ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);border-bottom: 2px solid rgb(239, 112, 96);visibility: visible;">坚持写作第12天:开源模型原生的能力不满足业务需求,私有部署的需求Fine-Tuning前言
面向初学者的深度学习课: 吴恩达《人人 AI》(特别通俗) https://www.zhihu.com/education/video-course/1556316449043668992 李沐的深度学习课 (稍微深一点) https://www.zhihu.com/education/video-course/1647604835598092705
在这个更广泛的定位上,已经有很多优秀的课程。本课程只针对大模型微调的知识基础展开。 什么时候需要 Fine-Tuning
先看一个例子 订酒店机器人 [
{
"role":"user",
"content":"您好,我要找一家舒适型酒店住宿,然后希望酒店提供暖气与行李寄存。"
},
{
"role":"search",
"arguments":{
"facilities":[
"暖气",
"行李寄存"
],
"type":"舒适型"
}
},
{
"role":"return",
"records":[
{
"name":"北京香江戴斯酒店",
"type":"舒适型",
"address":"北京东城区南河沿大街南湾子胡同1号",
"subway":"天安门东地铁站B口",
"phone":"010-65127788",
"facilities":[
"酒店各处提供wifi",
"国际长途电话",
"吹风机",
"24小时热水",
"暖气",
"西式餐厅",
"中式餐厅",
"残疾人设施",
"会议室",
"无烟房",
"商务中心",
"早餐服务",
"接机服务",
"接待外宾",
"洗衣服务",
"行李寄存",
"租车",
"叫醒服务"
],
"price":328.0,
"rating":4.2,
"hotel_id":10
}
]
},
{
"role":"assistant",
"content":"那推荐您北京香江戴斯酒店,符合您的全部住宿要求并且价格又比较合适的酒店。"
},
{
"role":"user",
"content":"这家酒店的价格是多少?"
},
{
"role":"assistant",
"content":"这家酒店的价格是每晚328.0元。"
},
{
"role":"user",
"content":"好的,那就预订北京香江戴斯酒店吧!"
},
{
"role":"assistant",
"content":"好的,祝您入住愉快!"
}
]
一、先找找感觉 上手操作一个简单的例子: - 数据源:https://huggingface.co/datasets/rotten_tomatoes
1.1、工具:介绍一个模型训练利器 Hugging Face- 官网:http://www.huggingface.co
- 尤其基于 transformer 的开源模型非常全
- 封装了模型、数据集、训练器等,使模型的下载、使用、训练都非常方便
安装依赖 #pip安装
pipinstalltransformers#安装最新的版本
pipinstalltransformers==4.30#安装指定版本
#conda安装
condainstall-chuggingfacetransformers#只4.0以后的版本
1.2、操作流程
注意:
importdatasets
fromdatasetsimportload_dataset
fromtransformersimportAutoTokenizer,AutoModel
fromtransformersimportAutoModelForCausalLM
fromtransformersimportTrainingArguments,Seq2SeqTrainingArguments
fromtransformersimportTrainer,Seq2SeqTrainer
importtransformers
fromtransformersimportDataCollatorWithPadding
fromtransformersimportTextGenerationPipeline
importtorch
importnumpyasnp
importos,re
fromtqdmimporttqdm
importtorch.nnasnn
通过HuggingFace,可以指定数据集名称,运行时自动下载 #数据集名称
DATASET_NAME="rotten_tomatoes"
#加载数据集
raw_datasets=load_dataset(DATASET_NAME)
#训练集
raw_train_dataset=raw_datasets["train"]
#验证集
raw_valid_dataset=raw_datasets["validation"]
通过HuggingFace,可以指定模型名称,运行时自动下载 #模型名称
MODEL_NAME="gpt2"
#加载模型
model=AutoModelForCausalLM.from_pretrained(MODEL_NAME,trust_remote_code=True)
通过HuggingFace,可以指定模型名称,运行时自动下载对应Tokenizer #加载tokenizer
tokenizer=AutoTokenizer.from_pretrained(MODEL_NAME,trust_remote_code=True)
tokenizer.add_special_tokens({'pad_token':'[PAD]'})
tokenizer.pad_token_id=0
#其它相关公共变量赋值
#设置随机种子:同个种子的随机序列可复现
transformers.set_seed(42)
#标签集
named_labels=['neg','pos']
#标签转token_id
label_ids=[
tokenizer(named_labels[i],add_special_tokens=False)["input_ids"][0]
foriinrange(len(named_labels))
