最近,DeepSeek v3(一个MoE模型,拥有671B参数,其中37B参数被激活)模型全球爆火。
作为一款能与Claude 3.5 Sonnet,GPT-4o等模型匹敌的开源模型DeepSeek v3不仅将其算法开源,还放出一份扎实的技术报告,详尽描述了DeepSeek是如何进行大模型架构、算法工程协同设计,部署,训练,数据处理等方面的思考,堪称是一份DeepSeek给开源社区送上的年末大礼。
本篇文章,我们会对DeepSeek v3的亮点进行梳理,并对其RAG搭建流程与效果,做一个简单的示例。
01.
DeepSeek v3的亮点
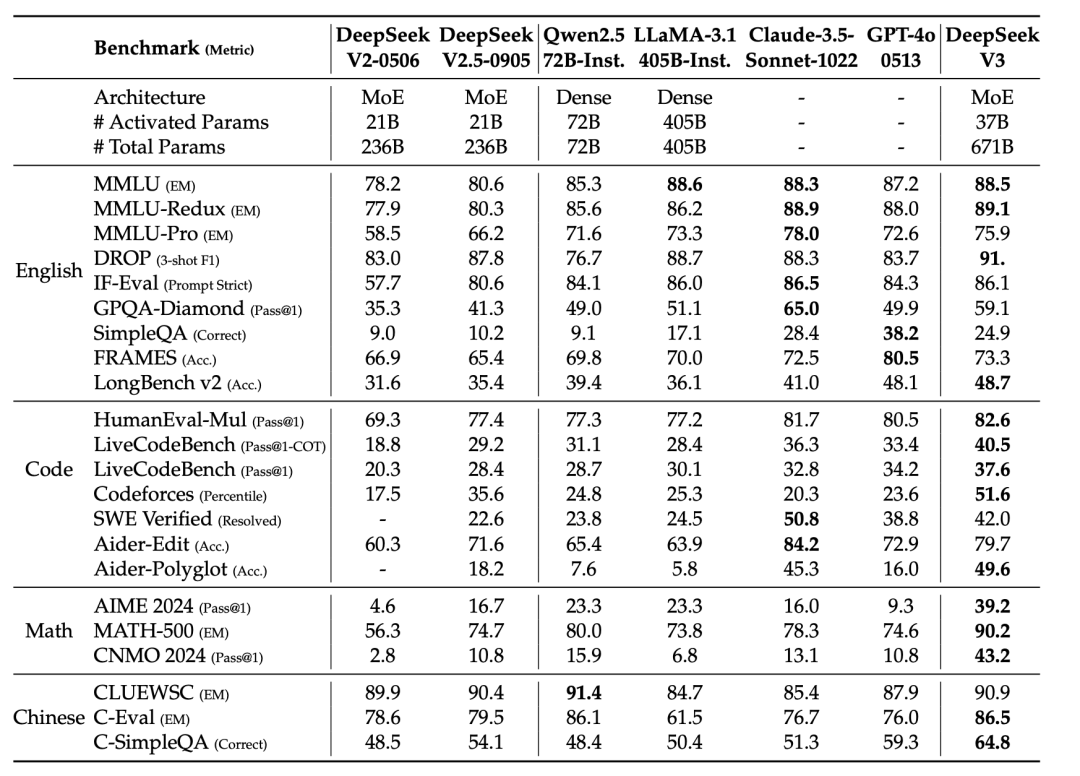
亮点一:超低的训练成本,将带来算力的极大富余
相比于海外大厂动辄上万甚至上十万的H100集群(例如Meta使用了16K的H100训练Llama3.1 405B),DeepSeek仅仅使用了2048张丐版显卡H800就在14.8T数据上训练了一个处于第一梯队的开源模型。以下是DeepSeek v3的训练成本数据。
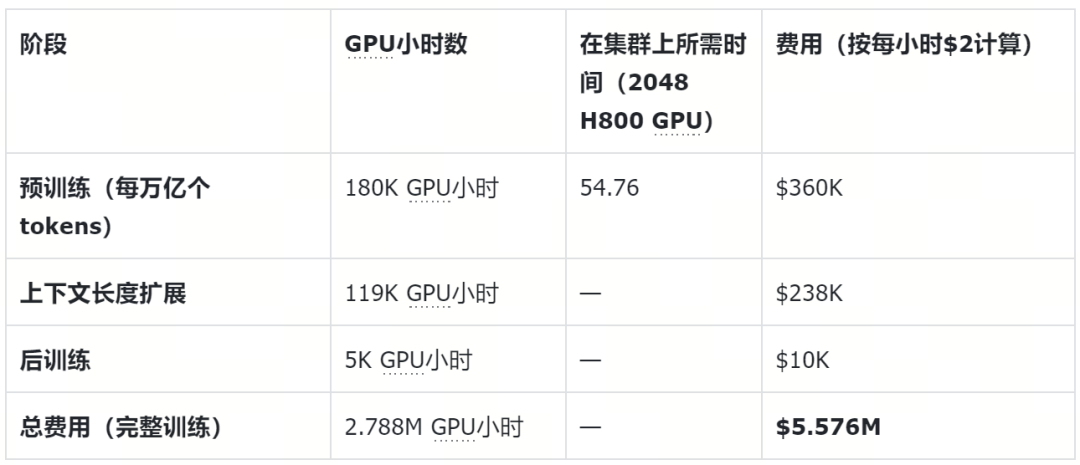
不难看出,基于以上数据,传统对大模型对算力的供需预测推演直接被推翻,过去Scaling law曲线所估算出的GPU需求数量会出现极大冗余。
那么问题来了,DeepSeek v3是如何做到的?
亮点二:颠覆GPT架构,极致的工程设计
在去年,大模型领域普遍认为模型的设计已经收敛到Decoder-only的GPT架构,但DeepSeek依然没有放弃对模型架构的进一步探索。
这一次V3的设计延用了V2提出的MLA(Multi-head Latent Attention),这是一种通过低秩压缩键值对来减少缓存需求的创新架构,以提高Transformer模型的推理效率。
另外,此次的MoE模型规格也比之前大了许多(V3 671B, V2 236B),也体现出了对这个架构拥有更多的信心和经验。DeepSeek V3将除前三层外的所有 FFN 层替换为 MoE 层。每个 MoE 层包含 1 个共享专家和 256 个路由专家。在路由专家中,每个 token 将激活 8 个专家,并确保每个 token 最多会被发送到 4 个节点。
同时,论文还对如何在系统中设计将这种架构进行推理的性能优化也进行了详尽的描述。
DeepSeek V3使用了多token预测(MTP),即每个 token 除了精确预测下一个 token 外,还会预测一个额外的 token,通过投机采样的方式提高推理效率。
关于如何使用FP8进行模型训练这个各个大模型工程团队头痛的问题,DeepSeek V3也对自己的实践有细致的描述,对这部分感兴趣的朋友强烈推荐阅读论文原文。
亮点三:通过蒸馏推理模型进行后训练
自从OpenAI发布了o1模型之后,业界开始逐渐兴起了探索这种内置思维琏(CoT)的模型,它不断对中间结果探索分析的过程仿佛人的“慢思考”。DeepSeek同样也开发了类似的R1模型,在DeepSeek V3中,DeepSeek创新性地通过在后训练阶段使用R1得到的高质量答案来提高了自身的性能。这一点也非常有趣。
众所周知,类似o1的开源模型大部分都是从基础模型利用CoT结合强化学习的技巧训练出来提高了推理效果,而现在又通过蒸馏推理模型获得了下一代更好的基础模型,这一种模型和数据质量互相交织的发展模式贯穿着机器学习发展的历史,而还将继续被见证。
而以发掘非结构化数据价值的厂商Zilliz也相信对于数据和知识的高效管理,将会一直在智能化浪潮发展中扮演着重要的角色。
看到10K$的后训练成本,相信许多致力于微调专属大模型的厂商都跃跃欲试,在这里我们也来看一下DeepSeek V3的后训练过程,整个流程也比传统的SFT要复杂一些。整个过程分成了SFT阶段(监督学习)以及RL阶段(强化学习),在SFT阶段,他们将数据分成了两种类型,推理数据以及非推理数据
推理数据:
包括数学,编程这些问题,DeepSeek训练了针对性的专家模型,并使用专家模型为每一个问题生成了两种格式的学习数据。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 1px;"><problem, original response>
