|
通过将外部知识与大语言模型(LLM)的集成,可以增强其在特定领域输出的专业性与时效性,减少幻觉问题,提高输出的可控性与可解释性。典型的方法如我们所熟知的RAG(Retrieval-Augmented Generation)应用与模型微调(Fine-tuning),都是常见的技术策略。 尽管随着RAG理论与技术的不断进步(如查询转换、融合检索、Agentic RAG、GraphRAG等),其表现已经愈趋成熟。但在实际应用中,输入任务的复杂性决定了很难存在单一技术可以一劳永逸的解决所有问题,从理解问题到检索数据、LLM推理等方面仍然存在诸多挑战,而这些挑战往往需要结合多种技术能力以更好的解决问题。
在微软的研究报告《Retrieval Augmented Generation (RAG) and Beyond: A ComprehensiveSurvey on How to Make your LLMs use External Data More Wisely》中,提出了一种对包括RAG在内的数据增强型LLM应用的查询任务的分层方法,将输入的查询任务根据需求分成了四个层次,对其进行了定义与解析,总结了不同层次的技术挑战与应对方案。本文将对其进行深入学习与理解。 根据复杂性与对数据的需求层次把输入的查询任务分成四个层次,不同的层次具有不同的任务目标、依赖数据、推理能力:
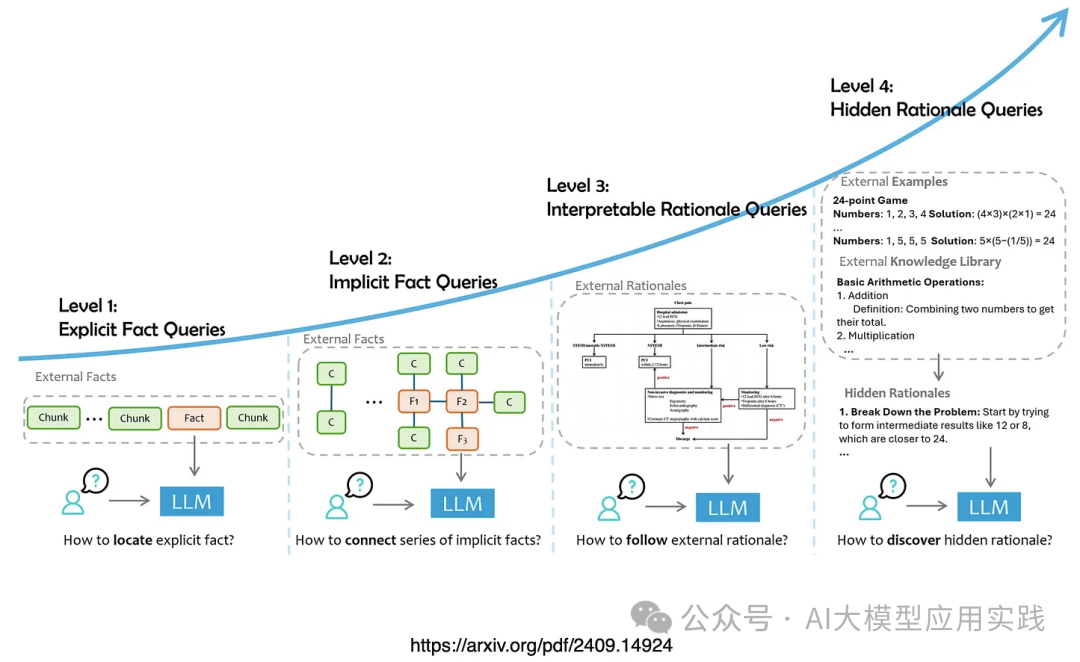
我们尝试对这里的每个层次进行深入理解与解释: 级别 1:基于显式事实的查询(Explicit Fact Queries) 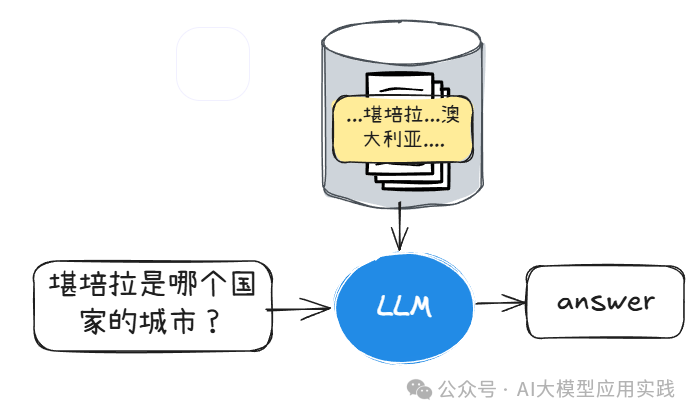