]
- <-100><-100>...<OUTPUT TOKEN IDS><-100>...<-100>
- <INPUT 1.1><INPUT 1.2>...<EOS_TOKEN_ID><OUTPUT TOKEN IDS><
 AD>...<AD> AD>...<AD> - <INPUT 2.1><INPUT 2.2>...<EOS_TOKEN_ID><OUTPUT TOKEN IDS><AD>...<AD>
- 拼接输入输出:<INPUT TOKEN IDS><EOS_TOKEN_ID><OUTPUT TOKEN IDS>
- 标识出参与 Loss 计算的 Tokens (只有输出 Token 参与 Loss 计算)
MAX_LEN=32#最大序列长度(输入+输出)
DATA_BODY_KEY="text"#数据集中的输入字段名
DATA_LABEL_KEY="label"#数据集中输出字段名
#定义数据处理函数,把原始数据转成input_ids,attention_mask,labels
defprocess_fn(examples):
model_inputs={
"input_ids":[],
"attention_mask":[],
"labels":[],
}
foriinrange(len(examples[DATA_BODY_KEY])):
inputs=tokenizer(examples[DATA_BODY_KEY][i],add_special_tokens=False)
label=label_ids[examples[DATA_LABEL_KEY][i]]
input_ids=inputs["input_ids"]+[tokenizer.eos_token_id,label]
raw_len=len(input_ids)
input_len=len(inputs["input_ids"])+1
ifraw_len>=MAX_LEN:
input_ids=input_ids[-MAX_LEN:]
attention_mask=[1]*MAX_LEN
labels=[-100]*(MAX_LEN-1)+[label]
else:
input_ids=input_ids+[tokenizer.pad_token_id]*(MAX_LEN-raw_len)
attention_mask=[1]*raw_len+[0]*(MAX_LEN-raw_len)
labels=[-100]*input_len+[label]+[-100]*(MAX_LEN-raw_len)
model_inputs["input_ids"].append(input_ids)
model_inputs["attention_mask"].append(attention_mask)
model_inputs["labels"].append(labels)
returnmodel_inputs
#处理训练数据集
tokenized_train_dataset=raw_train_dataset.map(
process_fn,
batched=True,
remove_columns=raw_train_dataset.columns,
desc="Runningtokenizerontraindataset",
)
#处理验证数据集
tokenized_valid_dataset=raw_valid_dataset.map(
process_fn,
batched=True,
remove_columns=raw_valid_dataset.columns,
desc="Runningtokenizeronvalidationdataset",
)
- 定义数据规整器:训练时自动将数据拆分成 Batch
#定义数据校准器(自动生成batch)
collater=DataCollatorWithPadding(
tokenizer=tokenizer,return_tensors="pt",
)
LR=2e-5#学习率
BATCH_SIZE=8#Batch大小
INTERVAL=100#每多少步打一次log/做一次eval
#定义训练参数
training_args=TrainingArguments(
output_dir="./output",#checkpoint保存路径
evaluation_strategy="steps",#按步数计算eval频率
overwrite_output_dir=True,
num_train_epochs=1,#训练epoch数
per_device_train_batch_size=BATCH_SIZE,#每张卡的batch大小
gradient_accumulation_steps=1,#累加几个step做一次参数更新
per_device_eval_batch_size=BATCH_SIZE,#evaluationbatchsize
eval_steps=INTERVAL,#每N步eval一次
logging_steps=INTERVAL,#每N步log一次
save_steps=INTERVAL,#每N步保存一个checkpoint
learning_rate=LR,#学习率
)
#节省显存
model.gradient_checkpointing_enable()
#定义训练器
trainer=Trainer(
model=model,#待训练模型
args=training_args,#训练参数
data_collator=collater,#数据校准器
train_dataset=tokenized_train_dataset,#训练集
eval_dataset=tokenized_valid_dataset,#验证集
#compute_metrics=compute_metric,#计算自定义评估指标
)
#开始训练
trainer.train()
总结上述过程
- 通过 labels 标识出哪部分是输出(只有输出的 token 参与 loss 计算)
划重点:
记住上面的流程,你就能跑通模型训练过程 理解下面的知识,你就能训练好模型效果
二、什么是模型 尝试: 用简单的数学语言表达概念 2.1、通俗(不严谨)的说、模型是一个函数:- 它接收输入:可以是一个词、一个句子、一篇文章或图片、语音、视频 ...
