在前面的文章里,我们介绍了很多有关提示工程的前沿技术与工具,它们都揭示了一个共识性方向,就是提示工程不仅仅是人机对话的语言艺术,更是一个持续迭代优化的系统性软件工程。近日,OpenAI前研究科学家william对外正式开源了一个号称面向未来的提示工程库,名为ell[1],它将提示视为函数,并提供了一系列强大的工具来优化和管理提示。提示是程序,而不是字符串在传统的提示工程中,我们通常将提示视为简单的字符串。然而,ell颠覆了这一观念,将提示视为程序。通过这种方式,我们可以将提示封装成独立的子程序,称为语言模型程序(Language Model Program, LMP)。这些 LMP 是完全封装的函数,可以生成字符串提示或消息列表,发送到各种多模态语言模型。让我们从一个传统的 API 调用示例开始,看看如何使用ell实现相同的功能。以下是使用 OpenAI Chat Completion API 的简单示例:importopenai
openai.api_key="your-api-key-here"
messages=[
{"role":"system","content":"Youareahelpfulassistant."},
{"role":"user","content":"SayhellotoSamAltman!"}
]
response=openai.ChatCompletion.create(
model="gpt-4o",
messages=messages
)
print(response['choices'][0]['message']['content'])
importell
@ell.simple(model="gpt-4o")
defhello(name:str):
"""Youareahelpfulassistant."""#系统提示
returnf"Sayhelloto{name}!"#用户提示
greeting=hello("SamAltman")
print(greeting)
ell通过鼓励你将提示定义为功能单元来简化提示。在这个示例中,hello函数通过文档字符串定义系统提示,通过返回字符串定义用户提示。提示的用户只需调用定义的函数,而不需要手动构建消息。在此基础上,我们可以进一步地改进提示。importell
importrandom
defget_random_adjective():
adjectives=["enthusiastic","cheerful","warm","friendly"]
returnrandom.choice(adjectives)
@ell.simple(model="gpt-4o")
defhello(name:str):
"""Youareahelpfulassistant."""
adjective=get_random_adjective()
returnf"Saya{adjective}helloto{name}!"
greeting=hello("SamAltman")
print(greeting)
在这个示例中,我们的helloLMP 依赖于get_random_adjective函数。每次调用hello时,它都会生成一个不同的形容词,创建动态、多样的提示。显然,ell可使提示更具可读性、可维护性和可重用性。提示工程是一个优化过程提示工程的过程类似于机器学习中的优化过程,需要多次迭代。由于 LMP 只是函数,ell提供了丰富的工具来支持这一过程。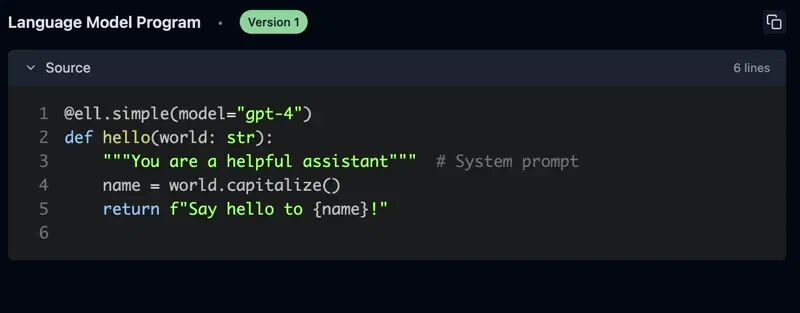
ell通过静态和动态分析,提供了提示的自动版本控制和序列化,并生成自动提交消息到本地存储。这一过程类似于机器学习训练中的检查点,但不需要特殊的 IDE 或编辑器——只需使用常规的 Python 代码即可。importell
ell.init(store='./logdir')#版本控制你的LMP和它们的调用
#定义你的LMP
hello("strawberry")#LMP的源代码和调用被保存到存储中
同时,ell提供了一个名为 Ell Studio 的本地开源工具,可用于提示版本控制、监控和可视化。通过 Ell Studio,你可以将提示优化过程科学化,并在问题出现之前捕捉到回归。ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;">优雅实现测试时计算ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;">从演示到实际应用,通常需要多次调用语言模型。这不仅仅是简单的字符串拼接,而是一个复杂的编程过程。