特点:这是最简单的查询形式,模型的主要任务是识别并提取出数据中清晰明确的事实。比如当用户提出问题时,借助RAG技术在数据分块中直接定位与问题相关的显性知识数据并回答。
示例:查询“Canberra的所在国是哪个?”直接从已知信息中提取出“澳大利亚”这个直接答案。
场景:适用于基本的知识问答,如词典定义、时间、地点等。由于查询涉及简单查找、判断与总结,因此模型无需复杂的计算或推理。
级别 2:基于隐式事实的查询(Implicit Fact Queries) 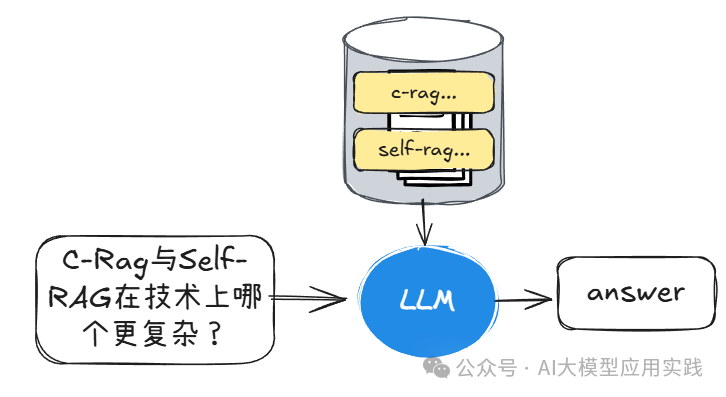
特点:信息可能分散在多个部分,模型需要将多个线索整合起来形成一个完整的答案。也就是说,通常无法在单一的关联知识中直接找到答案。
示例:例如,查询“C-Rag与Self-RAG在技术实现上哪个更复杂",需要首先学习两者的特点,然后进一步分析两者的区别与技术复杂度。再比如一些基于知识图谱(GraphRAG)的多跳查询问题等。
适用场景:适合涉及背景关联和基本逻辑的查询,例如多步信息关联的常识问答场景。
级别 3:基于可解释原理的查询(Interpretable Rationale Queries) 
级别 4:基于隐藏原理的查询(Hidden Rationale Queries) 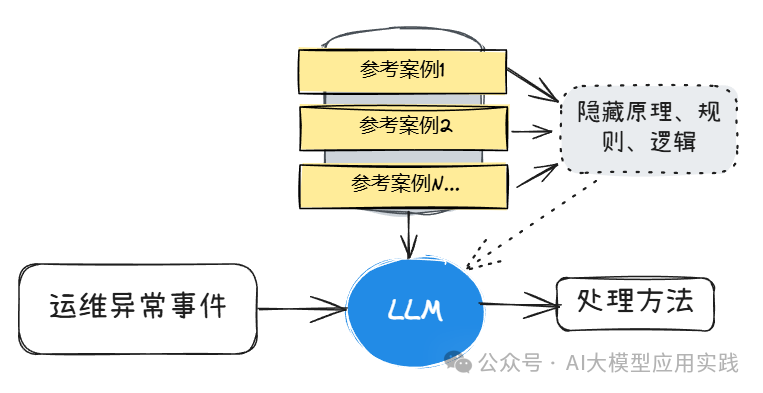
针对不同的任务级别,有着不同的挑战,也需要量身定制的技术方案: 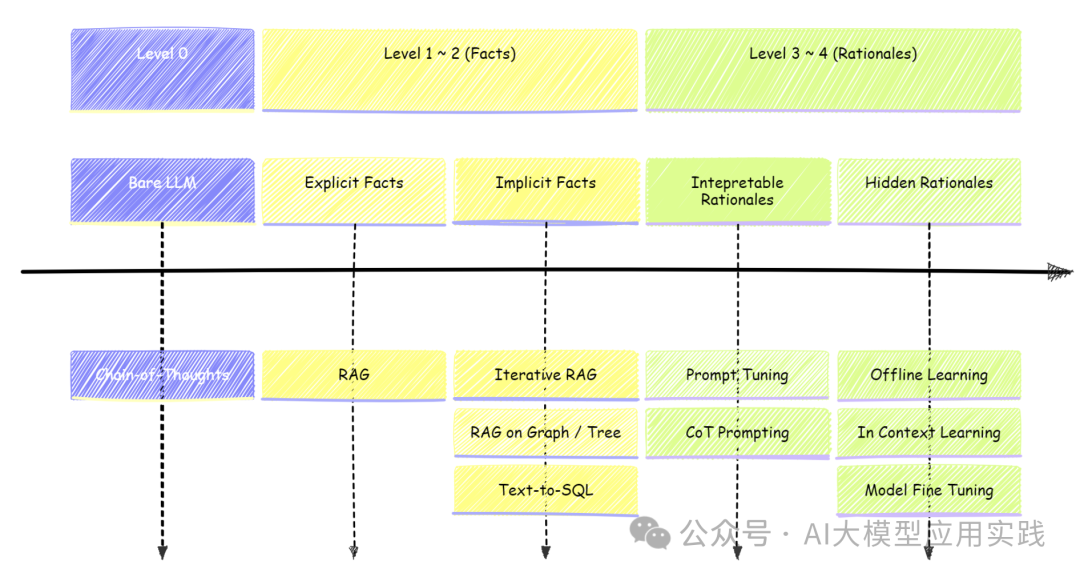