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 1px;"><system prompt, problem, R1 response>
非推理数据:
对于非推理任务(如创意写作和简单问答),作者利用DeepSeek-V2.5模型生成初步响应,并聘请人工标注员对其准确性进行验证
训练的流程:
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 1px;">SFT阶段,使用基于专家模型生成的SFT样本,进行初步的监督微调。通过这些训练数据,模型学习如何根据问题和回答生成精确的推理响应。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 1px;">RL阶段,使用高温采样来生成响应,这些响应融合了来自原始数据和R1生成数据的模式。在RL阶段,会使用LeetCode编译器来检查编程的答案,以及一些规则来去检查数学问题的答案,对于开放性问题, 会用一个奖励模型来去判断。该过程帮助模型在没有显式系统提示的情况下进行推理,经过数百次RL步骤,模型学会如何平衡准确与简洁性的答案。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 1px;">完成RL训练后,作者实施拒绝采样策略(过滤掉模型认为低质量的数据),以从生成的样本中挑选出高质量的SFT数据。这些数据用于最终模型的微调。
不难发现,做好一个高质量的后训练,下的功夫远远不止10k$的训练算力。
DeepSeek V3虽然拥有可以与闭源模型匹敌的性能,但是部署它依然不是一个简单的事,即使作者已经为了推理优化做了许多工作,但搭建一个DeepSeek V3的服务(考虑到它671B的参数量),成本依然不低。
02.
使用Milvus和DeepSeek搭建RAG
接下来,我们将展示如何使用Milvus和DeepSeek构建检索增强生成(RAG)pipeline。
2.1 准备
2.1.1 依赖和环境
pipinstall--upgradepymilvus[model]openairequeststqdm
如果您使用的是Google Colab,要启用刚刚安装的依赖项,您可能需要重启运行环境(单击屏幕顶部的“Runtime”菜单,然后从下拉框中选择“Restart session”)。
DeepSeek启动了OpenAI风格的API。您可以登录官网并将api密钥 DEEPSEEK_API_KEY准备为环境变量。
importos
os.environ["DEEPSEEK_API_KEY"]="***********"
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 1px;text-align: left;background-attachment: scroll;background-clip: border-box;background-image: none;background-origin: padding-box;background-position: 0% 0%;background-repeat: no-repeat;background-size: auto;width: auto;height: auto;border-style: none;border-width: 3px;border-color: rgba(0, 0, 0, 0.4);border-radius: 0px;">2.1.2准备数据
我们使用Milvus文档2.4. x(https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip)中的FAQ页面作为RAG中的私有知识,这是搭建一个入门RAG pipeline的优质数据源。
首先,下载zip文件并将文档解压缩到文件夹milvus_docs。
