|
前面文章提到,文档智能解析能够有效的增强RAG系统的准确性。【文档智能 & RAG】RAG增强之路:增强PDF解析并结构化技术路线方案及思路  可以看到基于PDF的RAG,需要先对pdf进行解析,生成文本chunk,然后再基于文本建索引。这种pipline的方式,每个解析模块都需要放置对应的解析模型,存在着错误传播的问题。因此,笔者看到ColPali时,这种端到端的方案挺有意思,本文来看一看这个思路。 ColBERT在此之前,先看一下ColBERT的架构,该架构包括:查询编码器、文档编码器和后期交互机制。 查询编码器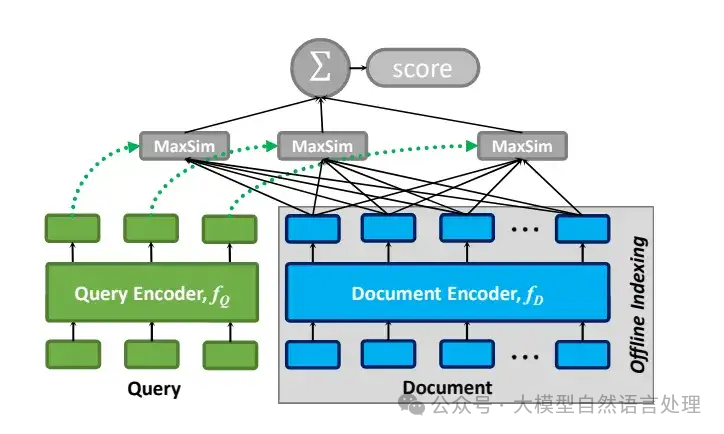 假设有一个查询,其标记(token)为,处理步骤如下: - 将转换为 BERT 使用的 WordPiece 标记 (一种子词分词方法)。
- 在序列开头添加一个特殊的[Q]标记,紧随 BERT 的[CLS]标记之后,用于标识查询的开始。
- 如果查询长度不足预设的个标记,用[mask]标记填充;若超过则截断。
- 将处理后的序列输入 BERT,然后通过CNN处理,最后进行归一化。
最终输出的查询嵌入向量集合可表示为: 文档编码器对于包含标记的文档,处理步骤类似: 文档嵌入向量集合 Ed 可表示为: Filter用于去除与标点符号对应的嵌入,从而提升分析速度。这里的查询填充策略(论文中称为"查询增强")确保了所有查询长度一致,有利于批量处理。而[Q]和[D]标记则帮助模型区分输入类型,提高了处理效率。 后期交互机制“交互”是指通过比较查询和文档的向量表示来评估它们之间的相关性。“后期交互”表示这种比较发生在查询和文档已经被独立编码之后。这种方法与BERT之类的“早期交互”模型不同——早期交互中查询和文档的Embedding在较早的阶段相互作用,通常是在编码之前或期间。 ColBERT采用了一种后期交互机制,使得查询和文档的表示可以用于预计算。然后,在末尾使用简化的交互步骤来计算已编码的向量列表之间的相似性。与早期交互方法相比,后期交互可以加快检索时间和降低计算需求,适用于需要高效处理大量文档的场景。 编码器将查询和文档转换为token级别的embedding列表和。然后,后期交互阶段使用针对每个中的向量,找与其产生最大内积的中的向量(即为向量之间的相似性),并将所有分数求和的最大相似性 (MaxSim) 计算。MaxSim的计算结果就反映了查询与文档之间的相关性分数,表示为。 