluating Advanced RAG课程提到,目前自动化测评,总体与人工测评的一致性,只有80%多,这个指标供大家参考,但实际情况下一般不会这么低,一方面是这个课程是23年大语言模型总体上还没现在这么强的时候出的,另一方面是,课程中介绍的方法(也是本文要介绍的方法)没有参考答案,而实际工作中一般是会准备参考答案的,在有参考答案的情况下,自动化评估与人工评估的一致性,还是容易达到比较高的水平的 本文所要介绍的方法,借助TruLens库,评估三个指标,TruLens称之为RAG三元组(RAG triad),由三个评估指标组成:上下文相关性(Context Relevance)、依据性(Groundedness)和答案相关性(Answer Relevance)。如下图所示。这三个评估指标,可以看做是RAGAS的子集,我们后面会有文章介绍如何使用RAGAS进行评估。 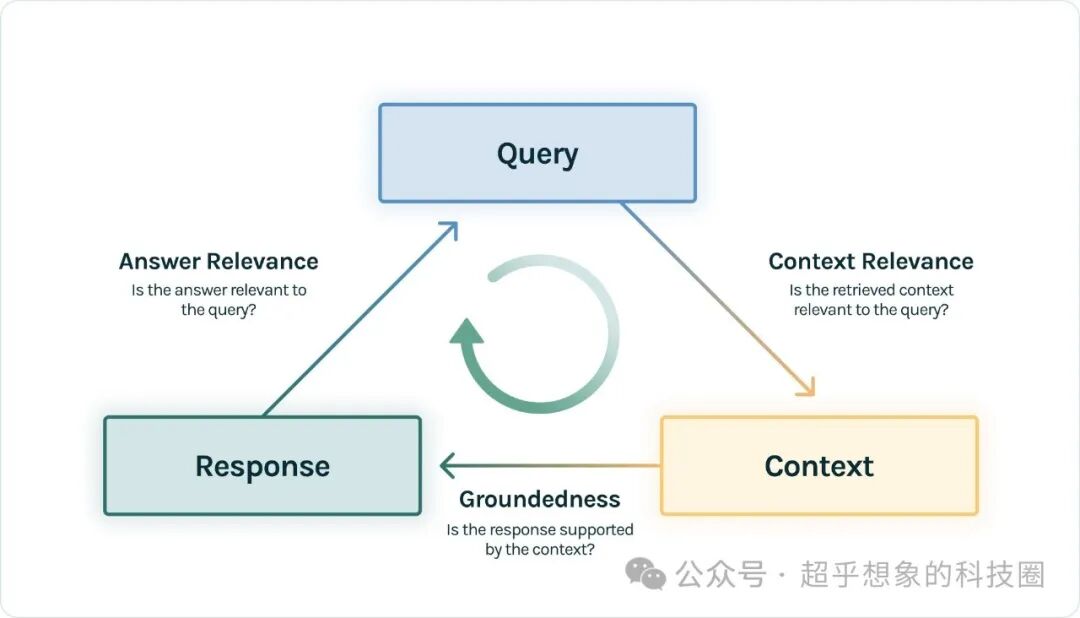
(https://www.trulens.org/trulens_eval/getting_started/core_concepts/rag_triad/)
上下文相关性(Context Relevance):任何RAG应用程序的第一步是信息检索;为了验证检索的质量,需要确保每个上下文片段与输入查询密切相关。这一点至关重要,因为LLM将使用这些上下文来形成答案,因此任何不相关的信息都可能导致幻觉。TruLens通过使用序列化记录的结构来评估上下文的相关性 依据性(Groundedness):检索到上下文之后,LLM将其形成答案。LLM经常会偏离提供的事实,夸大或扩展成听起来正确的回答。为了验证RAG的依据性,可以将回答分解成单独的陈述,并在检索到的上下文中独立寻找支持每个陈述的证据 答案相关性(Answer Relevance):回答仍然需要帮助解决原始问题,可以通过评估最终回答与用户输入的相关性来验证这一点
TruLens默认使用OpenAI的模型作为打分模型,本文提供了更多的选项,可以使用OpenAI兼容的LLM,例如千问,也可以使用Ollama提供的模型 本文代码已开源,地址在:https://github.com/Steven-Luo/MasteringRAG/blob/main/evaluation/01_trulens_evaluation.ipynb 首先访问Ollama官方网站,下载对应操作系统的版本,并安装,接下来下载模型,这个模型将用来作为RAG中基于知识片段回答用户问题的LLM ollamapullqwen2:7b-instruct 本文所有示例在安装Anaconda环境后,再安装下面的Python库即可。整个代码已经在Google Colab进行了测试: pipinstall-Ulangchainlangchain_communitypypdfsentence_transformerschromadbtrulens_evallangchain_openai | 库 | 版本 |
|---|
| langchain | 0.2.7 | | langchain_community | 0.2.7 | | langchain_openai | 0.1.7 | | pypdf | 4.2.0 | | sentence_transformers | 2.7.0 | | chromadb | 0.5.3 | | trulens_eval | 0.33.0 |
文中所用到的问答对、原始数据,可以从代码仓库中取用。 import os
import pandas as pd
EMBEDDING_MODEL_PATH=
dt=
version=
output_dir=os.path.join(os.path.pardir,,)
os.environ[]=
os.environ[]= qa_df=pd.read_excel(os.path.join(output_dir,)) PyPDFLoader
loader=PyPDFLoader(os.path.join(os.path.pardir,,))
documents=loader.load() uuid4
RecursiveCharacterTextSplitter
Chroma
(documents,filepath,chunk_size=,chunk_overlap=,seperators=[,],force_split=):
os.path.exists(filepath)force_split:
()
pickle.load((filepath,))
splitter=RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=seperators
)
split_docs=splitter.split_documents(documents)