!wgethttps://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
!unzip-qmilvus_docs_2.4.x_en.zip-dmilvus_docs
我们从文件夹milvus_docs/en/faq中加载所有markdown文件,对于每个文档,我们只需简单地使用“#”来分隔文件中的内容,就可以大致分隔markdown文件各个主要部分的内容。
fromglobimportglob
text_lines=[]
forfile_pathinglob("milvus_docs/en/faq/*.md",recursive=True):
withopen(file_path,"r")asfile:
file_text=file.read()
text_lines+=file_text.split("#")
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 1px;text-align: left;background-attachment: scroll;background-clip: border-box;background-image: none;background-origin: padding-box;background-position: 0% 0%;background-repeat: no-repeat;background-size: auto;width: auto;height: auto;border-style: none;border-width: 3px;border-color: rgba(0, 0, 0, 0.4);border-radius: 0px;">2.1.3准备LLM和embedding模型
DeepSeek采用了类OpenAI风格的API,您可以使用相同的API并对相应的LLM进行微调。
fromopenaiimportOpenAI
deepseek_client=OpenAI(
api_key=os.environ["DEEPSEEK_API_KEY"],
base_url="https://api.deepseek.com",
)
选择一个embedding模型,使用milvus_model来做文本向量化。我们以DefaultEmbeddingFunction模型为例,它是一个预训练的轻量级embedding模型。
frompymilvusimportmodelasmilvus_model
embedding_model=milvus_model.DefaultEmbeddingFunction()
生成测试向量,并输出向量维度以及测试向量的前几个元素。
test_embedding=embedding_model.encode_queries(["Thisisatest"])[0]
embedding_dim=len(test_embedding)
print(embedding_dim)
print(test_embedding[:10])
768
[-0.048360660.07163023-0.01130064-0.03789345-0.03320649-0.01318448
-0.03041712-0.02269499-0.02317863-0.00426028]
2.2 将数据加载到Milvus
2.2.1 创建集合
frompymilvusimportMilvusClient
milvus_client=MilvusClient(uri="./milvus_demo.db")
collection_name="my_rag_collection"
对于MilvusClient需要说明:
- 将
uri设置为本地文件,例如./milvus. db,是最方便的方法,因为它会自动使用Milvus Lite将所有数据存储在此文件中。 - 如果你有大规模数据,你可以在docker或kubernetes上设置一个更高性能的Milvus服务器。在此设置中,请使用服务器uri,例如
