|
从Hugging Face社区的数据可以得出以下关于金融领域开源大模型的趋势和洞察: 1. 文本生成模型的主导地位Text Generation(文本生成) 模型在金融领域内占据主导地位。多个模型专注于此类任务,如 AdaptLLM/finance-LLM 系列、 TheBloke/finance-LLM 系列和 instruction-pretrain/finance-Llama3-8B。这表明,金融领域内生成式AI模型的需求较高,可能用于自动化报告生成、市场预测、智能客服等应用场景。 更新频率较高的模型,如 AdaptLLM/finance-LLM 系列,展示了持续的优化和开发热情,这反映了该领域的快速发展和持续改进的需求。
2. 模型大小与复杂性一些模型使用了更大参数量的版本,如 AdaptLLM/finance-LLM-13B 和 Ceadar-ie/FinanceConnect-13B,这表明在金融领域内,模型的复杂性和能力被认为是提高生成质量的关键因素。 同时,一些较小的模型如 cxllin/Llama2-7b-Finance 和 lxyuan/distilgpt2-finetuned-finance,则可能用于资源有限的环境或对计算需求较小的任务。这表明了在金融领域内,存在针对不同应用场景和资源需求的多样化模型选择。
3. 文本分类和情感分析的需求Text Classification(文本分类) 尤其是情感分析类模型,如 nickmuchi/finbert-tone-finetuned-finance-topic-classification 和 bardsai/finance-sentiment-zh-base,也占有相当的比例。这表明情感分析在金融决策中的重要性,尤其是在处理客户反馈、新闻分析以及市场情绪预测时。 FinanceInc/auditor_sentiment_finetuned 和 RashidNLP/Finance-Sentiment-Classification 这样的情感分类模型,虽然下载量较低,但仍被关注,用于特定的金融情境分析。
4. 跨语言与多样性需求5. 开源社区的活跃性6. 细分任务和特定用途的模型7. 模型更新与用户反馈结论金融领域的开源大模型呈现出高度专业化的趋势,文本生成和分类模型占据主导地位,并逐渐朝着多语言支持和特定任务优化方向发展。随着金融科技的不断进步,预计这些模型将会越来越多地应用于自动化金融分析、市场预测和智能决策中。 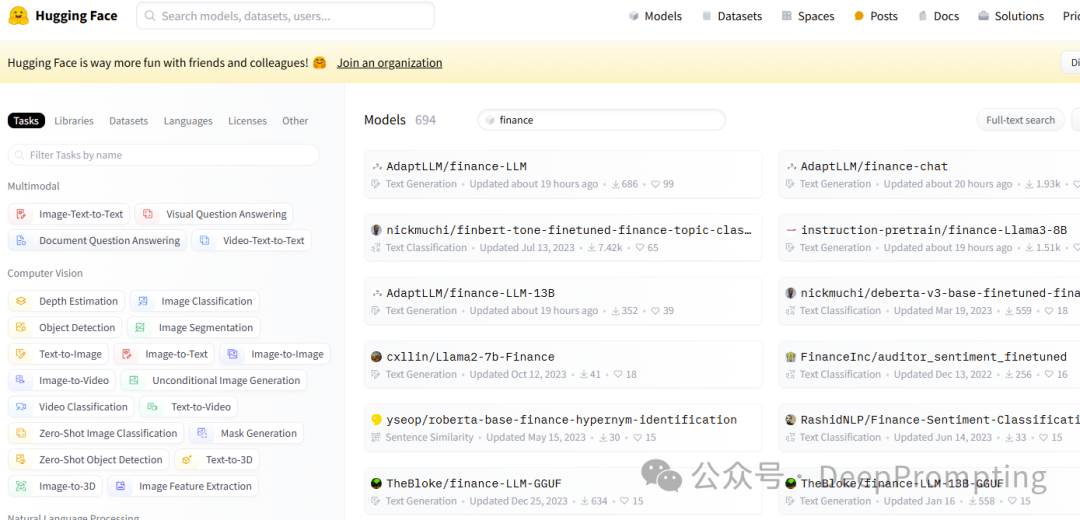
| 