chunksplit_docs:
chunk.metadata[]=(uuid4())
pickle.dump(split_docs,(filepath,))
split_docs splitted_docs=split_docs(documents,os.path.join(output_dir,),chunk_size=,chunk_overlap=) HuggingFaceBgeEmbeddings
device=torch.cuda.is_available()
()
embeddings=HuggingFaceBgeEmbeddings(
model_name=EMBEDDING_MODEL_PATH,
model_kwargs={:device},
encode_kwargs={:}
)tqdm
(docs,store_path,force_rebuild=):
os.path.exists(store_path):
force_rebuild=
force_rebuild:
vector_db=Chroma.from_documents(
docs,
embedding=embeddings,
persist_directory=store_path
)
:
vector_db=Chroma(
persist_directory=store_path,
embedding_function=embeddings
)
vector_db vector_db=get_vector_db(splitted_docs,store_path=os.path.join(os.path.pardir,output_dir,,)) Ollama
StrOutputParser
RunnablePassthrough
PromptTemplate
(docs):
.join(doc.page_contentdocdocs)
llm=Ollama(
model=,
base_url=
)
prompt_tmpl=
prompt=PromptTemplate.from_template(prompt_tmpl)
retriever=vector_db.as_retriever(search_kwargs={:})
rag_chain=(
{:retriever|format_docs,:RunnablePassthrough()}
|prompt
|llm
|StrOutputParser()
)prediction_df=qa_df[qa_df[]==][[,,,]] TruLens默认使用的是OpenAI的LLM,下面提供了使用自定义OpenAI兼容的API,以及Ollama的方式 ChatOpenAI
llm_chain=ChatOpenAI(
api_key=os.environ[],
base_url=os.environ[],
model_name=
) # from langchain.llms import Ollama
# llm_chain = Ollama(
# model='qwen2:7b-instruct',
# base_url="http://192.168.31.92:11434"
# )
App
Feedback
OpenAI
LangchainLangchainProvider
provider=LangchainProvider(chain=llm_chain)
context=App.select_context(rag_chain)
f_groundedness=(
Feedback(provider.groundedness_measure_with_cot_reasons,name=)
.on(context.collect())
.on_output()
)
f_answer_relevance=(
Feedback(provider.relevance_with_cot_reasons,name=)
.on_input_output()
)
f_context_relevance=(
Feedback(provider.context_relevance_with_cot_reasons,name=)
.on_input()
.on(context)
.aggregate(np.mean)
) ✅InGroundedness,inputsourcewillbesetto__record__.app.first.steps__.context.first.invoke.rets[:].page_content.collect().
✅InGroundedness,inputstatementwillbesetto__record__.main_outputor`Select.RecordOutput`.