http://localhost:19530,作为你的uri。 - 如果要使用Milvus的全托管云服务Zilliz Cloud,请调整
uri和token,分别对应Zilliz Cloud中的公共端点和Api密钥。
检查集合是否已经存在,如果存在则将其删除。
ifmilvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
使用指定的参数创建一个新集合。
如果我们不指定任何字段信息,Milvus将自动为主键创建一个默认的id字段,并创建一个向量字段来存储向量数据。保留的JSON字段用于存储未在schema里定义的标量数据。
milvus_client.create_collection(
collection_name=collection_name,
dimension=embedding_dim,
metric_type="IP",#Innerproductdistance
consistency_level="Strong",#Strongconsistencylevel
)
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 1px;text-align: left;background-attachment: scroll;background-clip: border-box;background-image: none;background-origin: padding-box;background-position: 0% 0%;background-repeat: no-repeat;background-size: auto;width: auto;height: auto;border-style: none;border-width: 3px;border-color: rgba(0, 0, 0, 0.4);border-radius: 0px;">2.2.2插入数据
逐条取出文本数据,创建嵌入,然后将数据插入Milvus。
这里有一个新的字段“text”,它是集合schema中的非定义字段,会自动添加到保留的JSON动态字段中。
fromtqdmimporttqdm
data=[]
doc_embeddings=embedding_model.encode_documents(text_lines)
fori,lineinenumerate(tqdm(text_lines,desc="Creatingembeddings")):
data.append({"id":i,"vector":doc_embeddings[i],"text":line})
milvus_client.insert(collection_name=collection_name,data=data)
Creatingembeddings:0%||0/72[00:00<?,?it/s]huggingface/tokenizers:Thecurrentprocessjustgotforked,afterparallelismhasalreadybeenused.Disablingparallelismtoavoiddeadlocks...
Todisablethiswarning,youcaneither:
-Avoidusing`tokenizers`beforetheforkifpossible
-ExplicitlysettheenvironmentvariableTOKENIZERS_PARALLELISM=(true|false)
Creatingembeddings:100%|██████████|72/72[00:00<00:00,246522.36it/s]
{'insert_count':72,'ids':[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71],'cost':0}
2.3 构建RAG
2.3.1 检索查询数据
让我们指定一个关于Milvus的常见问题。
question="Howisdatastoredinmilvus?"
