|
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 1.5px;color: rgb(0, 0, 0);font-size: 14px;text-align: justify;visibility: visible;line-height: 2em;">导读本次分享阐述了大模型时代对于分布式训练的挑战,在分布式算法、异构存储等方面存在的业界难题,并提出了相应的优化解决方案。推出了“Colossal-AI”技术架构,为用户系统性解决训练大模型时可能出现的一系列问题。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 1.5px;line-height: 2em;visibility: visible;">1.大模型时代的挑战与机遇 2.Colossal-AI 技术架构 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 1.5px;line-height: 2em;">3.Benchmark 和使用案例ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 1.5px;line-height: 2em;">4.Colossal-AI 与潞晨云ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 1.5px;line-height: 2em;">5.问答环节分享嘉宾|卞正达 北京潞晨科技有限公司 CTO 编辑整理|洛宾 内容校对|李瑶 出品社区|DataFun
大模型时代的挑战与机遇
1.大模型趋势与挑战
随着大模型的发展,其在众多领域的应用不断取得新的突破,如生命医药、计算机科学、自然语言处理等。与此同时,大模型逐渐改变了AI的应用范式,大规模预训练、加上高质量的微调与对齐,再进行推理部署,已成为行业默认的应用流程。

在大模型的发展中,我们看到一个主要趋势是模型的数据量与参数量都逐渐变大。几年前流行的模型可能单张GPU便可完成训练,但是现在的大模型可能需要上万张GPU训练数周才能完成,开销已经变得非常昂贵。
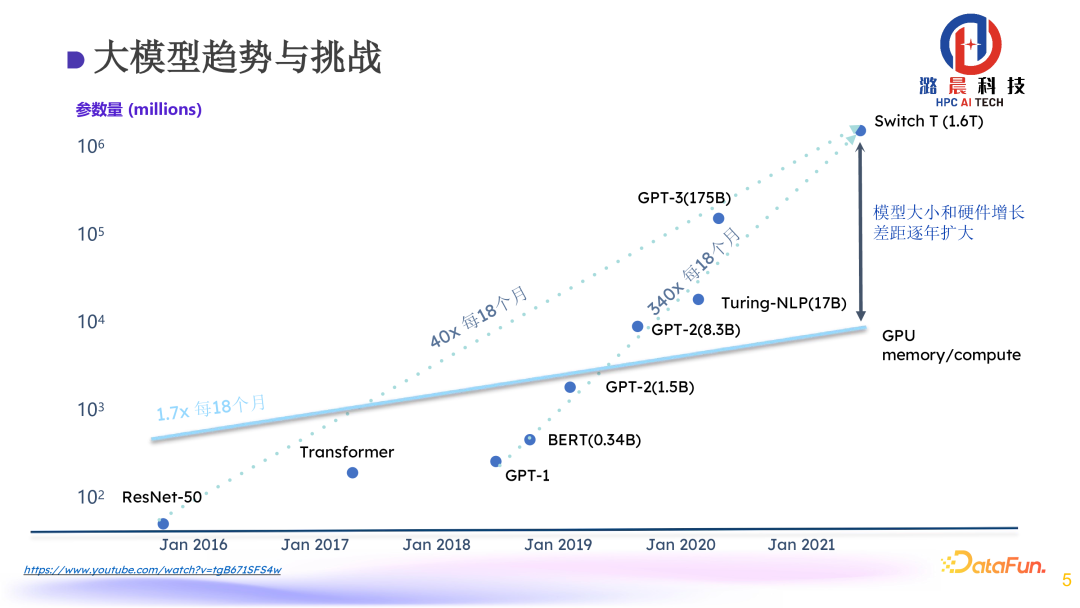
我们不仅需要更多的资源去部署,而且需要更大的精力才能完成训练。所以必须采用大规模分布式训练系统才能完成训练需求,这就对系统部署产生了新的挑战。
2.Colossal-AI Training Stack: 生成式人工智能和 LLM 的软件基础设施
基于上述问题,潞晨科技推出了Colossal-AI框架,来帮助用户更好地实现分布式计算。该框架不仅是作为一种工具使用,更有助于完善分布式训练的生态,向上承接如PyTorch、Lightning等AI应用,向下能够适配包括英伟达在内的不同规格硬件,在AI生态中成为分布式部署的一个核心。

