|
在人工智能不断发展的领域中,理解AI工作流与AI智能体之间的区别对于有效利用这些技术至关重要。本文深入探讨了AI工作流的类型,阐释AI智能体的概念,并重点强调了二者之间的关键差异。 闲话少说,我们直接开始吧!
关于智能体(agent)的定义存在多种理解方式。一些用户将其定义为完全自主的系统,这些系统能够长期独立运行,通过使用各类工具来完成复杂任务。另一些用户则用这个词来描述遵循预定义工作流的规范性实现。 Anthropic公司将所有这些系统归类为广义的智能体系统(Agentic Systems),但对工作流(workflows)和智能体(agents)做了关键区分:- 工作流是通过预定义代码路径来协调大语言模型(LLMs)和工具的系统。
- 智能体则是大语言模型能够动态指导自身流程和工具使用,并自主掌控任务完成方式的系统。
我们可以简单通过烹饪类比来理解:工作流就像严格按照食谱一步一步操作;智能体则如同厨师根据现有食材和最佳口味现场决定菜肴烹饪方式。 在基于大语言模型(LLM)开发应用时,最佳实践是从最简单的解决方案入手,仅在必要时引入复杂架构。在某些情况下,这甚至可能意味着完全避免使用智能体系统。这类系统虽然能提升任务性能,但往往伴随着更高的延迟和成本,因此必须审慎评估这种性能与代价的取舍是否合理。当确实需要增加系统复杂度时: 不过对于多数应用场景,通过检索增强RAG与上下文示例优化来提升单个LLM调用的效率,往往已经能够满足需求。 目前已有多种框架能够简化智能体系统的实现,包括: 链接:https://langchain-ai.github.io/langgraph/
链接:https://aws.amazon.com/cn/bedrock/agents/
- Rivet: 一个支持拖拽的图形化LLM 工作流构建工具
链接:https://rivet.ironcladapp.com/
- Vellum: 另一款专注于复杂工作流流构建与测试的图形化工具
链接:https://www.vellum.ai/
这些框架通过简化调用大语言模型(LLM)、定义解析工具、链式调用等基础操作,降低了智能体系统的入门门槛。但需要留意的是:它们引入的抽象层可能掩盖底层的提示(prompt)与响应(response),导致调试难度增加,此外框架本身可能诱导开发者在简单场景中过度设计系统。 因此我们建议开发者优先直接使用LLM API——许多模式只需数行代码即可实现。若选择使用框架,请务必深入理解其底层实现逻辑,因为对框架工作机制的错误假设往往是问题产生的根源。 本节将剖析生产环境中智能体系统的常见实现范式。我们将从基础构建模块——增强型大语言模型(LLM)出发,逐步提升系统复杂度,涵盖从简单的组合式工作流程(compositional workflows)到完全自主的智能体系统(autonomous agents)的演进路径。大家可以使用任何支持结构化输出和工具调用的大语言聊天模型。下面,我们将展示安装相关包、设置API密钥以及测试Qwen2.5的结构化输出/工具调用的过程。(需要自己本地部署Ollama , 并开启相关服务)fromlangchain_openaiimportChatOpenAI
if__name__ =="__main__": llm = ChatOpenAI( model_name ="qwen2.5:7b", openai_api_key ="test", openai_api_base ="https://localhost:11444/v1", temperature =0 ) answer = llm.invoke("who are you?") print(answer.content)
结果如下: 
智能体系统的基础架构始于一个通过检索、工具调用、记忆存储等能力增强的大语言模型(LLM)。
当前主流模型已能主动运用这些能力——自主生成搜索查询、筛选适用工具、判断信息留存策略。 在实现这些增强功能时,我们建议重点关注两个实现维度: 虽然实现方式多样,其中一种典型方案是通过最新发布的模型上下文协议(Model Context Protocol)——该协议支持开发者通过轻量级客户端实现与日益丰富的第三方工具生态集成。 在本文后续讨论中,我们默认每次LLM调用均已接入上述增强能力。 # Schema for structured outputfrompydanticimportBaseModel, Field
classSearchQuery(BaseModel): search_query:str= Field(None, description="Query that is optimized web search.") justification:str= Field( None, description="Why this query is relevant to the user's request." )
# Augment the LLM with schema for structured outputstructured_llm = llm.with_structured_output(SearchQuery)
# Invoke the augmented LLMoutput = structured_llm.invoke("How does Calcium CT score relate to high cholesterol?")print(output)
# Define a tooldefmultiply(a:int, b:int) ->int: returna * b
# Augment the LLM with toolsllm_with_tools = llm.bind_tools([multiply])# Invoke the LLM with input that triggers the tool callmsg = llm_with_tools.invoke("What is 2 times 3?")# Get the tool callprint(msg.tool_calls)
结果如下: 