- 这些物体都被表示成一个数学「矩阵」(其实应该叫张量,tensor)
- 可以是「是否」({0,1})、标签({0,1,2,3...})、一个数值(回归问题)、下一个词的概率 ...
把它想象成一个方程:
每条数据就是一对儿 ,它们是常量 参数是未知数,是变量 就是表达式:我们不知道真实的公式是什么样的,所以假设了一个足够复杂的公式(比如,一个特定结构的神经网络) 这个求解这个方程(近似解)就是训练过程
通俗的讲: 训练,就是确定这组参数的取值 2.2、一个最简单的神经网络一个神经元:

把很多神经元连接起来,就成了神经网络:、、、... 
这里的叫激活函数,有很多种形式 现今的大模型中常用的激活函数包括:ReLU、GELU、Swish 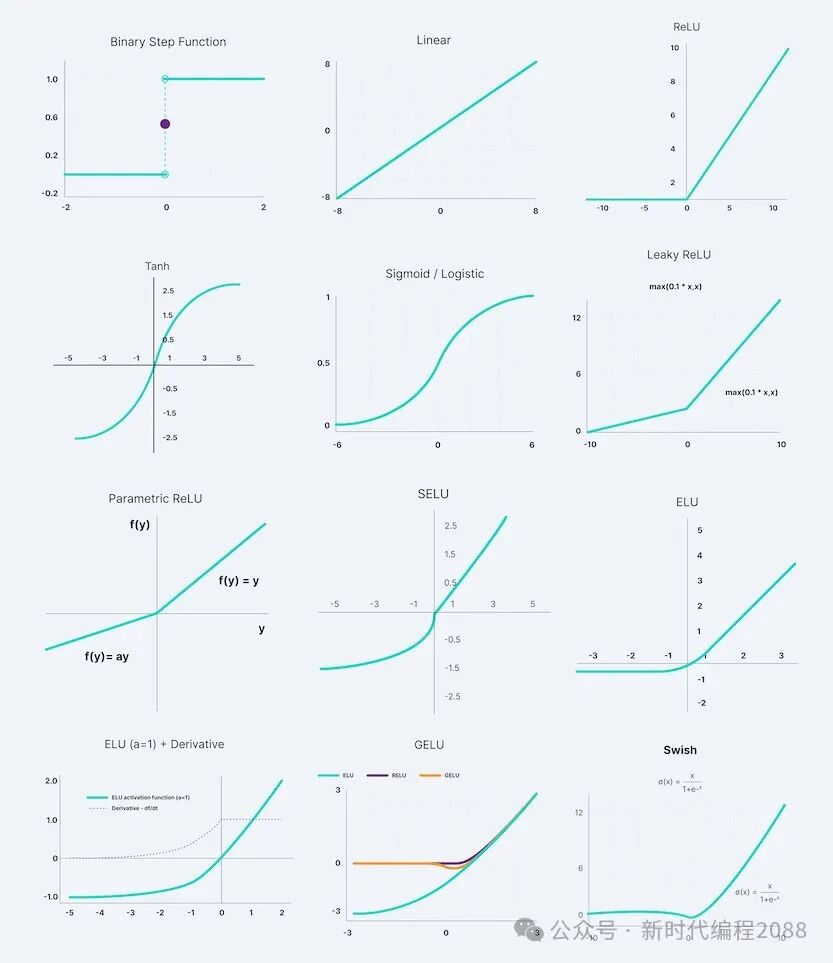
思考: 这里如果没有激活函数会怎样? 三、什么是模型训练 我们希望找到一组参数,使模型预测的输出与真实的输出,尽可能的接近 这里,我们(至少)需要两个要素: - 一个损失函数,衡量模型预测的输出与真实输出之间的差距:
3.1、模型训练本质上是一个求解最优化问题的过程3.2、怎么求解回忆一下梯度的定义 
从最简单的情况说起:梯度下降与凸问题 
梯度决定了函数变化的方向,每次迭代更新我们会收敛到一个极值 其中,叫做学习率,它和梯度的模数共同决定了每步走多远 3.3、现实总是没那么简单(1):在整个数据集上求梯度,计算量太大了
经验:
3.4、现实总是没那么简单(2):深度学习没有全局最优解(非凸问题)

3.5、现实总是没那么简单(3):学习率也很关键,甚至需要动态调整
划重点:适当调整学习率(Learning Rate),避免陷入很差的局部解或者跳过了好的解 四、求解器 为了让训练过程更好的收敛,人们设计了很多更复杂的求解器 - 比如:SGD、L-BFGS、Rprop、RMSprop、Adam、AdamW、AdaGrad、AdaDelta 等等
- 但是,好在对于Transformer最常用的就是 Adam 或者 AdamW
五、一些常用的损失函数 
两个概率分布之间的差异,交叉熵: ——假设是概率分布 p,q 是离散的 这些损失函数也可以组合使用(在模型蒸馏的场景常见这种情况),例如,其中是一个预先定义的权重,也叫一个「超参」
思考: 你能找到这些损失函数和分类、聚类、回归问题之间的关系吗? 六、再动手复习一下上述过程 用 PyTorch 训练一个最简单的神经网络 数据集(MNIST)样例: 
输入一张 28×28 的图像,输出标签 0--9 from__future__importprint_function
importtorch
importtorch.nnasnn
importtorch.nn.functionalasF
importtorch.optimasoptim
fromtorchvisionimportdatasets,transforms
fromtorch.optim.lr_schedulerimportStepLR
BATCH_SIZE=64
TEST_BACTH_SIZE=1000
EPOCHS=15
LR=0.01
SEED=42
LOG_INTERVAL=100
#定义一个全连接网络
classFeedForwardNet(nn.Module):
def__init__(self):
super().__init__()
#第一层784维输入、256维输出--图像大小28×28=784
self.fc1=nn.Linear(784,256)
#第二层256维输入、128维输出
self.fc2=nn.Linear(256,128)
#第三层128维输入、64维输出
self.fc3=nn.Linear(128,64)
#第四层64维输入、10维输出--输出类别10类(0,1,...9)
self.fc4=nn.Linear(64,10)
#Dropoutmodulewith0.2dropprobability
self.dropout=nn.Dropout(p=0.2)
defforward(self,x):
#把输入展平成1D向量
x=x.view(x.shape[0],-1)
#每层激活函数是ReLU,额外加dropout
x=self.dropout(F.relu(self.fc1(x)))
x=self.dropout(F.relu(self.fc2(x)))
x=self.dropout(F.relu(self.fc3(x)))
#输出为10维概率分布
x=F.log_softmax(self.fc4(x),dim=1)
returnx
#训练过程
deftrain(model,loss_fn,device,train_loader,optimizer,epoch):
#开启梯度计算
model.train()
forbatch_idx,(data_input,true_label)inenumerate(train_loader):
#从数据加载器读取一个batch
#把数据上载到GPU(如有)