通过强制功能分解问题,ell使得在可读和模块化的方式中实现测试时计算变得容易。![]() ingFang SC", system-ui, -apple-system, system-ui, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;letter-spacing: normal;text-wrap: wrap;height: auto !important;" src="https://api.ibos.cn/v4/weapparticle/accesswximg?aid=89159&url=aHR0cHM6Ly9tbWJpei5xcGljLmNuL21tYml6X2pwZy9hYU4yeGRGcWE0RTNQSjRJY1FXWTh0RGZLZnBqVXdrZ2tEcHBMb1ZhNUpXWkJZRVFrbnZGcEZjOGFSYVppY2lhY2NDdjRpYU1yWk9wRklYRTNLNkg5dkpndy82NDA/d3hfZm10PWpwZWcmYW1w;from=appmsg"/> ingFang SC", system-ui, -apple-system, system-ui, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;letter-spacing: normal;text-wrap: wrap;height: auto !important;" src="https://api.ibos.cn/v4/weapparticle/accesswximg?aid=89159&url=aHR0cHM6Ly9tbWJpei5xcGljLmNuL21tYml6X2pwZy9hYU4yeGRGcWE0RTNQSjRJY1FXWTh0RGZLZnBqVXdrZ2tEcHBMb1ZhNUpXWkJZRVFrbnZGcEZjOGFSYVppY2lhY2NDdjRpYU1yWk9wRklYRTNLNkg5dkpndy82NDA/d3hfZm10PWpwZWcmYW1w;from=appmsg"/>
importell
@ell.simple(model="gpt-4o-mini",temperature=1.0,n=10)
defwrite_ten_drafts(idea:str):
"""Youareanadeptstorywriter.Thestoryshouldonlybe3paragraphs"""
returnf"Writeastoryabout{idea}."
@ell.simple(model="gpt-4o",temperature=0.1)
defchoose_the_best_draft(drafts ist[str]): ist[str]):
"""Youareanexpertfictioneditor."""
returnf"Choosethebestdraftfromthefollowinglist:{'\\n'.join(drafts)}."
drafts=write_ten_drafts(idea)
best_draft=choose_the_best_draft(drafts)#从10个草稿中选择最佳草稿
ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: normal;text-align: left;text-wrap: wrap;">测试时计算(Test-Time Computation)是机器学习和深度学习中的一个概念,指的是在模型推理阶段(也就是测试时)进行额外的计算或处理,以提高模型的性能或适应性。这种方法通常用于解决训练数据和测试数据之间存在差异的问题,或者在不重新训练模型的情况下提高模型的泛化能力。其核心思路是不重新训练模型,而是在模型实际使用时进行额外的处理,以提高模型的表现。类似于人类在应用所学知识时会根据具体情况做出适当灵活变通处理,而不是僵化执行。 ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: normal;text-wrap: wrap;background-color: rgb(255, 255, 255);">每次调用语言模型都很重要
每次调用语言模型都非常宝贵,值得跟踪分析。在实践中,LLM 调用用于微调、蒸馏、k-shot 提示、从人类反馈中进行强化学习等。一个好的提示工程系统应该将这些作为一等公民概念捕捉。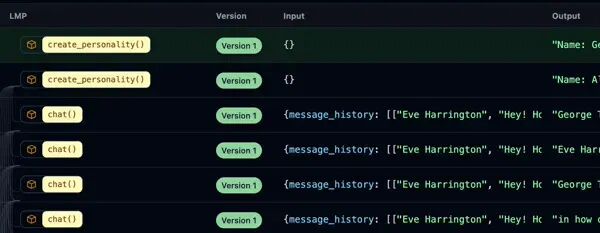
除了存储每个 LMP 的源代码外,ell还可以选择性地本地保存每次调用语言模型的记录。这使你能够生成调用数据集,比较不同版本的 LMP 输出,并充分利用提示工程的所有工件。需要时复杂,不需要时简单使用语言模型通常只是传递字符串,但有时需要更复杂的输出。ell提供了@ell.simple和@ell.complex装饰器,分别用于生成简单字符串输出和复杂的消息对象响应。importell
@ell.tool()
defscrape_website(url:str):
returnrequests.get(url).text
@ell.complex(model="gpt-5-omni",tools=[scrape_website])
defget_news_story(topic:str):
return[
ell.system("""Usethewebtofindanewsstoryaboutthetopic"""),
ell.user(f"Findanewsstoryabout{topic}.")
