ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);text-align: left;visibility: visible;">
科大讯飞在年初时提到 2024 年大模型目标1亿软件用户 智能涌现需要的 大模型参数规模越来越大 科大讯飞已经迈过第一道门槛
一万困难户,十万刚起步,百万才算富 Meta 超越 xAI 计划打造全球最大 GPU 集群
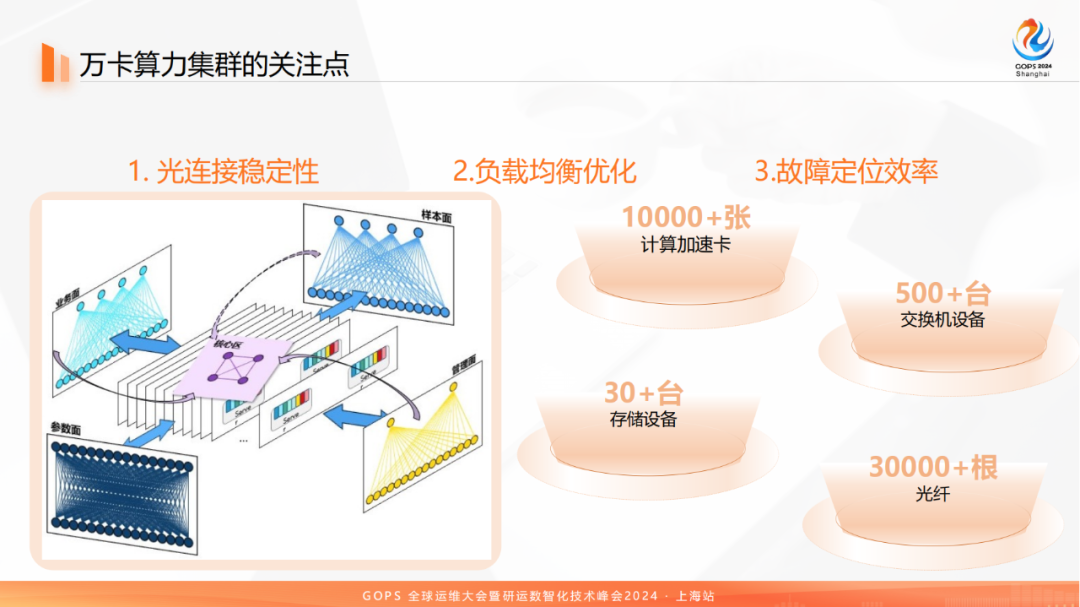
预训练阶段在大规模 未标注数据集上进行自监督学习 因此对于模型的训练效果有着重要的影响 Meta 公开基于 RoCE 技术的 24 K GPU 集群!关于智算系统与通信方法,某司申请重要专利 | 