在设计框架时,我们重点关注了零代码的开发体验。通过近似PyTorch语义的接口设计,可实现以近乎零代码的方式将单机训练代码改造为分布式代码。

借助于Colossal-AI提供的全面的分布式模块组件,在各种场景下都能有较为完善的使用体验。
Colossal-AI 技术架构
接下来具体介绍一下Colossal-AI的框架设计。Colossal-AI 框架主要由三部分组成:高效内存异构管理系统+多维并行系统+低延迟推理系统。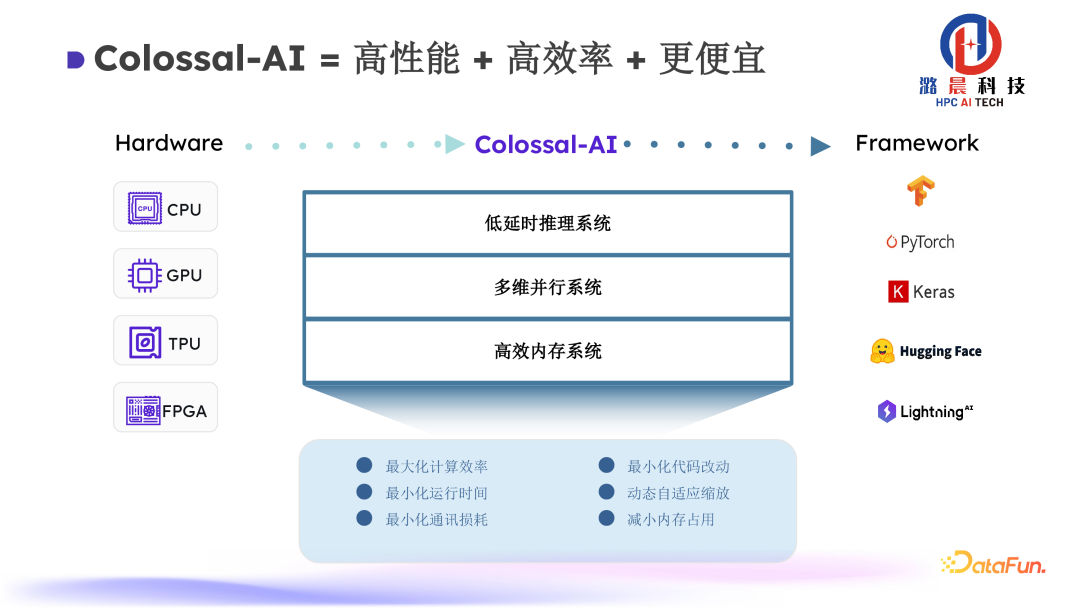
1.N维并行系统
首先是N维并行系统的设计。之前业界已提出了各种分布式算法,并针对不同场景都有各自的优化,但是实际在用户部署时,还是很难判断具体该使用什么策略、什么配置去最高效地运行模型。所以我们设计了这个N维并行系统,整合了业界高效的算法设计,如张量并行、流水线并行、序列并行等等。同时提供了通用接口,将用户的学习成本、使用门槛降到最低。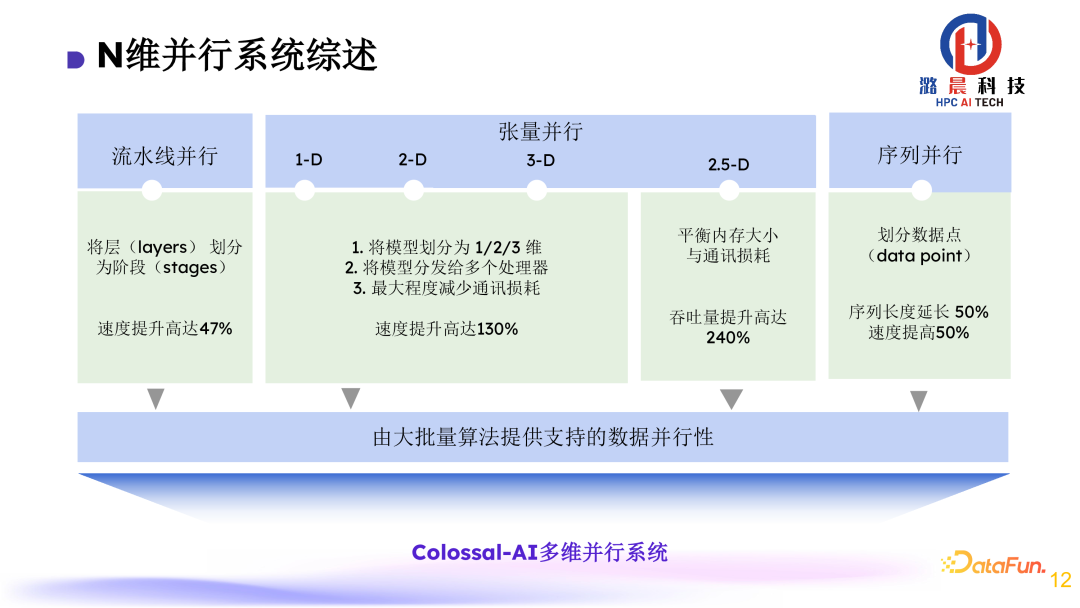
接下来具体介绍一下使用到的技术。我们都知道,训练大模型目前需要大规模的数据,Batch Size越大,训练就能越快结束。
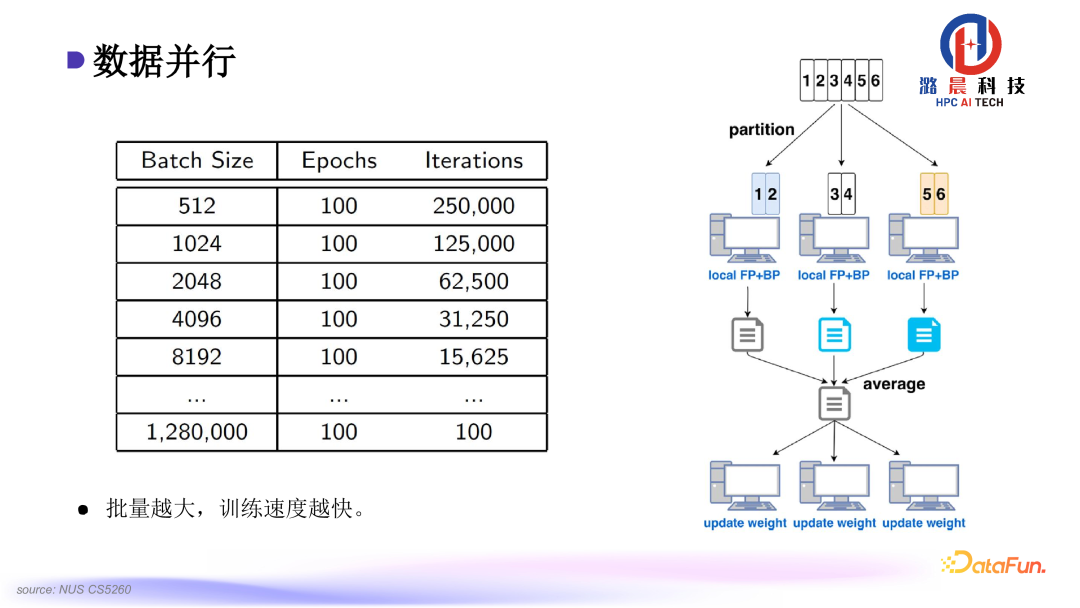