]
message_response=get_news_story("stockmarket")
ifmessage_response.tool_calls:
fortool_callinmessage_response.tool_calls:
#处理工具调用
pass
ifmessage_response.text:
print(message_response.text)
ifmessage_response.audio:
#message_response.play_audio()支持多模态输出
pass
多模态是一等公民LLM 可以处理和生成各种类型的内容,包括文本、图像、音频和视频。使用这些数据类型进行提示工程应该像处理文本一样简单。fromPILimportImage
importell
@ell.simple(model="gpt-4o",temperature=0.1)
defdescribe_activity(image:Image.Image):
return[
ell.system("YouareVisionGPT.Answer<5wordsalllowercase."),
ell.user(["Describewhatthepersonintheimageisdoing:",image])
]
#从摄像头捕捉图像
describe_activity(capture_webcam_image())#输出:"theyareholdingabook"
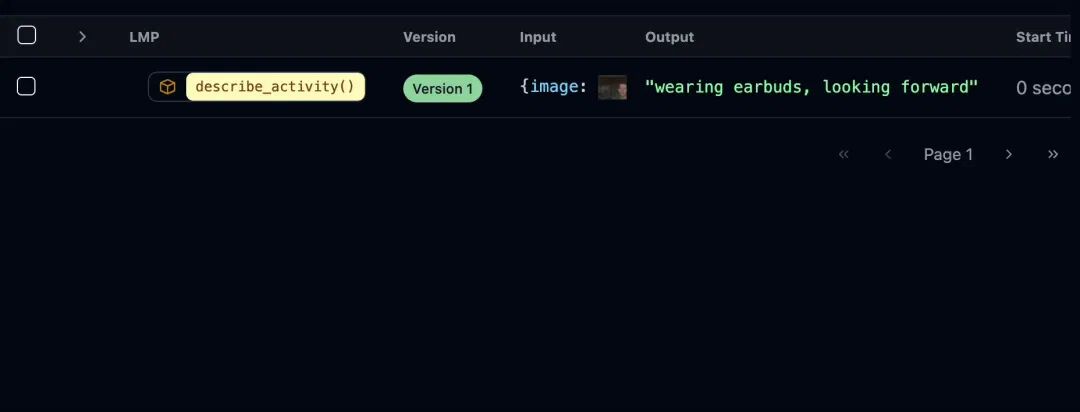
ell支持多模态输入和输出的丰富类型转换。你可以在 LMP 返回的Message对象中内联使用 PIL 图像、音频和其他多模态输入。提示工程库不干扰你的工作流程ell设计为一个轻量级且不干扰的库。它不要求你改变编码风格或使用特殊的编辑器。
你可以继续在你的 IDE 中使用常规的 Python 代码来定义和修改提示,同时利用ell的功能来可视化和分析你的提示。你可以逐步从 langchain 迁移到ell,一次一个函数。结语ell通过将提示视为函数,并提供一系列强大的工具,重新定义了提示工程。它不仅简化了提示的创建和管理过程,还使得提示优化变得科学化和系统化。无论你是提示工程的新手还是经验丰富的专家,ell都能为你提供有价值的支持。
|










