|
面壁一直都在做端侧大模型,之前有文本系列MiniCPM-2B模型,还有多模态系列的MiniCPM-V系列模型,今天又开源了MiniCPM3-4B模型,真是端侧一路走到低。
这次MiniCPM3-4B也是在效果上有了巨大的提升,超过Phi-3.5-mini-Instruct模型,肩比Llama3.1-8B-Instruct、GLM-4-9B-Chat、Qwen2-7B-Instruct等一众模型,堪称小模型之王。 之前的MiniCPM-2B模型报告也是干活满满,详见:https://shengdinghu.notion.site/MiniCPM-c805a17c5c8046398914e47f0542095a 这里说一下哈,MiniCPM-2B是1.0版本模型,MiniCPM-1B是2.0版本模型,现在是3.0版本4B。 模型改进下面是3个版本的模型结构(1->2->3)的区别: - 注意力机制:MHA->GQA->MLA,MLA也是DeepSeek-V2的核心创新
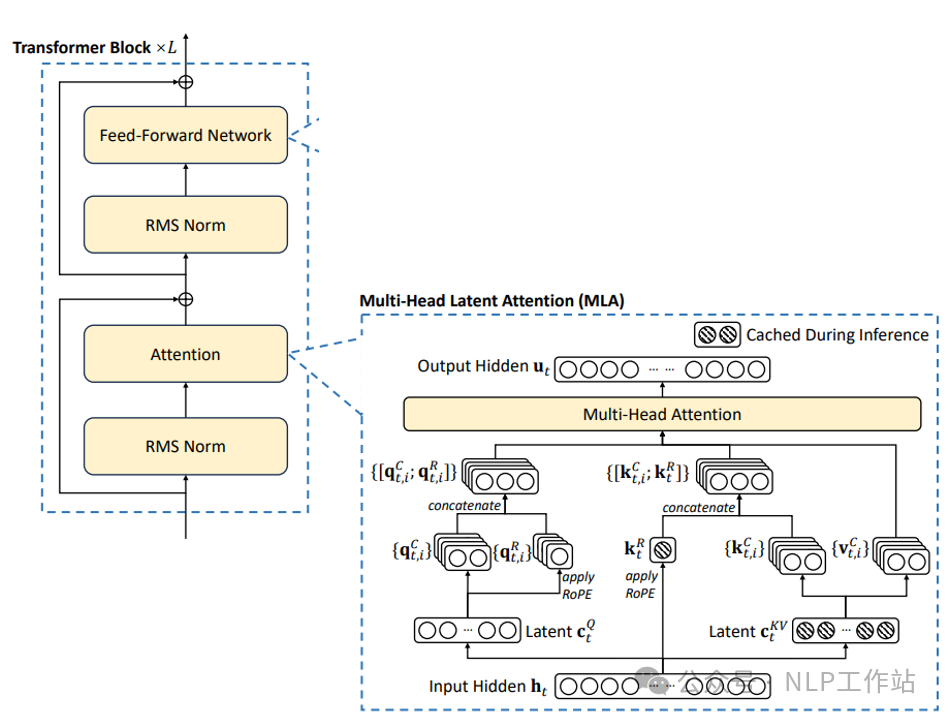
同时,还发布了RAG套件MiniCPM-Embedding模型和MiniCPM-Reranker模型,针对 RAG场景还发布了微调版MiniCPM3-RAG-LoRA模型。 模型效果MiniCPM3-4B模型在中文英文遵循、数据推理、代码能力、工具调用上表现均很不错的效果。 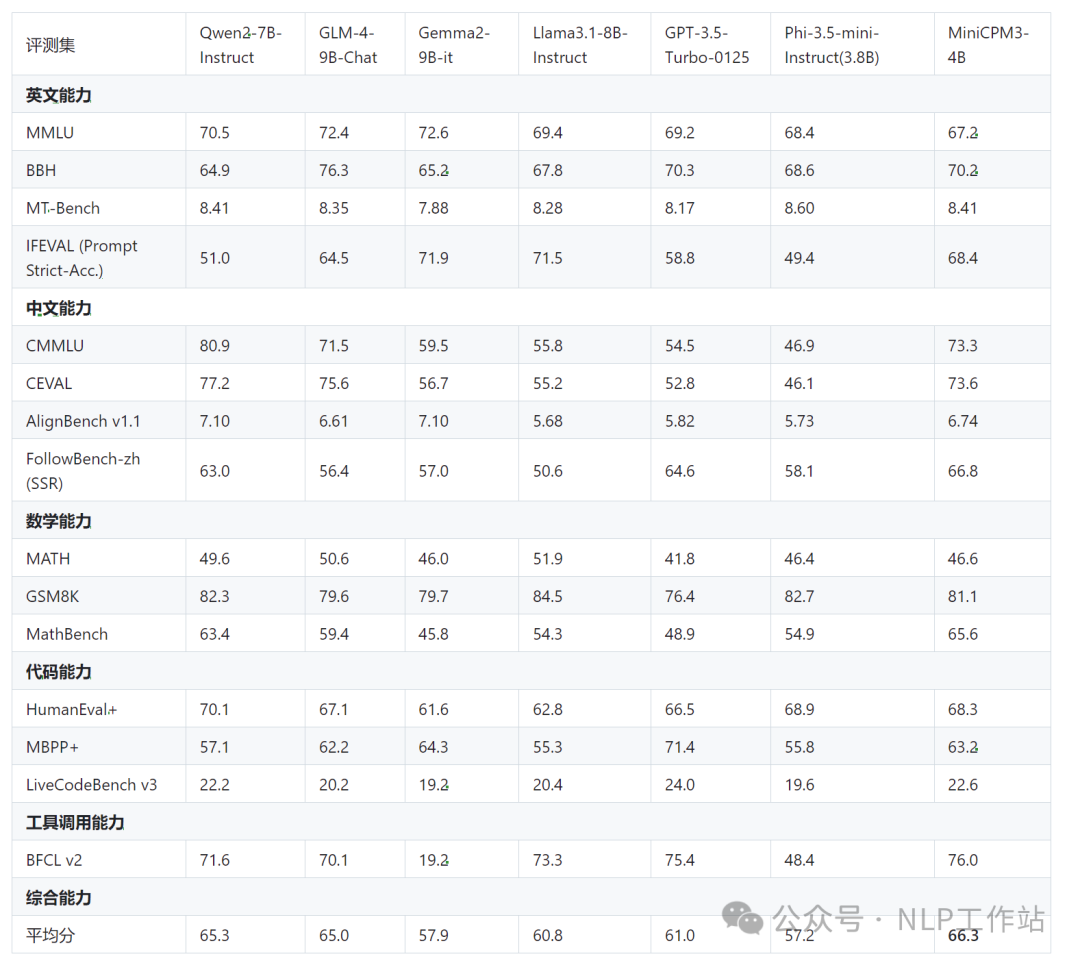 其中,工具调用能力尤为突出,在Berkeley Function Calling Leaderboard上优于Llama3.1-8B-Instruct、GLM-4-9B-Chat、Qwen2-7B-Instruct等更大模型。 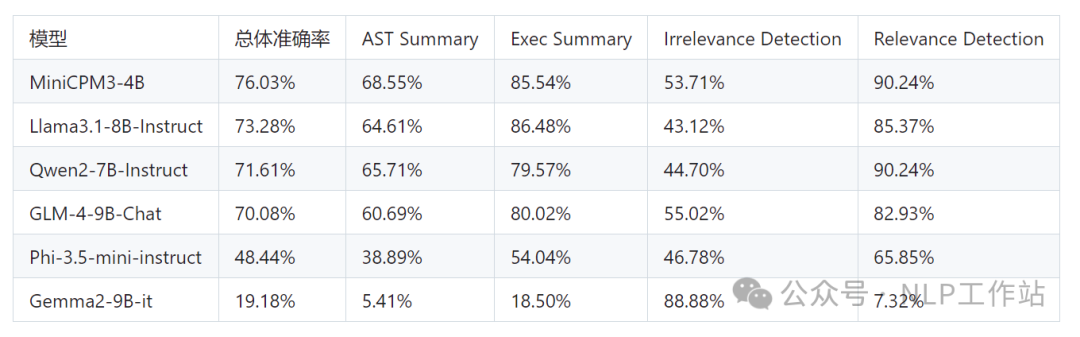 长文档的大海捞针也是全绿。 