✅InAnswerRelevance,inputpromptwillbesetto__record__.main_inputor`Select.RecordInput`.
✅InAnswerRelevance,inputresponsewillbesetto__record__.main_outputor`Select.RecordOutput`.
✅InContextRelevance,inputquestionwillbesetto__record__.main_inputor`Select.RecordInput`.
✅InContextRelevance,inputcontextwillbesetto__record__.app.first.steps__.context.first.invoke.rets[:].page_content. TruChain,Tru
tru=Tru()
tru.reset_database() 注意,如果在同一个目录下,有多个版本在迭代,并且希望使用TruLens把这些迭代的评估结果都记录下来,那么不要调用tru.reset_database(),否则之前的评估记录会被清除。评估记录默认是保存在一个名为default.sqlite的SQLite数据库中
?Truinitializedwithdburlsqlite:///default.sqlite.
?Secretkeysmaybewrittentothedatabase.Seethe`database_redact_keys`optionof`Tru`topreventthis. tru_recorder=TruChain(
rag_chain,
app_id=,
feedbacks=[f_answer_relevance,f_context_relevance,f_groundedness]
) answer_dict={}
idx,rowtqdm(prediction_df.iterrows(),total=(prediction_df)):
tru_recorderrecording:
uuid=row[]
question=row[]
answer=rag_chain.invoke(question)
answer_dict[question]={
:uuid,
:row[],
:answer
}
total_cost为0是因为所使用的模型不是OpenAI的模型,关联不上价格 Starting dashboard ...Config file already exists. Skipping writing process.Credentials file already exists. Skipping writing process.Dashboard already running at path: Network URL: http://192.168.31.92:48913< open: returncode: None args: ['streamlit', 'run', '--server.headless=True'...> open: returncode: None args: ['streamlit', 'run', '--server.headless=True'...>
使用浏览器访问上方代码运行后出现的地址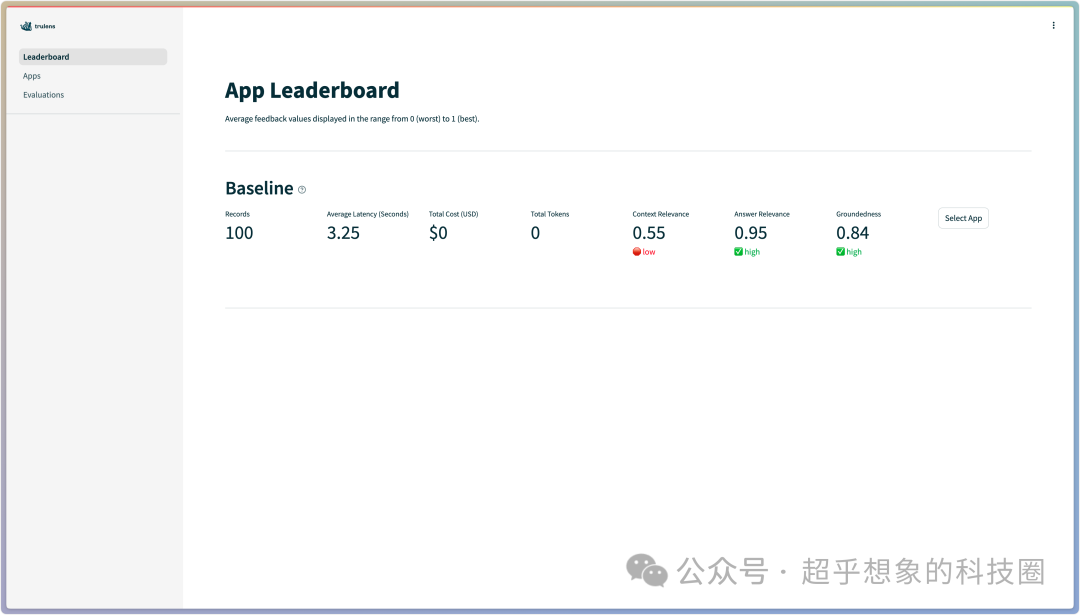 在Leaderboard中,可以直观的看到RAG triad的三个评估指标,从这个指标中可以明显的看出,当前整个流程的薄弱环节点击到Evaluations,可以看到每条测试数据的三个评估指标,点击测试数据,可以查看整个Trace详情 |