data_input,true_label=data_input.to(device),true_label.to(device)
#求解器初始化(每个batch初始化一次)
optimizer.zero_grad()
#正向传播:模型由输入预测输出
output=model(data_input)
#计算loss
loss=loss_fn(output,true_label)
#反向传播:计算当前batch的loss的梯度
loss.backward()
#由求解器根据梯度更新模型参数
optimizer.step()
#间隔性的输出当前batch的训练loss
ifbatch_idx%LOG_INTERVAL==0:
print('TrainEpoch:{}[{}/{}({:.0f}%)]\tLoss:{:.6f}'.format(
epoch,batch_idx*len(data_input),len(train_loader.dataset),
100.*batch_idx/len(train_loader),loss.item()))
#计算在测试集的准确率和loss
deftest(model,loss_fn,device,test_loader):
model.eval()
test_loss=0
correct=0
withtorch.no_grad():
fordata,targetintest_loader:
data,target=data.to(device),target.to(device)
output=model(data)
#sumupbatchloss
test_loss+=loss_fn(output,target,reduction='sum').item()
#gettheindexofthemaxlog-probability
pred=output.argmax(dim=1,keepdim=True)
correct+=pred.eq(target.view_as(pred)).sum().item()
test_loss/=len(test_loader.dataset)
print('\nTestset:Averageloss:{:.4f},Accuracy:{}/{}({:.0f}%)\n'.format(
test_loss,correct,len(test_loader.dataset),
100.*correct/len(test_loader.dataset)))
defmain():
#检查是否有GPU
use_cuda=torch.cuda.is_available()
#设置随机种子(以保证结果可复现)
torch.manual_seed(SEED)
#训练设备(GPU或CPU)
device=torch.device("cuda"ifuse_cudaelse"cpu")
#设置batchsize
train_kwargs={'batch_size':BATCH_SIZE}
test_kwargs={'batch_size':TEST_BACTH_SIZE}
ifuse_cuda:
cuda_kwargs={'num_workers':1,
'pin_memory':True,
'shuffle':True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
#数据预处理(转tensor、数值归一化)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
#自动下载MNIST数据集
dataset_train=datasets.MNIST('data',train=True,download=True,
transform=transform)
dataset_test=datasets.MNIST('data',train=False,
transform=transform)
#定义数据加载器(自动对数据加载、多线程、随机化、划分batch、等等)
train_loader=torch.utils.data.DataLoader(dataset_train,**train_kwargs)
test_loader=torch.utils.data.DataLoader(dataset_test,**test_kwargs)
#创建神经网络模型
model=FeedForwardNet().to(device)
#指定求解器
optimizer=optim.SGD(model.parameters(),lr=LR)
#scheduler=StepLR(optimizer,step_size=1,gamma=0.9)
#定义loss函数
#注:nll 作用于 log_softmax 等价于交叉熵,感兴趣的同学可以自行推导
#https://blog.csdn.net/weixin_38145317/article/details/103288032
loss_fn=F.nll_loss
#训练N个epoch
forepochinrange(1,EPOCHS+1):