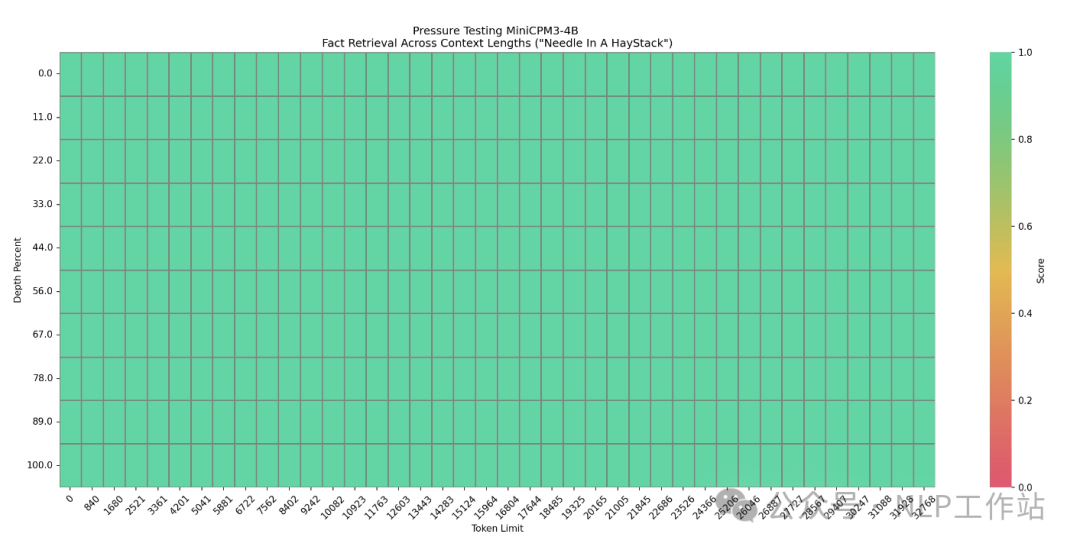 模型快速使用PS:模型下载有困难的同学,详见我之前写的一篇文章《大模型下载使我痛苦》。 fromtransformersimportAutoModelForCausalLM,AutoTokenizer
importtorch
#模型加载
path="openbmb/MiniCPM3-4B"
tokenizer=AutoTokenizer.from_pretrained(path,trust_remote_code=True)
model=AutoModelForCausalLM.from_pretrained(path,torch_dtype=torch.bfloat16,device_map="cuda",trust_remote_code=True)
#输入构造
messages=[
{"role":"user","content":"你知道刘聪NLP是谁吗?"},
]
model_inputs=tokenizer.apply_chat_template(messages,return_tensors="pt").to("cuda")
#模型生成
model_outputs=model.generate(
model_inputs,
max_new_tokens=1024,
top_p=0.8,
temperature=0.9,
repetition_penalty=1.1
)
#模型解码
output_token_ids=[
model_outputs[i][len(model_inputs[i]):]foriinrange(len(model_inputs))
]
responses=tokenizer.batch_decode(output_token_ids,skip_special_tokens=True)[0]
print(responses)
| 









