目录
环境准备
1.anaconda
2.python 环境
3.VLLM(注:只可运行在Linux系统中)
4.云服务器或本地物理服务器;(本文以云服务器部署为例)
配置步骤
一、配置 GPU 云服务器
1.购买云服务器 GPU 计算型
根据实际需要选择

等待实例初始化

2.在本地电脑使用 ssh 连接服务器
这里我使用私钥进行连接

二、安装 conda
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.3.1-Linux-x86_64.sh

#赋予文件可执行权限chmod+xAnaconda3-5.3.1-Linux-x86_64.sh#执行安装脚本./Anaconda3-5.3.1-Linux-x86_64.sh
根据提示输入 yes 敲回车,等待安装完成即可,下图为安装成功截图。注:重启终端或打开新终端生效

三、显卡驱动安装
1.导入官方源
add-apt-repositoryppa:graphics-drivers/ppaaptupdate
2.手动或自动安装驱动程序
#安装驱动检查工具aptinstallubuntu-drivers-commonalsa-utils-y#自动检查安装与当前显卡兼容的驱动程序ubuntu-driversautoinstall#列出可用驱动ubuntu-driversdevices#手动安装aptinstallnvidia-driver-470
3.安装完成后,输入以下命令查看当前显卡

4.安装 cuda
选择合适自己的版本进行下载
https://developer.nvidia.com/cuda-toolkit-archive
我这里安装cuda12.6,与上一步中显示的版本号保持一致。如安装版本与本文一致,可按以下顺序执行安装。
#默认为root用户,如不是root用户请加sudo
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-ubuntu2404.pinmv cuda-ubuntu2404.pin/etc/apt/preferences.d/cuda-repository-pin-600wget https://developer.download.nvidia.com/compute/cuda/12.6.0/local_installers/cuda-repo-ubuntu2404-12-6-local_12.6.0-560.28.03-1_amd64.debdpkg-i cuda-repo-ubuntu2404-12-6-local_12.6.0-560.28.03-1_amd64.debcp/var/cuda-repo-ubuntu2404-12-6-local/cuda-*-keyring.gpg/usr/share/keyrings/apt-getupdateapt-get-y install cuda-toolkit-12-6
5.查看 cuda 版本,出现下图则表示安装成功
#配置环境变量vi~/.bashrc//在文件末尾添加以下内容exportPATH=/usr/local/cuda-12.6/bin PATHexportLD_LIBRARY_PATH=/usr/local/cuda/lib64LD_LIBRARY_PATH#使配置立即生效source~/.bashrc#查看版本nvcc-V
PATHexportLD_LIBRARY_PATH=/usr/local/cuda/lib64LD_LIBRARY_PATH#使配置立即生效source~/.bashrc#查看版本nvcc-V

四、vllm 安装
#创建一个名称为vllm的python环境condacreate-nvllmpython=3.10-y#激活condaactivatevllm

- 进入终端,可以看到当前 python 版本为 3.10

3.更新 pip,保证其为最新版
#安装前更新pippython-mpipinstall--upgradepip-ihttps://mirrors.aliyun.com/pypi/simple

4.安装 vllm
python-mpipinstallvllm-ihttps://mirrors.aliyun.com/pypi/simple
安装成功如下图所示:

五、大模型下载与运行
1) 手动下载模型文件
- 访问https://huggingface.co/models或https://modelscope.cn/models官网,选择你需要下载的模型
将以下文件,全部下载到同一目录中

#设置GPU并行数为2vllmserve/mnt/models--tensor-parallel-size2--max-model-len32768--enforce-eager--gpu-memory-utilization0.9#不设置GPU并行数,使用默认值。设置api-key为test@123vllmserve/mnt/models/--max-model-len32768--enforce-eager--gpu-memory-utilization0.9--api-keytest@123
更多参数可参考官网手册:
https://vllm.hyper.ai/docs/models/engine-arguments#命名参数
(2)运行成功后,会给出 api 调用地址,如服务器为云端则需要在安全组中放行对应端口
2) 通过下载工具下载
1.安装下载工具
python-mpipinstallmodelscope-ihttps://mirrors.aliyun.com/pypi/simple

2.下载模型到指定目录内,这里以DeepSeek-r1-1.5B为例
modelscopedownload--modeldeepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B--local_dir/mnt/models2
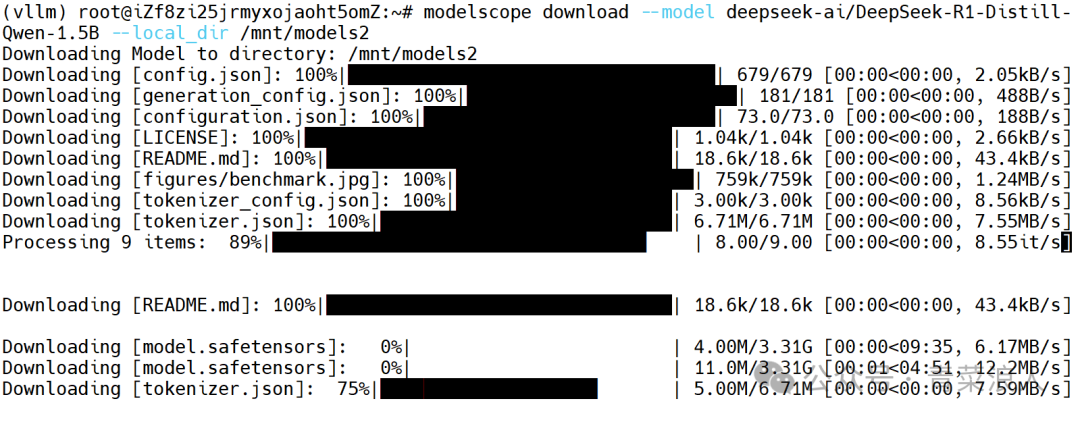
PS:启动方式与上面的一致,这里不再赘述。
客户端调用测试
1.安全组内放行服务端口
这里为云服务器部署,需要先放行 8000 端口.

2.在电脑打开客户端工具cherry studio=>新添加一个接口=>提供商类型选择OpenAI
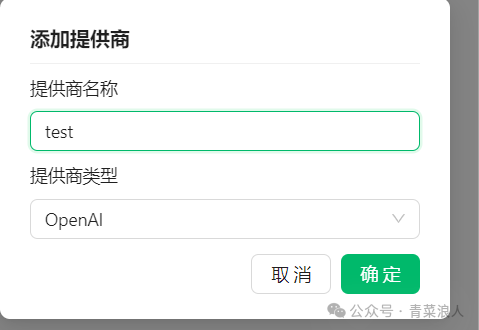
填写API地址和密钥,API地址填写为http://公网IP:8000即可。

回到对话界面,选择添加的模型,就可以正常进行对话了

PS:部署时请根据实际使用场景,配置必要的安全策略。