train(model,loss_fn,device,train_loader,optimizer,epoch)
test(model,loss_fn,device,test_loader)
#scheduler.step()
if__name__=='__main__':
main()
/opt/conda/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Train Epoch: 1 [0/60000 (0%)] Loss: 2.287443
Train Epoch: 1 [6400/60000 (11%)] Loss: 2.284967
Train Epoch: 1 [12800/60000 (21%)] Loss: 2.273498
Train Epoch: 1 [19200/60000 (32%)] Loss: 2.022655
Train Epoch: 1 [25600/60000 (43%)] Loss: 1.680803
Train Epoch: 1 [32000/60000 (53%)] Loss: 1.322924
Train Epoch: 1 [38400/60000 (64%)] Loss: 0.978875
Train Epoch: 1 [44800/60000 (75%)] Loss: 0.955985
Train Epoch: 1 [51200/60000 (85%)] Loss: 0.670422
Train Epoch: 1 [57600/60000 (96%)] Loss: 0.821590
Test set: Average loss: 0.5133, Accuracy: 8522/10000 (85%)
Train Epoch: 2 [0/60000 (0%)] Loss: 0.740346
Train Epoch: 2 [6400/60000 (11%)] Loss: 0.697988
Train Epoch: 2 [12800/60000 (21%)] Loss: 0.676830
Train Epoch: 2 [19200/60000 (32%)] Loss: 0.531716
Train Epoch: 2 [25600/60000 (43%)] Loss: 0.457828
Train Epoch: 2 [32000/60000 (53%)] Loss: 0.621303
Train Epoch: 2 [38400/60000 (64%)] Loss: 0.354285
Train Epoch: 2 [44800/60000 (75%)] Loss: 0.588098
Train Epoch: 2 [51200/60000 (85%)] Loss: 0.530143
Train Epoch: 2 [57600/60000 (96%)] Loss: 0.533157
Test set: Average loss: 0.3203, Accuracy: 9035/10000 (90%)
Train Epoch: 3 [0/60000 (0%)] Loss: 0.425095
Train Epoch: 3 [6400/60000 (11%)] Loss: 0.301024
Train Epoch: 3 [12800/60000 (21%)] Loss: 0.330063
Train Epoch: 3 [19200/60000 (32%)] Loss: 0.362905
Train Epoch: 3 [25600/60000 (43%)] Loss: 0.387243
Train Epoch: 3 [32000/60000 (53%)] Loss: 0.436325
Train Epoch: 3 [38400/60000 (64%)] Loss: 0.266472
Train Epoch: 3 [44800/60000 (75%)] Loss: 0.463275
Train Epoch: 3 [51200/60000 (85%)] Loss: 0.264305
Train Epoch: 3 [57600/60000 (96%)] Loss: 0.480805
Test set: Average loss: 0.2456, Accuracy: 9262/10000 (93%)
Train Epoch: 4 [0/60000 (0%)] Loss: 0.343381
Train Epoch: 4 [6400/60000 (11%)] Loss: 0.222288
Train Epoch: 4 [12800/60000 (21%)] Loss: 0.200421
Train Epoch: 4 [19200/60000 (32%)] Loss: 0.301372
Train Epoch: 4 [25600/60000 (43%)] Loss: 0.282800
Train Epoch: 4 [32000/60000 (53%)] Loss: 0.424678