在提示链(prompt chaining)中,每个LLM调用都会处理前一个步骤的输出结果。正如Anthropic博客所述: 提示链通过将复杂任务分解为多个步骤序列来实现,其中每个LLM调用都会处理前一个步骤的输出。开发者可以在任何中间步骤添加程序化检查(如下图中的gate所示),从而确保整个处理流程的正确性。适用场景: 这种工作流特别适用于能够被清晰拆解为固定子任务的情况。其核心思想是通过让每个LLM调用处理更简单的任务,以牺牲延迟为代价换取更高的准确性。
提示链的典型应用案例: - 先撰写文档大纲并验证其符合性要求,再基于该大纲完成正式文档的编写
 fromtyping_extensionsimportTypedDictfromlanggraph.graphimportStateGraph, START, ENDfromlangchain_openaiimportChatOpenAI
llm = ChatOpenAI( model_name ="qwen2.5:7b", openai_api_key ="test", openai_api_base ="https://localhost:11444/v1", temperature =0 )
# Graph stateclassState(TypedDict): topic:str joke:str improved_joke:str final_joke:str
# Nodesdefgenerate_joke(state: State): """First LLM call to generate initial joke"""
msg = llm.invoke(f"Write a short joke about{state['topic']}") return{"joke": msg.content}
defcheck_punchline(state: State): """Gate function to check if the joke has a punchline"""
# Simple check - does the joke contain "?" or "!" if"?"instate["joke"]or"!"instate["joke"]: return"Fail" return" ass" ass"
defimprove_joke(state: State): """Second LLM call to improve the joke"""
msg = llm.invoke(f"Make this joke funnier by adding wordplay:{state['joke']}") return{"improved_joke": msg.content}
defpolish_joke(state: State): """Third LLM call for final polish"""
msg = llm.invoke(f"Add a surprising twist to this joke:{state['improved_joke']}") return{"final_joke": msg.content}
# Build workflowworkflow = StateGraph(State)
# Add nodesworkflow.add_node("generate_joke", generate_joke)workflow.add_node("improve_joke", improve_joke)workflow.add_node("polish_joke", polish_joke)
# Add edges to connect nodesworkflow.add_edge(START,"generate_joke")workflow.add_conditional_edges( "generate_joke", check_punchline, {"Fail":"improve_joke","ass": END})workflow.add_edge("improve_joke","polish_joke")workflow.add_edge("polish_joke", END)
# Compilechain = workflow.compile()
# Save workflowimg = chain.get_graph().draw_png()withopen("graph.jpg","wb")asf: f.write(img)
# Invokestate = chain.invoke({"topic":"cats"})print("Initial joke:")print(state["joke"])print("\n--- --- ---\n")if"improved_joke"instate: print("Improved joke:") print(state["improved_joke"]) print("\n--- --- ---\n")
print("Final joke:") print(state["final_joke"])else: print("Joke failed quality gate - no punchline detected!")