但是Batch Size太大会产生一个sharp minimum 的问题,该问题会导致最后模型收敛时,泛化性能不是特别高。在以往的实践中,最大的Batch Size可能只能到8000左右。我们观察到,主要的问题是在梯度更新时,尺度不是特别合适。在反向过程计算中,有些计算出的梯度非常大,有些非常小。因此在使用统一的梯度去更新时,会出现小梯度被大梯度“吃掉”的情况,这导致了模型最后的泛化性不是很好。
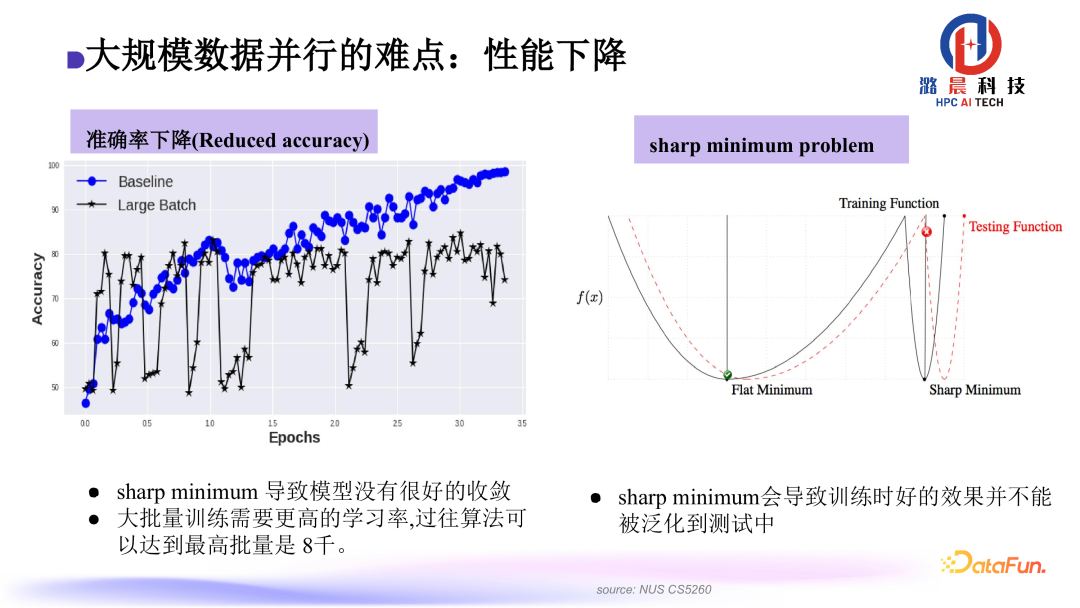
因此我们设计了一种layer-wise的优化器,它可以根据梯度的范数去自适应地更新尺度。

该优化器可以应用到SGD训练场景、用ADAM训练的语言模型场景。针对BERT,可以将其预训练时间缩短至76分钟。该成果已被业界多个公司采纳。

在语音模型训练过程中我们发现 context length 逐年剧增,目前主流大模型的 context length 都已超过 100K,这为大模型训练带来了新的挑战。
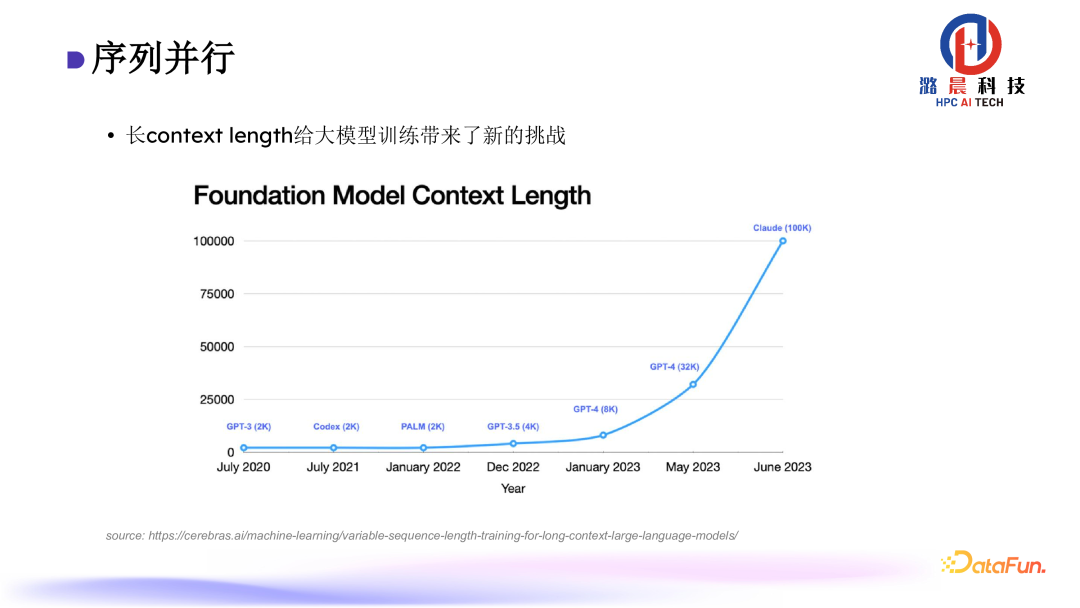
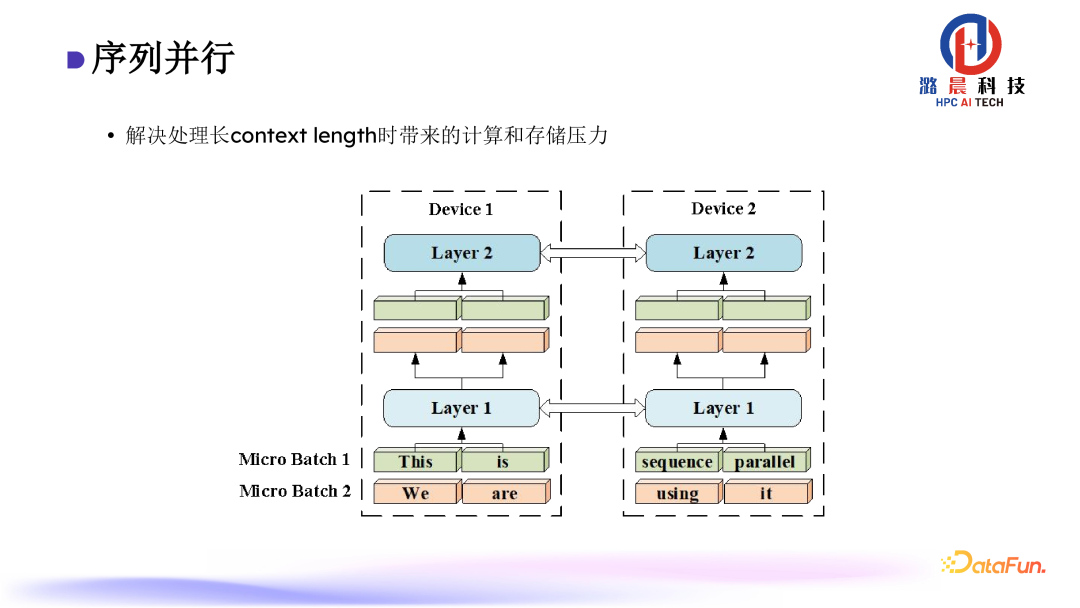
在计算attention的过程当中,长序列导致计算和存储开销平方级增长,因此我们设计了序列并行去均摊计算开销。
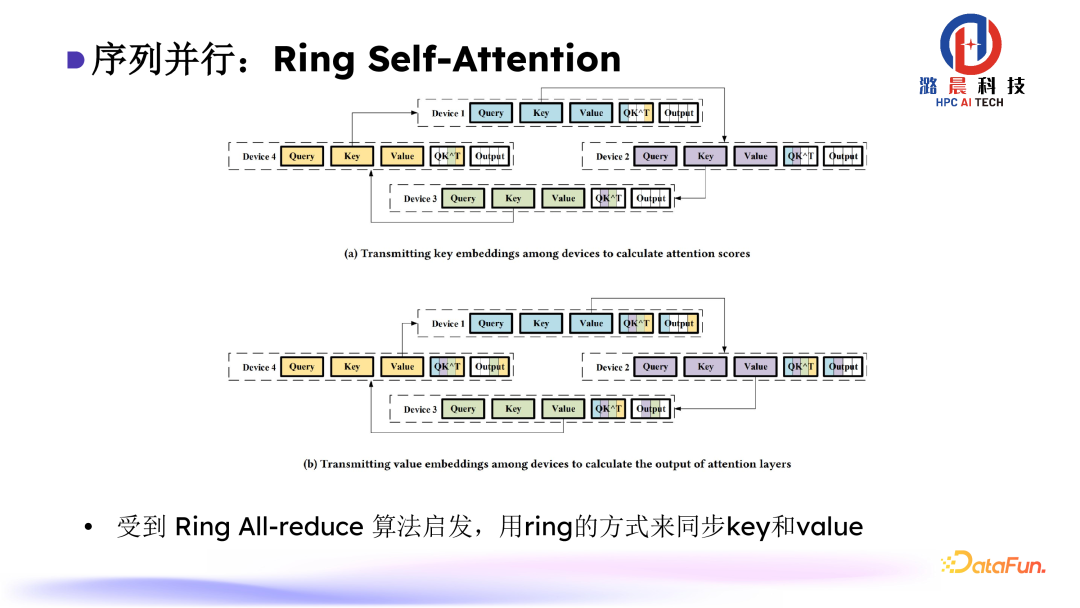