Train Epoch: 4 [38400/60000 (64%)] Loss: 0.160868
Train Epoch: 4 [44800/60000 (75%)] Loss: 0.373828
Train Epoch: 4 [51200/60000 (85%)] Loss: 0.273351
Train Epoch: 4 [57600/60000 (96%)] Loss: 0.498258
Test set: Average loss: 0.2007, Accuracy: 9388/10000 (94%)
Train Epoch: 5 [0/60000 (0%)] Loss: 0.175644
Train Epoch: 5 [6400/60000 (11%)] Loss: 0.349571
Train Epoch: 5 [12800/60000 (21%)] Loss: 0.231020
Train Epoch: 5 [19200/60000 (32%)] Loss: 0.277835
Train Epoch: 5 [25600/60000 (43%)] Loss: 0.248639
Train Epoch: 5 [32000/60000 (53%)] Loss: 0.338623
Train Epoch: 5 [38400/60000 (64%)] Loss: 0.174397
Train Epoch: 5 [44800/60000 (75%)] Loss: 0.384121
Train Epoch: 5 [51200/60000 (85%)] Loss: 0.238978
Train Epoch: 5 [57600/60000 (96%)] Loss: 0.279425
Test set: Average loss: 0.1718, Accuracy: 9461/10000 (95%)
Train Epoch: 6 [0/60000 (0%)] Loss: 0.146129
Train Epoch: 6 [6400/60000 (11%)] Loss: 0.270161
Train Epoch: 6 [12800/60000 (21%)] Loss: 0.157764
Train Epoch: 6 [19200/60000 (32%)] Loss: 0.274829
Train Epoch: 6 [25600/60000 (43%)] Loss: 0.224544
Train Epoch: 6 [32000/60000 (53%)] Loss: 0.273076
Train Epoch: 6 [38400/60000 (64%)] Loss: 0.091917
Train Epoch: 6 [44800/60000 (75%)] Loss: 0.318671
Train Epoch: 6 [51200/60000 (85%)] Loss: 0.220927
Train Epoch: 6 [57600/60000 (96%)] Loss: 0.353987
Test set: Average loss: 0.1518, Accuracy: 9534/10000 (95%)
Train Epoch: 7 [0/60000 (0%)] Loss: 0.169520
Train Epoch: 7 [6400/60000 (11%)] Loss: 0.189826
Train Epoch: 7 [12800/60000 (21%)] Loss: 0.139019
Train Epoch: 7 [19200/60000 (32%)] Loss: 0.231475
Train Epoch: 7 [25600/60000 (43%)] Loss: 0.213273
Train Epoch: 7 [32000/60000 (53%)] Loss: 0.326085
Train Epoch: 7 [38400/60000 (64%)] Loss: 0.124614
Train Epoch: 7 [44800/60000 (75%)] Loss: 0.314796
Train Epoch: 7 [51200/60000 (85%)] Loss: 0.173023
Train Epoch: 7 [57600/60000 (96%)] Loss: 0.272714
Test set: Average loss: 0.1353, Accuracy: 9580/10000 (96%)
Train Epoch: 8 [0/60000 (0%)] Loss: 0.139128
Train Epoch: 8 [6400/60000 (11%)] Loss: 0.144777
Train Epoch: 8 [12800/60000 (21%)] Loss: 0.102367
Train Epoch: 8 [19200/60000 (32%)] Loss: 0.192136
Train Epoch: 8 [25600/60000 (43%)] Loss: 0.141218
Train Epoch: 8 [32000/60000 (53%)] Loss: 0.234929