这种方法的独特价值在于能够对查询与文档token embedding之间进行详细、细粒度的比较,有效捕捉查询和文档中长度不同的短语或句子之间的相似性。这尤其适合需要精确匹配文本片段的应用场景,可以提高搜索或匹配过程的整体准确性。 ColPali与 ColBERT 相比,ColPali 仍然使用文本作为查询,文档则是图像类型。在视觉encoder,也是利用多模态的视觉大模型来生成图片端的向量,但不仅仅只生成单个向量。而是利用VIT的patch embedding,来生成多个向量。直觉上确实是会有收益,因为一整页的pdf,只压缩在一个固定维度的向量中,那肯定有信息损失,而且以patch为单位生成embedding。  视觉语言模型ColPali选择PaliGemma-3B作为其视觉语言模型,这是一个相对较小的模型,具有多个针对不同图像分辨率和任务微调的检查点,并且在各种文档理解基准测试中表现出色。PaliGemma-3B的一个关键特性是其文本模型在前缀(指令文本和图像标记)上进行了全块注意力的微调。 为了生成轻量级的多向量表示,ColPali在PaliGemma-3B模型的基础上添加了一个投影层,将输出的语言建模嵌入映射到一个降低维度的向量空间中(D=128),这与ColBERT论文中使用的向量空间大小相同。 后期交互机制ColPali采用了和ColBERT 类似的后期交互机制,这是一种在检索时才进行的交互方式。给定查询和文档,它们的多向量表示在共同的嵌入空间RD中分别表示为和。后期交互操作符定义为查询向量与其在文档嵌入向量中的最大点积⟨·|·⟩的总和。 数学公式表示为: 通过这种方式,ColPali能够在检索时充分利用查询和文档之间的交互,同时保持了离线计算和快速查询匹配的优势。 对比损失对比损失通过对比正样本和负样本之间的差异来训练模型。在ColPali模型中,对比损失用于优化检索任务,使得模型能够学习区分与查询相关的文档和不相关的文档。 在ColPali模型的训练过程中,每个批次包含多个查询-文档对。对于每对查询和其对应的正样本文档,模型会计算一个正样本分数,这是通过后期交互操作得到的。同时,模型还会计算一个负样本分数,这是通过在批次中所有其他文档(即负样本)上执行晚期交互操作,并取最大值得到的。 其中: - 是查询q_k与其对应的正样本文档dk之间的正样本分数。
实验效果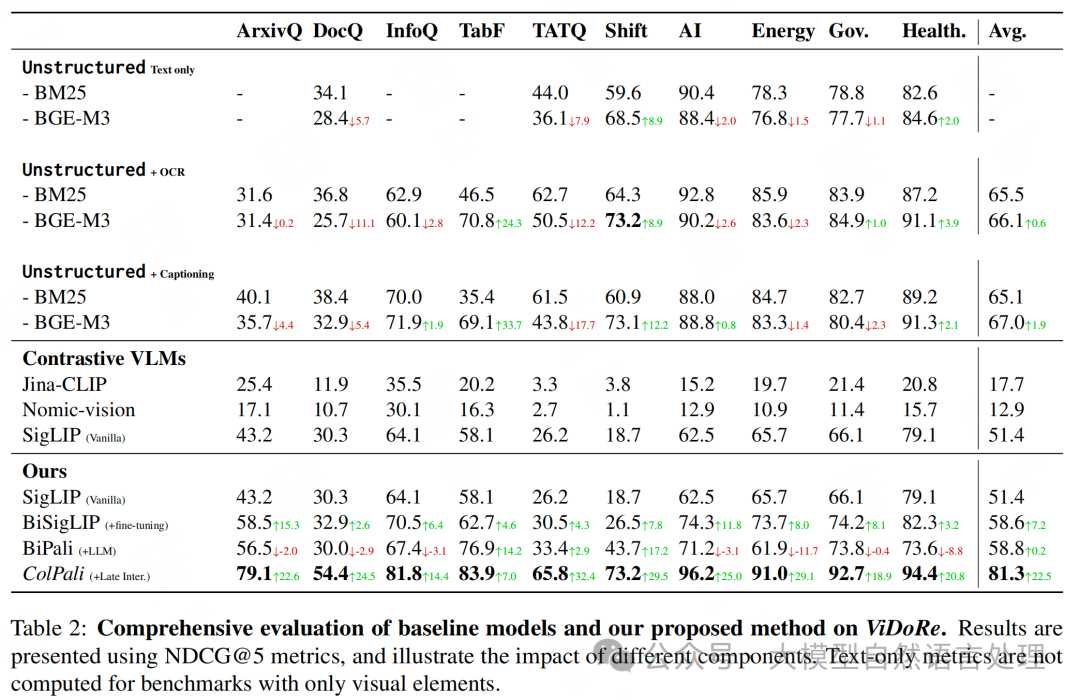
| 