受到Ring All-reduce 算法启发,我们设计了Ring Self-Attention算法,使用 ring 的方式来同步 key 和 value。通过比较少的通信量就可以完成一个完整的attention的计算。
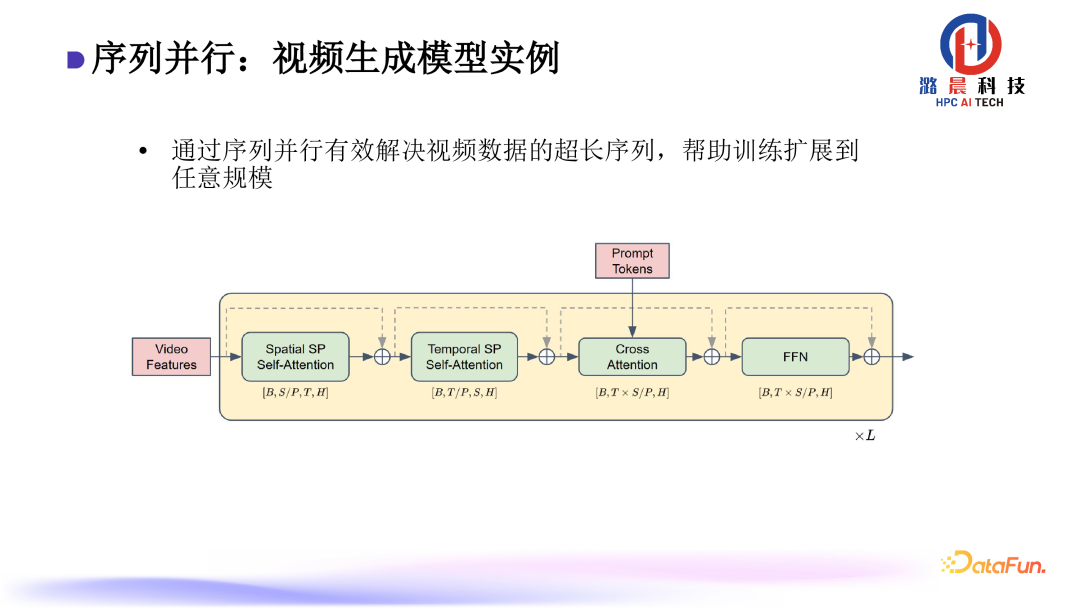
在实际一些训练过程中,我们使用了该技术。如视频生成模型,该模型的特点就是序列非常长,我们通过序列并行的方式,首先将长视频序列拆解为special与temporal两个维度,然后分别在这两个维度上进行序列并行,从而将视频模型整个的计算进行均摊。理论上,可以扩展到一个无限长的规模。
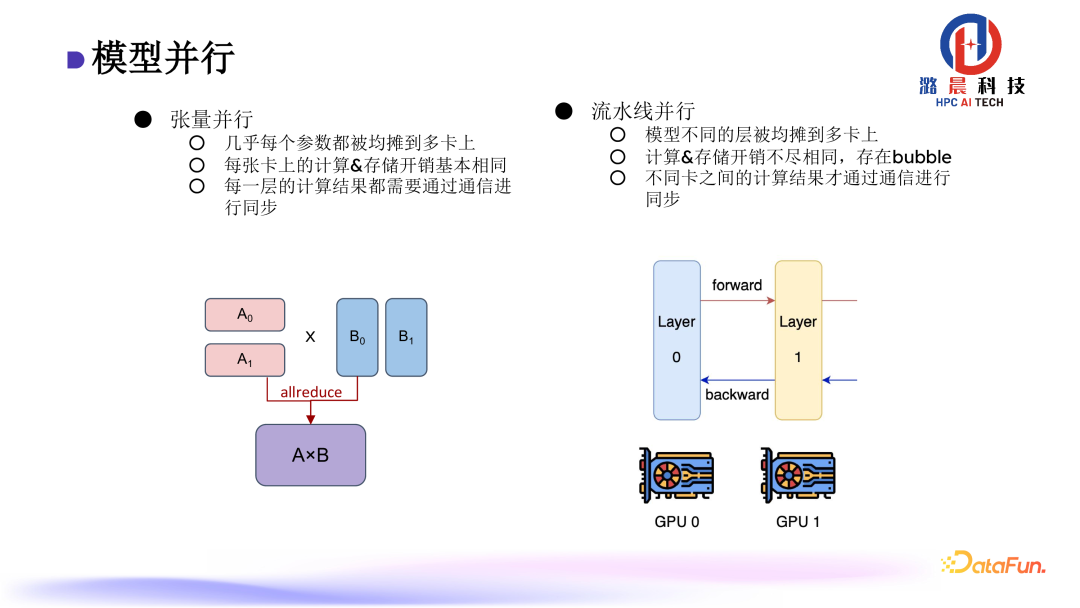
模型并行主要分为两个维度。第一个是张量并行,张量并行的做法是几乎每个参数都被均摊到多卡上,在本地计算之后,通过All-reduce进行结果的同步。另外一个是流水线并行,是把模型不同的层均摊到多卡上,每张卡计算完成之后,结果传递到下一张卡上进行计算。流水线并行的问题是计算存在bubble。
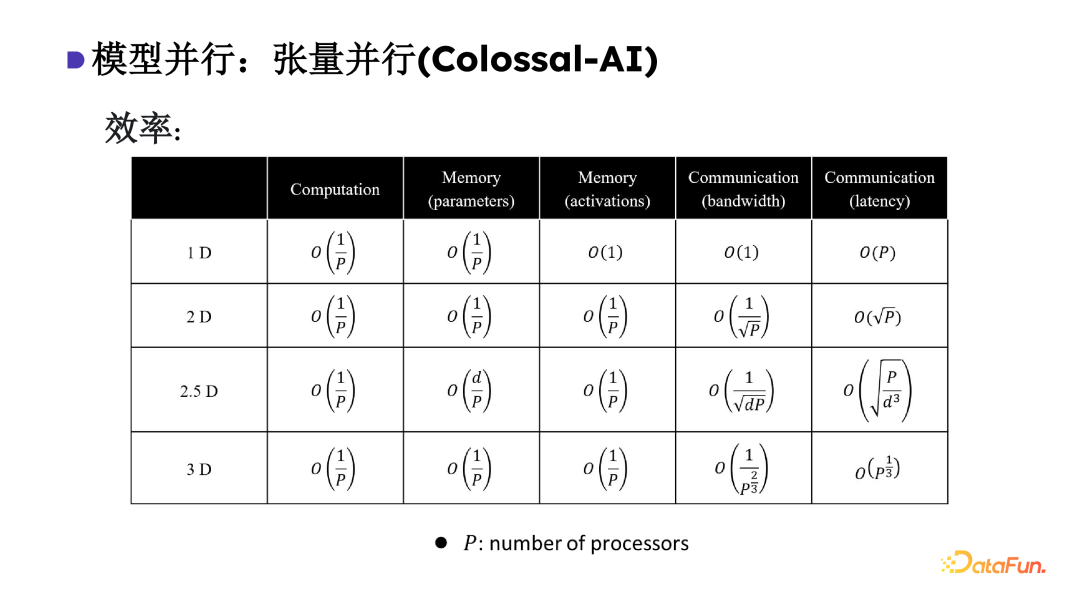
在Colossal-AI中,考虑到实际物理部署中会遇到不同的服务器拓扑。相应的我们设计了2D、2.5D、3D这种张量并行模式去适配不同硬件拓扑。从而帮助用户在不同的场景下都可以找到合适的算法来实现更低的通讯开销。