Train Epoch: 8 [38400/60000 (64%)] Loss: 0.103180
Train Epoch: 8 [44800/60000 (75%)] Loss: 0.320878
Train Epoch: 8 [51200/60000 (85%)] Loss: 0.156626
Train Epoch: 8 [57600/60000 (96%)] Loss: 0.349143
Test set: Average loss: 0.1235, Accuracy: 9614/10000 (96%)
Train Epoch: 9 [0/60000 (0%)] Loss: 0.136772
Train Epoch: 9 [6400/60000 (11%)] Loss: 0.161713
Train Epoch: 9 [12800/60000 (21%)] Loss: 0.130365
Train Epoch: 9 [19200/60000 (32%)] Loss: 0.111859
Train Epoch: 9 [25600/60000 (43%)] Loss: 0.216221
Train Epoch: 9 [32000/60000 (53%)] Loss: 0.166046
Train Epoch: 9 [38400/60000 (64%)] Loss: 0.077858
Train Epoch: 9 [44800/60000 (75%)] Loss: 0.263344
Train Epoch: 9 [51200/60000 (85%)] Loss: 0.153452
Train Epoch: 9 [57600/60000 (96%)] Loss: 0.358510
Test set: Average loss: 0.1135, Accuracy: 9640/10000 (96%)
Train Epoch: 10 [0/60000 (0%)] Loss: 0.091045
Train Epoch: 10 [6400/60000 (11%)] Loss: 0.185156
Train Epoch: 10 [12800/60000 (21%)] Loss: 0.098523
Train Epoch: 10 [19200/60000 (32%)] Loss: 0.213850
Train Epoch: 10 [25600/60000 (43%)] Loss: 0.112603
Train Epoch: 10 [32000/60000 (53%)] Loss: 0.254803
Train Epoch: 10 [38400/60000 (64%)] Loss: 0.074294
Train Epoch: 10 [44800/60000 (75%)] Loss: 0.200418
Train Epoch: 10 [51200/60000 (85%)] Loss: 0.162135
Train Epoch: 10 [57600/60000 (96%)] Loss: 0.328646
Test set: Average loss: 0.1075, Accuracy: 9678/10000 (97%)
Train Epoch: 11 [0/60000 (0%)] Loss: 0.110555
Train Epoch: 11 [6400/60000 (11%)] Loss: 0.185066
Train Epoch: 11 [12800/60000 (21%)] Loss: 0.154370
Train Epoch: 11 [19200/60000 (32%)] Loss: 0.187331
Train Epoch: 11 [25600/60000 (43%)] Loss: 0.103054
Train Epoch: 11 [32000/60000 (53%)] Loss: 0.097087
Train Epoch: 11 [38400/60000 (64%)] Loss: 0.094759
Train Epoch: 11 [44800/60000 (75%)] Loss: 0.254946
Train Epoch: 11 [51200/60000 (85%)] Loss: 0.163511
Train Epoch: 11 [57600/60000 (96%)] Loss: 0.375709
Test set: Average loss: 0.1001, Accuracy: 9702/10000 (97%)
Train Epoch: 12 [0/60000 (0%)] Loss: 0.085661
Train Epoch: 12 [6400/60000 (11%)] Loss: 0.267067
Train Epoch: 12 [12800/60000 (21%)] Loss: 0.162384
Train Epoch: 12 [19200/60000 (32%)] Loss: 0.181441
Train Epoch: 12 [25600/60000 (43%)] Loss: 0.109263