在集合中搜索问题并检索语义top-3匹配项。
search_res=milvus_client.search(
collection_name=collection_name,
data=embedding_model.encode_queries(
[question]
),#Convertthequestiontoanembeddingvector
limit=3,#Returntop3results
search_params={"metric_type":"IP","params":{}},#Innerproductdistance
output_fields=["text"],#Returnthetextfield
)
我们来看一下query的搜索结果
importjson
retrieved_lines_with_distances=[
(res["entity"]["text"],res["distance"])forresinsearch_res[0]
]
print(json.dumps(retrieved_lines_with_distances,indent=4))
[
[
"WheredoesMilvusstoredata?\n\nMilvusdealswithtwotypesofdata,inserteddataandmetadata.\n\nInserteddata,includingvectordata,scalardata,andcollection-specificschema,arestoredinpersistentstorageasincrementallog.Milvussupportsmultipleobjectstoragebackends,including[MinIO](https://min.io/),[AWSS3](https://aws.amazon.com/s3/?nc1=h_ls),[GoogleCloudStorage](https://cloud.google.com/storage?hl=en#object-storage-for-companies-of-all-sizes)(GCS),[AzureBlobStorage](https://azure.microsoft.com/en-us/products/storage/blobs),[AlibabaCloudOSS](https://www.alibabacloud.com/product/object-storage-service),and[TencentCloudObjectStorage](https://www.tencentcloud.com/products/cos)(COS).\n\nMetadataaregeneratedwithinMilvus.EachMilvusmodulehasitsownmetadatathatarestoredinetcd.\n\n###",
0.6572665572166443
],
[
"HowdoesMilvusflushdata?\n\nMilvusreturnssuccesswheninserteddataareloadedtothemessagequeue.However,thedataarenotyetflushedtothedisk.ThenMilvus'datanodewritesthedatainthemessagequeuetopersistentstorageasincrementallogs.If`flush()`iscalled,thedatanodeisforcedtowritealldatainthemessagequeuetopersistentstorageimmediately.\n\n###",
0.6312146186828613
],
[
"HowdoesMilvushandlevectordatatypesandprecision?\n\nMilvussupportsBinary,Float32,Float16,andBFloat16vectortypes.\n\n-Binaryvectors:Storebinarydataassequencesof0sand1s,usedinimageprocessingandinformationretrieval.\n-Float32vectors efaultstoragewithaprecisionofabout7decimaldigits.EvenFloat64valuesarestoredwithFloat32precision,leadingtopotentialprecisionlossuponretrieval.\n-Float16andBFloat16vectors:Offerreducedprecisionandmemoryusage.Float16issuitableforapplicationswithlimitedbandwidthandstorage,whileBFloat16balancesrangeandefficiency,commonlyusedindeeplearningtoreducecomputationalrequirementswithoutsignificantlyimpactingaccuracy.\n\n###",
efaultstoragewithaprecisionofabout7decimaldigits.EvenFloat64valuesarestoredwithFloat32precision,leadingtopotentialprecisionlossuponretrieval.\n-Float16andBFloat16vectors:Offerreducedprecisionandmemoryusage.Float16issuitableforapplicationswithlimitedbandwidthandstorage,whileBFloat16balancesrangeandefficiency,commonlyusedindeeplearningtoreducecomputationalrequirementswithoutsignificantlyimpactingaccuracy.\n\n###",
0.6115777492523193
]
]
2.3.2 使用LLM获取RAG响应
将检索到的文档转换为字符串格式。
context="\n".join(
[line_with_distance[0]forline_with_distanceinretrieved_lines_with_distances]
)
为LLM定义系统和用户提示。这个提示是由从Milvus检索到的文档组装而成的。
SYSTEM_PROMPT="""
Human:YouareanAIassistant.Youareabletofindanswerstothequestionsfromthecontextualpassagesnippetsprovided.
"""
USER_PROMPT=f"""
Usethefollowingpiecesofinformationenclosedin<context>tagstoprovideananswertothequestionenclosedin<question>tags.
<context>
{context}
</context>
<question>
{question}
</question>
"""
使用DeepSeek提供的deepseek-chat模型根据提示生成响应。
response=deepseek_client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role":"system","content":SYSTEM_PROMPT},
{"role":"user","content":USER_PROMPT},
],
)
print(response.choices[0].message.content)
InMilvus,dataisstoredintwomaincategories:inserteddataandmetadata.
1.**InsertedData**:Thisincludesvectordata,scalardata,andcollection-specificschema.Theinserteddataisstoredinpersistentstorageasincrementallogs.Milvussupportsvariousobjectstoragebackendsforthispurpose,suchasMinIO,AWSS3,GoogleCloudStorage(GCS),AzureBlobStorage,AlibabaCloudOSS,andTencentCloudObjectStorage(COS).
2.**Metadata**:MetadataisgeneratedwithinMilvusandisspecifictoeachMilvusmodule.Thismetadataisstoredinetcd,adistributedkey-valuestore.
Additionally,whendataisinserted,itisfirstloadedintoamessagequeue,andMilvusreturnssuccessatthisstage.Thedataisthenwrittentopersistentstorageasincrementallogsbythedatanode.Ifthe`flush()`functioniscalled,thedatanodeisforcedtowritealldatainthemessagequeuetopersistentstorageimmediately.
太好了!现在我们已经成功使用Milvus和DeepSeek构建了一个RAG pipeline。