为缓解流水线并行的bubble问题,管道并行性将输入小批量(minibatch)拆分为多个微批量 (microbatches),并在多个 GPU 上以管道方式执行这些微批量。但该方式仅可以缓解,无法彻底消除bubble。

因此我们采用了zerobubble的pipeline设计。通过把反向的梯度拆解为参数和输入输出两部分,可以隐去流水线中的bubble。
2.异构存储系统
Colossal-AI的另一个关键组件是异构存储系统。在训练大模型时,因参数量太大导致存储开销特别大,但是实际在模型训练中,对于存储的需求集中于优化器部分,而计算负载较高的前向与后向部分存储需求并不大。因此可以考虑现将存储开销较大的优化器部分缓存到 CPU 的 RAM 上面,从而极大地缓解 GPU 的存储压力。
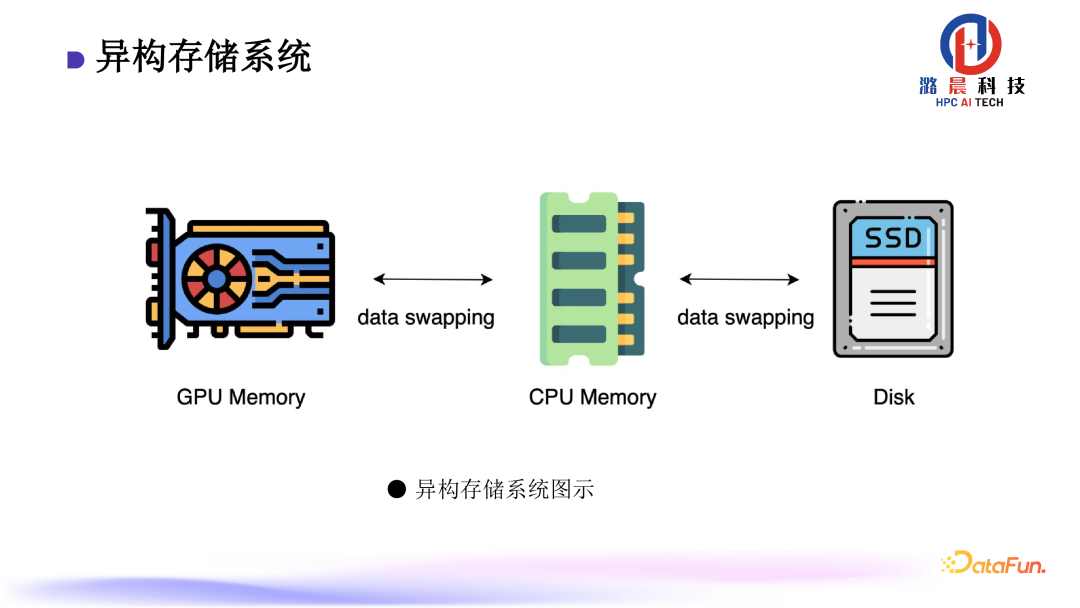
业界传统的做法,CPU 与 GPU 之间会一直需要数据移动,实际应用效率会受到较大影响。根据实际的计算过程,我们提出了通过自适应 Tensor 存储管理,来最小化数据移动,从而较显著的减少数据移动的通信压力。
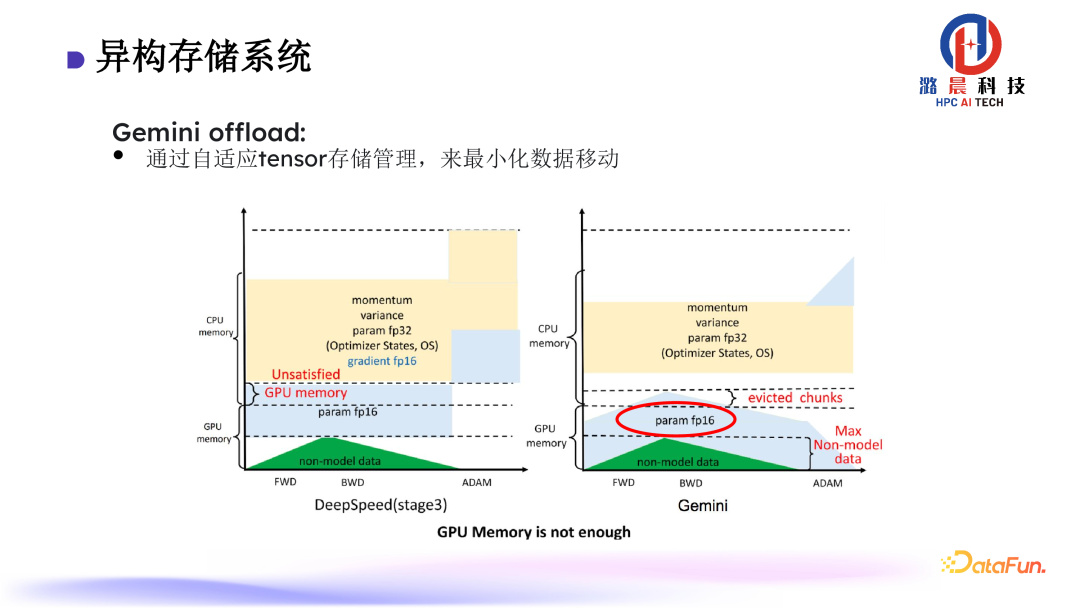
另外,我们的存储管理系统基于 Chunk 来设计。通过将 Tensor 聚合成 Chunk,来减少碎片,提高通信效率。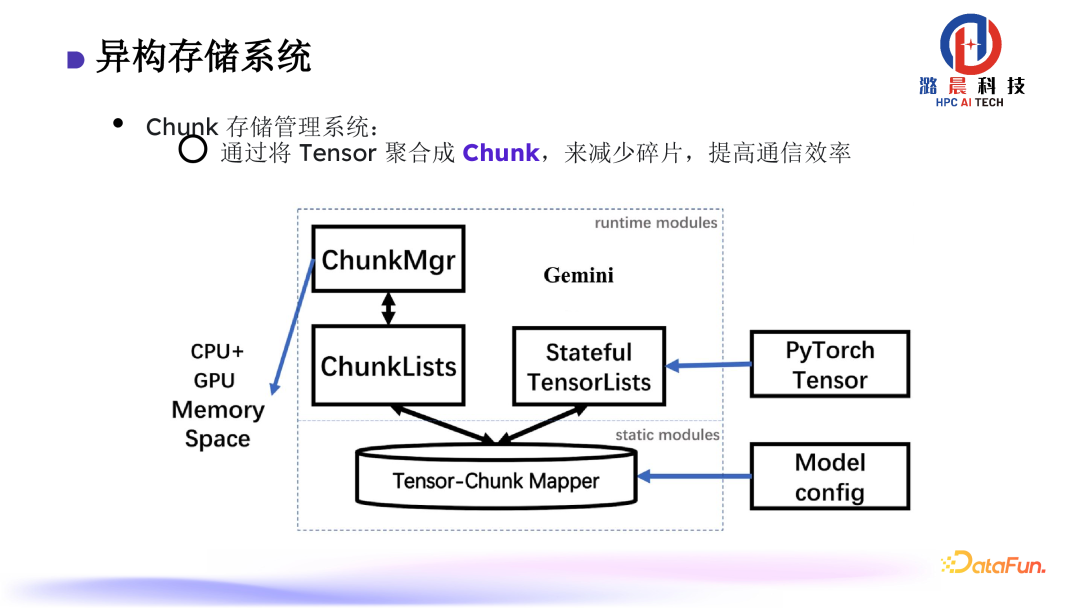