Train Epoch: 12 [32000/60000 (53%)] Loss: 0.194257
Train Epoch: 12 [38400/60000 (64%)] Loss: 0.065200
Train Epoch: 12 [44800/60000 (75%)] Loss: 0.288888
Train Epoch: 12 [51200/60000 (85%)] Loss: 0.167924
Train Epoch: 12 [57600/60000 (96%)] Loss: 0.311067
Test set: Average loss: 0.0956, Accuracy: 9722/10000 (97%)
Train Epoch: 13 [0/60000 (0%)] Loss: 0.093631
Train Epoch: 13 [6400/60000 (11%)] Loss: 0.079958
Train Epoch: 13 [12800/60000 (21%)] Loss: 0.143489
Train Epoch: 13 [19200/60000 (32%)] Loss: 0.087933
Train Epoch: 13 [25600/60000 (43%)] Loss: 0.094754
Train Epoch: 13 [32000/60000 (53%)] Loss: 0.132700
Train Epoch: 13 [38400/60000 (64%)] Loss: 0.060542
Train Epoch: 13 [44800/60000 (75%)] Loss: 0.212000
Train Epoch: 13 [51200/60000 (85%)] Loss: 0.092904
Train Epoch: 13 [57600/60000 (96%)] Loss: 0.243191
Test set: Average loss: 0.0912, Accuracy: 9739/10000 (97%)
Train Epoch: 14 [0/60000 (0%)] Loss: 0.036139
Train Epoch: 14 [6400/60000 (11%)] Loss: 0.185927
Train Epoch: 14 [12800/60000 (21%)] Loss: 0.094324
Train Epoch: 14 [19200/60000 (32%)] Loss: 0.129941
Train Epoch: 14 [25600/60000 (43%)] Loss: 0.099867
Train Epoch: 14 [32000/60000 (53%)] Loss: 0.175463
Train Epoch: 14 [38400/60000 (64%)] Loss: 0.075817
Train Epoch: 14 [44800/60000 (75%)] Loss: 0.191533
Train Epoch: 14 [51200/60000 (85%)] Loss: 0.105866
Train Epoch: 14 [57600/60000 (96%)] Loss: 0.255987
Test set: Average loss: 0.0875, Accuracy: 9751/10000 (98%)
Train Epoch: 15 [0/60000 (0%)] Loss: 0.049678
Train Epoch: 15 [6400/60000 (11%)] Loss: 0.185887
Train Epoch: 15 [12800/60000 (21%)] Loss: 0.064999
Train Epoch: 15 [19200/60000 (32%)] Loss: 0.106103
Train Epoch: 15 [25600/60000 (43%)] Loss: 0.052213
Train Epoch: 15 [32000/60000 (53%)] Loss: 0.136051
Train Epoch: 15 [38400/60000 (64%)] Loss: 0.037222
Train Epoch: 15 [44800/60000 (75%)] Loss: 0.152106
Train Epoch: 15 [51200/60000 (85%)] Loss: 0.140182
Train Epoch: 15 [57600/60000 (96%)] Loss: 0.216424
Test set: Average loss: 0.0850, Accuracy: 9757/10000 (98%)
如何运行这段代码: 不要在Jupyter笔记上直接运行 请将左侧的 `experiments/mnist/train.py` 文件下载到本地 安装相关依赖包: pip install torch torchvision 运行:python3 train.py
尝试 在 HuggingFace 上找一个简单的数据集,自己实现一个训练过程
|










