|
在 AI 领域,有两大场景对 GPU 的需求最大,一个是模型训练,另一个是 AI 推理任务。但是很多人多可能在最开始为自己的项目做 GPU 选型时,都很难判断哪些 GPU 适合做模型训练,哪些 GPU 更适合去做推理任务。所以我们通过这篇文章将基于 GPU 指标来帮助大家对比分析NVIDIA 的 H100、A100、A6000、A4000、V100、P6000、RTX 4000、L40s、L4 九款GPU,哪些更推荐用于模型训练,哪些则更推荐用于推理。 推理、训练对 GPU 的要求有什么不同要想了解不同 GPU 更适合哪些业务,我们需要先从不同业务对 GPU 的要求来分析。大语言模型(LLM)的训练和 AI 推理任务对 GPU 的需求是有不同的侧重点的,以下是主要的区别: 1. 计算能力需求:训练:训练过程涉及大量的矩阵运算和梯度计算,因此需要强大的计算能力,尤其是浮点数的运算性能。训练大模型(如GPT-3、GPT-4)需要多个GPU,并且要求GPU的计算能力越高越好,通常使用FP16或TF32等混合精度进行加速计算。 推理:推理时虽然也需要计算能力,但相较于训练时的计算负载要低得多。推理的重点在于高效地执行前向传播,而无需进行反向传播和梯度计算。单个GPU通常可以满足推理需求,除非是高并发或超大规模的部署。
2. 内存需求(显存):训练:训练过程需要大量显存,特别是对于大模型和大批量的训练数据。显存需要存储模型的参数、激活值、梯度、优化器状态等。显存不足时需要使用梯度累积、分布式训练或模型并行等技术来分摊显存压力。 推理:大型深度学习模型(如GPT、BERT等)通常需要较大的显存来加载和运行。一般来说,小批量推理任务一般只需要较少的显存,但如果是大批量推理或并发推理,显存需求也会很高。如果显存不足,可能需要频繁地将模型切换到CPU,这会显著降低推理速度。
3. 带宽需求:训练:训练过程中,数据需要在GPU和主存之间频繁交换,特别是在多GPU分布式训练场景下,GPU之间的通信(如通过NVLink或PCIe)需要高带宽,以保持数据同步和梯度传输的效率。因此,带宽对训练影响较大。同时,NVLink 作为 NVIDIA 推出的技术,其数据交互效率要优于 PCIe,所以在选择 GPU 的时候,如果需要多卡并行,那么最好选择支持 NVLink 的 GPU,比如 H100、A100、V100 等。 推理:推理对带宽的要求相对较低,因为推理过程中数据主要在GPU内部处理,只有在输入输出数据时才需要与主存或其他GPU通信。
4. 功耗管理:
5. 模型并行与分布式计算:
总之,训练任务更侧重于GPU的计算能力、显存大小和带宽,通常需要多个GPU协同工作,并对功耗管理要求更严格;而推理任务则更关注响应速度和效率,对GPU的计算能力和显存要求较低,通常使用单GPU即可,但在高并发场景下仍对带宽和显存有一定需求。 主流几款 GPU 中哪些适合推理?哪些适合训练?那么进行一下指标对比,在 NVIDIA H100、A100、A4000、A6000、V100、P6000、RTX 4000、L40s、L4,这几个GPU 中,分析哪些 GPU更适合 做模型训练任务,哪些 GPU 更适合做推理任务。 以下是NVIDIA H100、A100、A6000、A4000、V100、P6000、RTX 4000、L40s、L4的主要性能指标参数表: 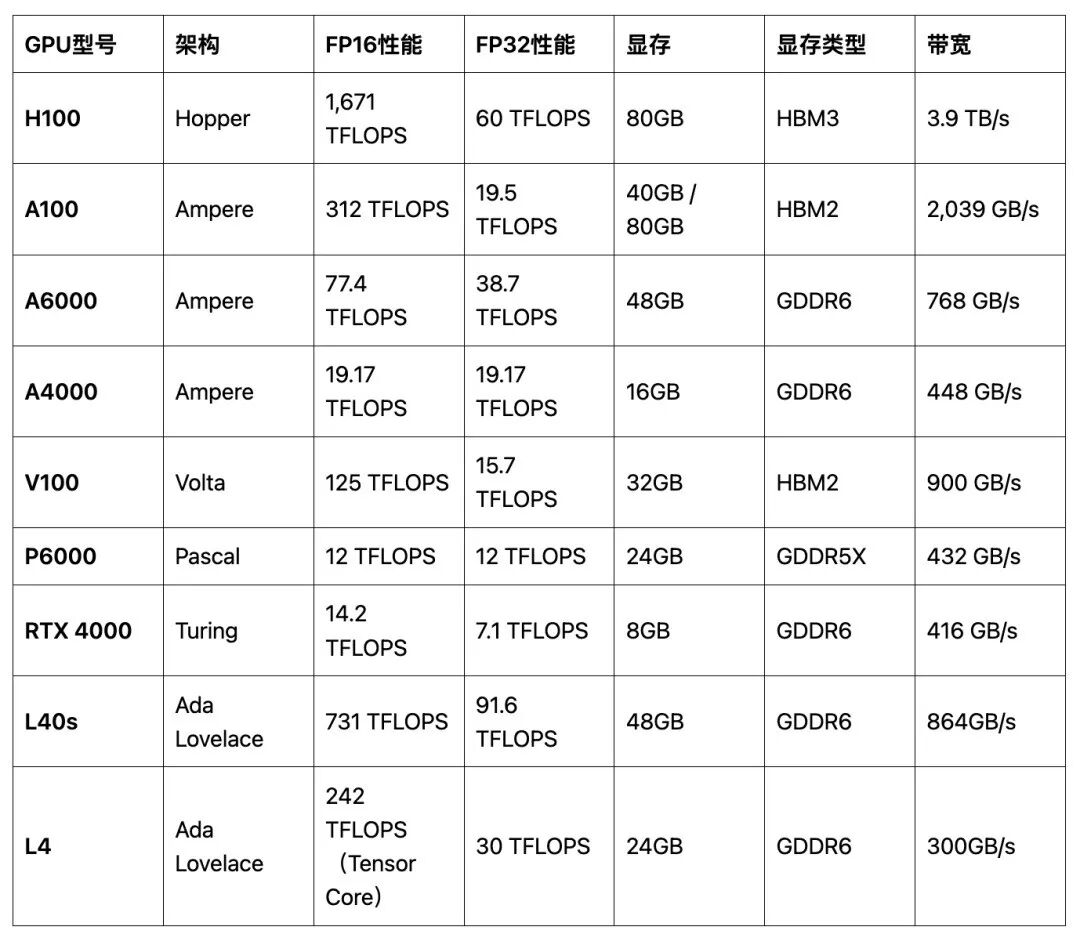
这个表格总结了每个GPU的架构、FP16/FP32计算性能、Tensor Core性能、显存大小、显存类型以及内存带宽,便于比较各个GPU在不同任务场景中的适用性。按照架构来讲,越新的架构肯定性能相对更好,这些架构从旧到新依次是: Pascal(2016年发布) Volta(2017年发布) Turing(2018年发布) Ampere(2020年发布) Ada Lovelace(2022年发布)
在选择用于大语言模型(LLM)训练和推理的GPU时,不同GPU有着各自的特性和适用场景。NVIDIA系列的多款GPU在AI计算领域表现出色,包括高性能的H100、A100、V100,以及更为主流的A6000、A4000等。以下将对这些GPU进行分析,探讨它们在模型训练和推理任务中的优劣势,帮助明确不同GPU的应用场景。 1. NVIDIA H100适用场景:
2. NVIDIA A100适用场景:
3. NVIDIA A6000适用场景:
4. NVIDIA A4000适用场景:
5. NVIDIA V100适用场景:
6. NVIDIA P6000适用场景:
7. NVIDIA RTX 4000适用场景:
8. NVIDIA L40s适用场景:
9.NVIDIA L4适用场景:
结论- H100 和 A100 是目前训练大规模模型(如GPT-3、GPT-4等)的最佳选择,拥有顶级的计算能力、显存和带宽。H100在性能上超越了A100,但A100仍然是当前大规模AI训练中的主力。
- V100 仍然是中型模型训练的可靠选择,尤其适合在预算有限的情况下使用。
- A6000 可以在工作站环境中进行中小型模型的训练。
- ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">A6000 和 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">L40s 是推理任务的理想选择,提供了强大的性能和显存,能够高效处理大模型的推理。
- ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">A100 和 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">H100 在超大规模并发或实时推理任务中表现优异,但由于其高成本,通常只在特定场景中使用。
- ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">A4000 和 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">RTX 4000 则适合中小型推理任务,是经济实惠的选择。
- ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 14px;letter-spacing: 0.034em;">L4 非常适合高效推理场景,尤其是在图像、视频等应用中需要高效能推理的场景。它在性能和能效比之间达到了很好的平衡,成为性价比推理GPU的优秀选择。
另外,我们还提到了 NLink 技术。NVLink 通常存在于高端和数据中心级 GPU,像 A4000、RTX 4000 、L4 和 L40s 这样的专业卡以及 P6000 这类较老的 GPU 则不具备 NVLink 支持。所以这几款 GPU 就不太适合去做大型模型的训练任务,因为大型模型的训练都需要多卡并行或分布式计算,在这种情况下如果缺少 NLink 的支持,是不行的。所以这里更推荐把这些卡用于推理任务。在这里,我们比较的不仅仅有早期发布的 GPU,还有现在比较前沿的 GPU,比如 H100。像 H100 这种 GPU 实际上既适合做模型训练,也适合做推理,但是 H100 的成本会比较高,性能也比较好,如果用在推理方面难免有些大材小用。所以我们以上给出的结论都是基于指标层面的,实际上大家还需要结合成本来看。大家可以参考 DigitalOcean 旗下 Paperspace 的 GPU 云服务定价来看,单卡GPU 实例的价格如下: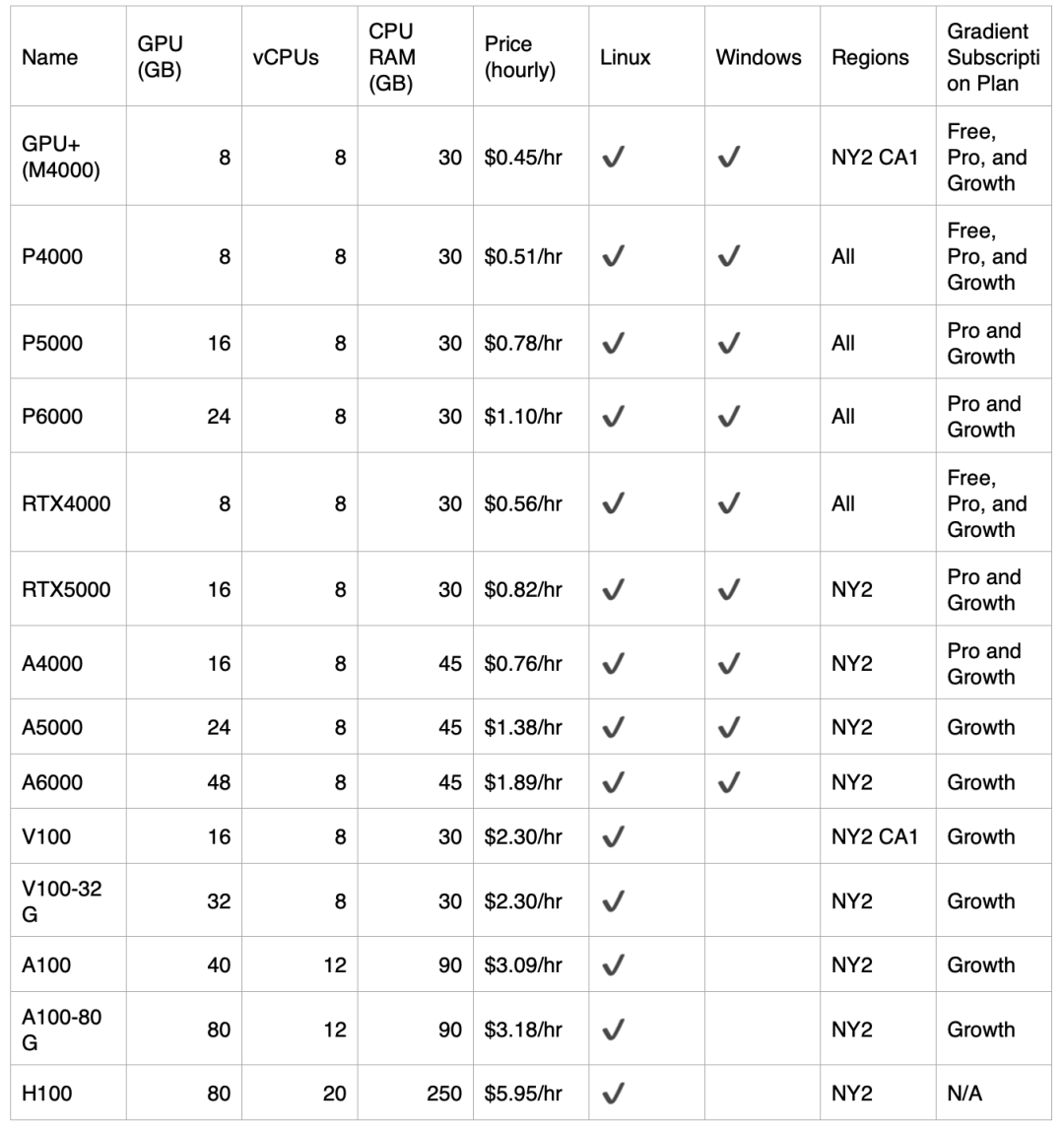
|