3.易用性+通用性+扩展性
为了Colossal-AI的实用性与通用性,设计了两个主要模块:首先,N维并行系统设计为插件模式,各个并行的维度以解耦的方式插入到Colossal-AI中;再者,模型的部署策略,通过模型策略来做算子的替换,加速模型计算。这两个模块一方面提供了非常通用的接口设计,而且其扩展性也得到了保证。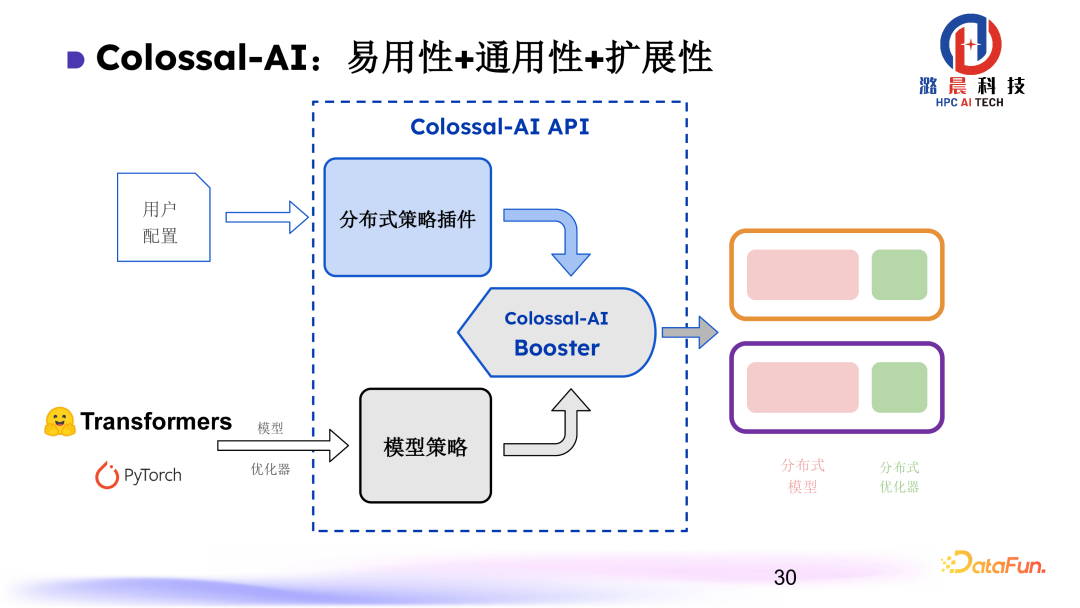
Benchmark和使用案例
1.训练 Benchmark
在训练环节,Colossal-AI支持FP8混合精度训练,相比于PyTorch、BF16能够分别提升90%、30%-40%的效率。
2. Colossal-AI 应用案例
异构存储系统可以帮助用户在有限的硬件设备上将模型容量提升百倍。同样的硬件下,相比于其他框架,我们也能达到更高的训练速度。

3. Grok-1推理

此外,在推理方面,通过将非常大的模型在Colossal-AI的并行部署,可以实现推理加速。例如Grok-1可以在H800上实现3.8倍的推理加速。
此外,Colossal-AI提供了自有算力平台。在该平台上,用户的开发体验和使用效果都能实现很好的保障。
在软件推出至今2年的时间内,获得了业界很好的反响,其中核心技术在学术界与工业界都获得了认可。目前我们的用户遍布全球,字节、商汤模型训练都采用了我们的部分技术。

