|
我们以前介绍了HybridRAG、GraphRAG这些,今天我们将介绍一个崭新的RAG项目:LightRAG。 现有的RAG系统老是搞不清复杂关系,答案经常被切碎,缺乏上下文,难以真正理解问题。而LightRAG就是来解决这些问题的,它把图结构引入文本索引和检索,采用双层检索系统,从低到高全面覆盖信息。更酷的是,它还能快速更新数据,保持实时高效的响应,而且它已经开源了哦! 并且你现在可以通过简单的API调用来实现多种检索模式,包括本地、全局和混合检索。 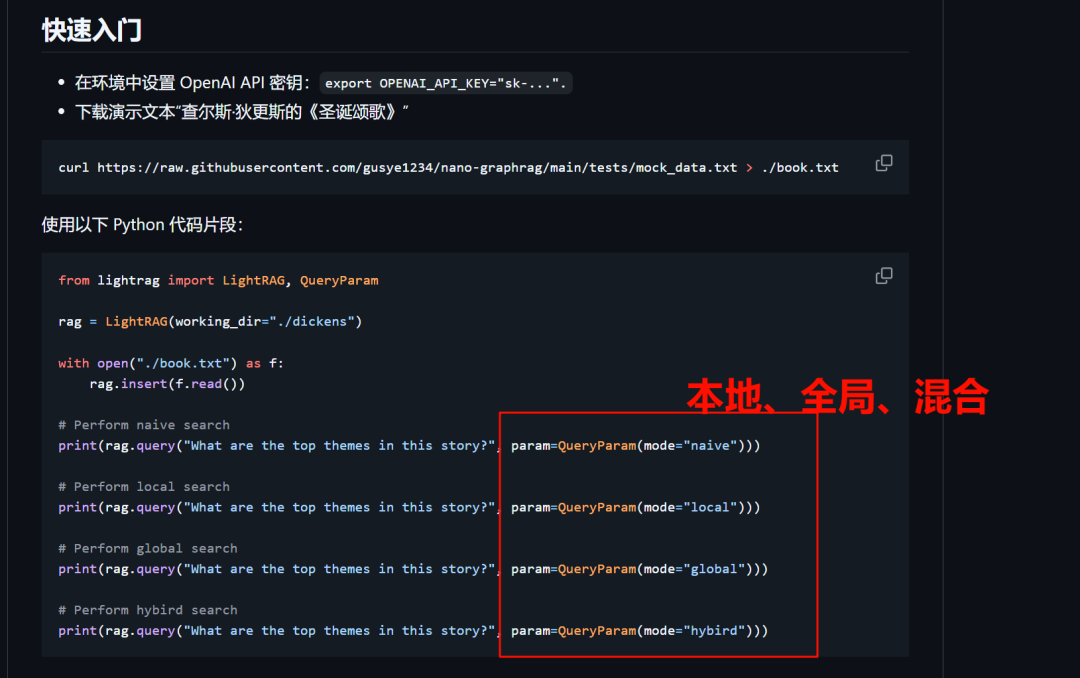
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;padding-left: 12px;color: rgb(63, 63, 63);">LightRAG 的工作流程分为三个核心部分:
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;color: rgb(63, 63, 63);" class="list-paddingleft-1">1.图基文本索引(Graph-Based Text Indexing) 2.双层检索范式(Dual-Level Retrieval Paradigm) 3.增量知识库的快速适应ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: inherit;letter-spacing: 0.034em;text-align: justify;text-shadow: rgb(123, 123, 123) 0px 0px;border-width: 0px;border-style: solid;border-color: hsl(var(--border));line-height: 1.75;color: rgb(0, 152, 116);"> ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;color: rgb(0, 152, 116);">一、图基文本索引ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;color: rgb(63, 63, 63);" class="list-paddingleft-1">•步骤 1:实体和关系提取 •步骤 2:LLM Profiling 生成键值对 •步骤 3:去重优化 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;color: rgb(0, 152, 116);">二、双层检索范式ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;color: rgb(63, 63, 63);" class="list-paddingleft-1">•步骤 4:生成查询关键词 •步骤 5:关键词匹配 •步骤 6:整合高阶相关性 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;color: rgb(0, 152, 116);">三、检索增强的答案生成ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;color: rgb(63, 63, 63);" class="list-paddingleft-1">•步骤 7:使用检索到的信息 •步骤 8:上下文整合与答案生成 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;color: rgb(0, 152, 116);">四、增量知识库的快速适应•步骤 9:增量更新知识库 •步骤 10:减少计算开销

通过这些步骤,LightRAG 实现了更精准、更高效、更具上下文关联的知识检索和答案生成,特别是对复杂问题的解决和大规模数据处理具有显著优势。 LightRAG 架构实例解释 LightRAG 主要通过以下几个步骤来让信息检索更准确、更智能: 1.从文本中提取信息:系统会读取文档,识别出重要的“实体”(比如人、地点、事物)和它们之间的“关系”(比如某人属于某组织,某事物位于某地)。
2.去掉重复信息:系统会去除文档中相同的实体和关系,避免不必要的重复。这样可以减轻系统的负担,提高效率。 3.把信息放入图表:这些提取出来的实体和关系会被放入一个“图”中。在这个图里,实体是“节点”,关系是“边”,所有的节点和边相连形成了一个可以高效查询的信息网络。 4.双层检索:当用户提问时,系统会分两步进行检索。首先,它会寻找与问题直接相关的“局部关键词”(如“Beekeeper”),然后它会寻找与这些关键词关联的“全局关键词”(如“Bee”、“Hive(蜂巢)”等)。 5.生成答案:系统结合检索到的信息,利用大语言模型(LLM)生成详细的答案,并且确保答案逻辑连贯、信息准确。 6.知识更新:当有新的信息加入时,系统会把新信息无缝整合到已有的图中,确保系统总是基于最新的知识进行检索,而不会每次都重建整个系统。 这张图表可以理解为整个过程的可视化,它展示了从识别实体到检索再到生成答案的完整流程。 
面对问题“哪些指标最适合评估电影推荐系统?”时,LLM首先提取低层次和高层次的关键词,用这些关键词在生成的知识图谱上检索相关的实体和关系。检索到的信息被组织成三个部分:实体、关系和相应的文本片段。然后,这些结构化的数据被送入LLM,帮助它生成一个全面的答案。 
LightRAG在四个数据集/评估维度上都显示出了显著的改进,效果优于GraphRAG、NaiveRAG、RQ-RAG 、HyDE。 
▲在四个数据集和四个评估维度下,基线与LightRAG的胜率(%)对比 LightRAG 的代码结构基于nano-graphrag,一个更小、更快的GraphRAG。 
LightRAG 论文:https://arxiv.org/abs/2410.05779 
▲基于Claude生成的论文摘要卡
|