来自https://arxiv.org/pdf/2409.14924 简单的事实查询(Level-1):其挑战在于精确的检索出相关的事实,因此基本的RAG是最常见的方法,其优化的环节主要是索引的创建以及检索阶段的精确性。 隐藏事实查询(Level-2):查询往往需要结合多个可能相关的事实进行推理,因此可能需要引入一些高级的RAG方法与模块,包括查询拆分、多次迭代的RAG,或者GraphRAG,甚至借助Text2SQL查询关联的结构化信息等。这些方法可以帮助获取多个关联的事实并连接,从而有助于输出正确响应。 基于可解释原理查询(Level-3):挑战在于如何有效的将外部原理整合到大模型,并让大模型能够遵循这些原理作出响应。通常直接把原理通过自然语言输入LLM可能效果不佳,目前的常见方法有: 通过更轻量化的提示微调(Prompt-Tuning)技术,来对大模型进行引导以增强任务的适应性 通过设计思维链(Chain-of-thoughts)、思维树(Tree-of-thoughts)的提示,引导模型做长链推理 构建智能体(Agent)系统,借助ReAct等行为范式,结合记忆与工具等能力,让LLM能够根据环境完成复杂推理工作流。如借助反思来迭代优化结果、借助多智能体进行任务协助等,以提高输出质量。
隐藏原理查询(Level-4):这种级别查询问题的挑战之一是如何检索或者提供有效的外部数据,这是因为其需要的上下文并非表面的文本或语义相似性;需要的数据往往是分散的,或者需要提供明确的参考示例。常见的方法有: 离线学习:核心思想是从案例中学习并积累通用的、有用的推理原理、规则、指南、经验、思考模板等,以增强大模型在后续任务中的表现 上下文学习:通过提供上下文示例(few-shot)来引导模型完成任务的一种方法,无需模型参数调整,具有高度的适应性和灵活性 模型微调:通过指令微调向预训练大模型注入新能力,对其在特定专业领域的知识与能力进行增强,提高其针对特定任务的能力