Colossal-AI与潞晨云
最后简单介绍下我们的潞晨云算力平台https://cloud.luchentech.com/
基于Colossal-AI 中的优化技术,“潞晨云“能够为用户提供多样算力、多样的镜像配置、丰富的文档帮助用户上手。

希望更多的用户能够在Colossal-AI 平台上以更低成本享受到更方便的AI开发过程,获得更高的AI开发效率。最后,欢迎大家参与到我们的社区中来。
问答环节
Q1:Colossal-AI与PyTorch的交互方式
A1:Colossal-AI兼容了来自于不同社区(PyTorch、Lightning、HoneyFace等等)的应用,在我们的框架里面都可以进行统一的优化加速。
具体做法来说,Colossal-AI框架提供了一系列插件,像是PyTorch的应用,能够帮助它一键式部署分布式的应用。在用户训练的脚本基础之上,我们使用Colossal-AI的一些接口去部署用户的model、opitimizer。经过封装后,用户在使用时和PyTorch没有任何的差异感知。
A2:在张量并行,2.5D相当于有不同层的2D,每一层做1/N的2D,参数会赋值到不同层,因此会有额外的存储开销。而3D通过立方体的拓扑部署,每个rank上只需要做一次计算,不再需要循环。
基于此,我们可以通过通信的改造,在通信开销不变的基础上,不再需要冗余存储,所有存储都是均摊在设备上。 |










