ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin-right: auto;margin-bottom: 1em;margin-left: auto;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">项目结构ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;overflow-x: auto;border-radius: 8px;margin: 10px 8px;">|--deepdoc
|--parser
|--resume
|--entities
|--step_one.py
|--step_two.py
|--docx_parser.py
|--pdf_parser.py
|--excel_parser.py
|--html_parser.py
|--json_parser.py
|--markdown_parser.py
|--ppt_parser.py
|--vision
|--layout_recoginzer.py
|--ocr.py
|--ocr.res
|--operators.py
|--postprocess.py
|--recoginzer.py
|--seeit.py
|--t_recoginzer.py
|--t_ocr.py
|--table_structure_recognizer.pyingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 2em auto 1em;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">核心组件ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;padding-left: 1em;list-style: circle;color: rgb(63, 63, 63);" class="list-paddingleft-1">•OCR •版面结构分析 •表格结构识别 •解析器 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 2em auto 1em;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">解析器ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 4em auto 2em;padding-right: 0.2em;padding-left: 0.2em;background: rgb(15, 76, 129);color: rgb(255, 255, 255);">简历类型的处理ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">简历是完全没有规律的文档,一份简历可以分解为多个字段组成的结构化数据。因此需要做特殊处理,entities中定义了一些大学、公司、产业等信息,用于后续关键词提取;整个简历的处理过程分为两部进行:第一步先根据预先定义的关键词提取有效信息、接着再第二步再做一些合并以及过滤操作。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 4em auto 2em;padding-right: 0.2em;padding-left: 0.2em;background: rgb(15, 76, 129);color: rgb(255, 255, 255);">PDF文档的处理ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">PDF文档比较复杂,需要用到OCR模型,并且版面结构不同,内置了很多排序规则,另外还用到了XGB用于规则之外的补充。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">经过实测,规则已经处理了绝大部分文本块的排序过程,XGB作用不大,并且通过特征重要性可以看到主要是坐标类型的特征起到了作用。整个处理流程可以简化如下:文档转图片->版面分析->表格识别->文字识别->合并段落->后处理 其他类型的处理每一种类型的文档都有一个对应的解析器,基本都是用现成的库进行处理的。 视觉信息处理版面结构识别不同类型的文件具有不同的布局,对于论文来说,会包含较多的图表、甚至还会有公式,因此只有当准确识别出文件的类型和布局才能有效处理该文档。版面结构定义了以下10种类别,用于区分不同的内容: •文本 •标题 •配图 •配图标题 •表格 •表格标题 •页头 •页尾 •参考引用 •公式

执行命令: pythondeepdoc/vision/t_recognizer.py--inputs=path_to_images_or_pdfs--threshold=0.2--mode=layout--output_dir=path_to_store_result 表格结构识别表的结构可能非常复杂,比如多层次结构标题、跨单元格以及行列结构不统一等。表结构识别针对表格内容定义了5种类别: •列 •行 •列标题 •行标题 •合并单元格 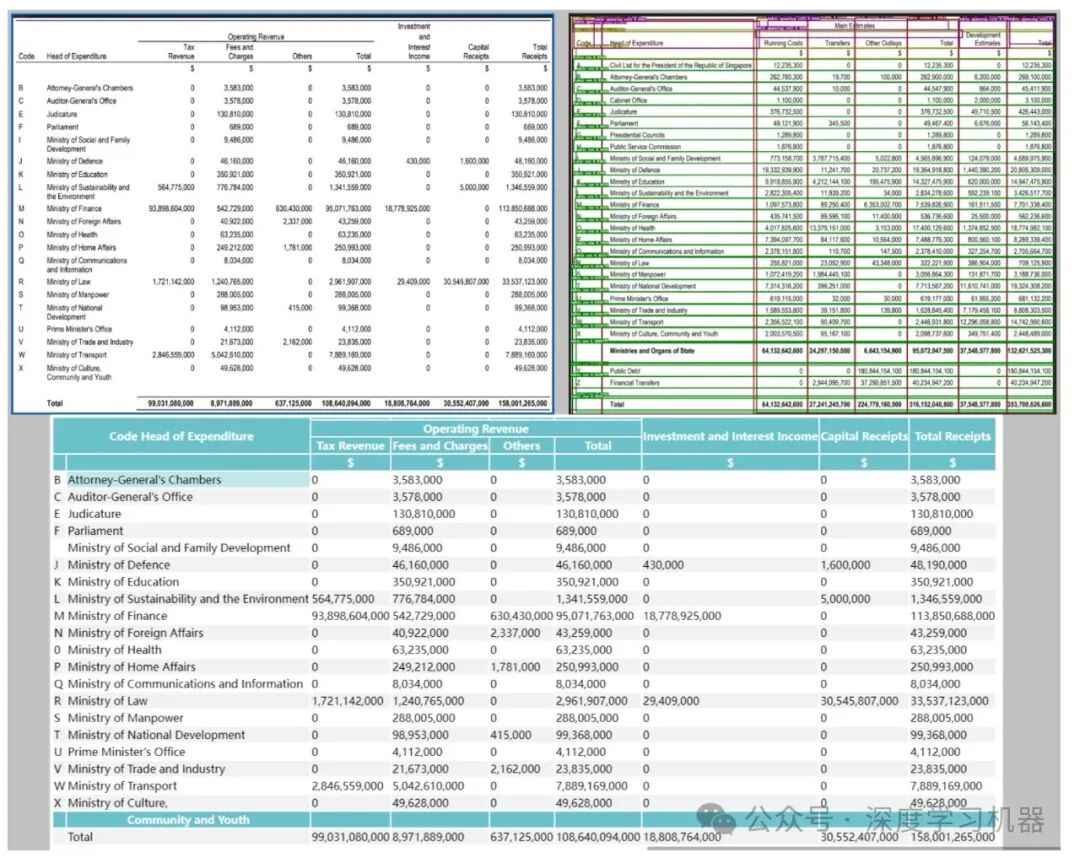
执行命令: pythondeepdoc/vision/t_recognizer.py--inputs=path_to_images_or_pdfs--threshold=0.2--mode=tsr--output_dir=path_to_store_result 与版面结构分析不同,表格结构识别只会把可能是表格的区域识别出来
|