整体而言,把外部数据与知识"注入"到大模型的技术可以分为主要的三种方法: 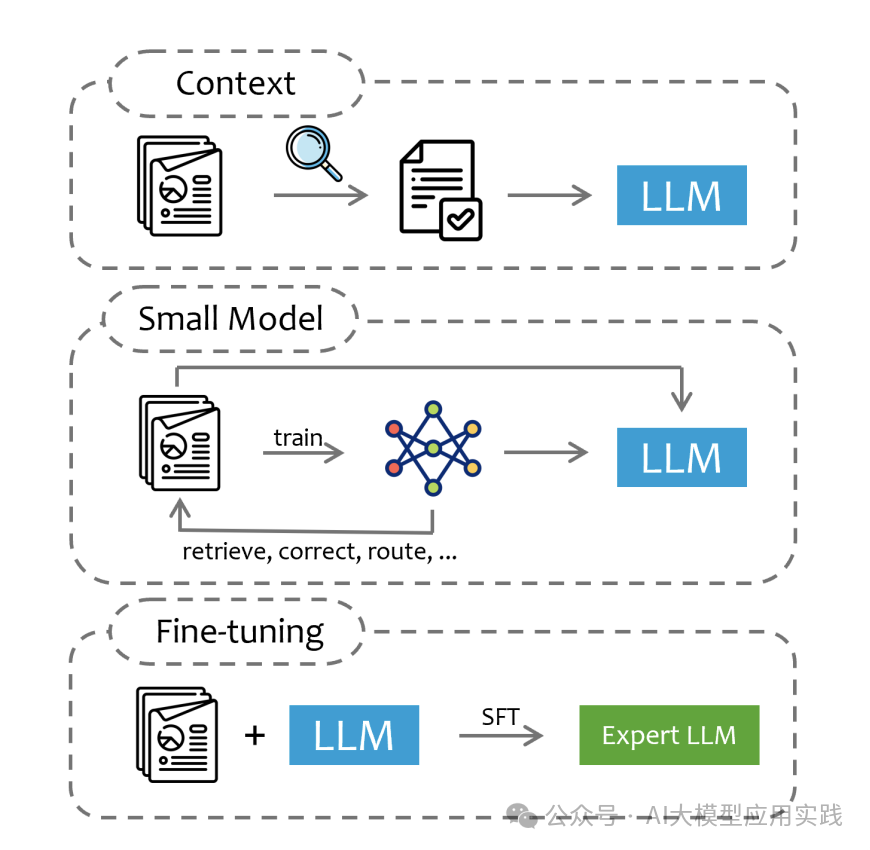
来自https://arxiv.org/pdf/2409.14924 Context(上下文注入) 这也是典型的RAG应用的技术原理。
方法:基于查询从领域数据中提取相关部分,作为LLM的上下文输入。模型在生成响应时参考这些上下文数据,而不改变模型本身的参数。 优势:无需对LLM进行再训练,便于快速适应不同任务和领域。 应用场景:适合需要灵活切换领域信息、时效性要求高的任务。
方法:使用特定领域数据训练一个小模型,并让它辅助LLM的运行。小模型完成数据的检索、纠错、路由等任务,将整合后的信息输入到LLM中。 优势:小模型能专注于处理领域特定任务,提高响应准确性。 应用场景:适合复杂任务或需要数据预处理的场景,如医学或法律领域的数据查询。
方法:直接使用外部领域知识对LLM进行微调。使用领域特定的数据集(例如法律数据)进行监督微调(SFT),将LLM转变为领域专家模型。 优势:模型更深入地掌握该领域知识,能够提供更准确和专业的回答。 应用场景:适合需要长期应用于特定领域的任务,例如法律、金融、医学等需要专业知识的领域。
在微软的这份研究报告中,对基于LLM的数据增强型应用的查询任务做了四个层次的划分,并深入探讨了不同层次的挑战与技术,有助于我们在实际项目中识别不同的任务特点,从而采用更具针对性的技术方案。
| 