运行后工作流图示如下: 
调用输出如下: 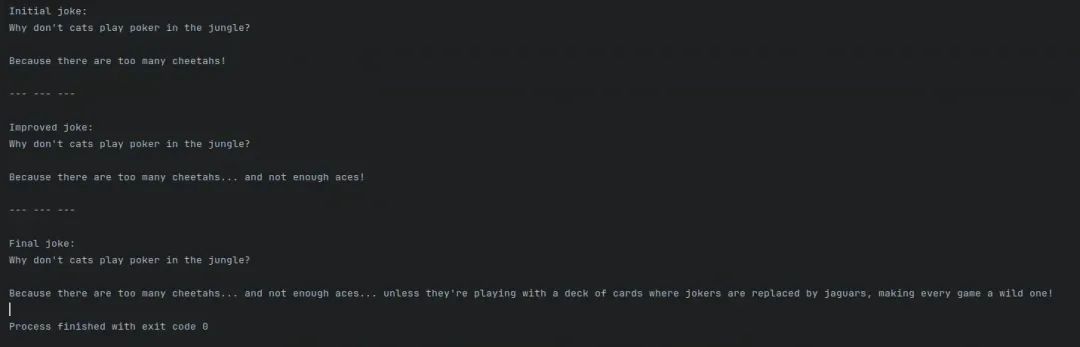
07
大语言模型有时可以并行处理任务,并通过编程方式汇总其输出结果。这种被称为"并行化"的工作流程主要通过两种关键方式实现: 适用场景:当需要将任务拆分为可并行处理的子任务以提高速度时,或者需要多重视角或多次尝试来获得更高置信度的结果时,并行化能发挥显著优势。对于需要考虑多重因素的复杂任务,通常让每个大语言模型调用专注于处理特定维度的问题会获得更优效果,这种分工机制使模型能够集中注意力处理各个具体方面。 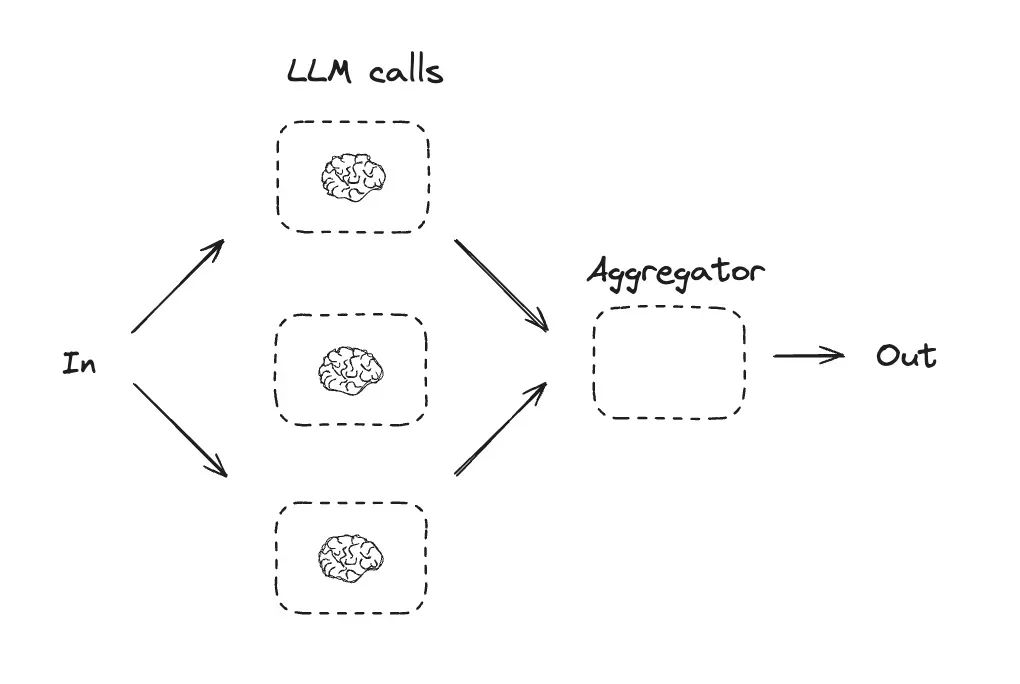
分块处理场景: 部署两个模型实例协作工作:一个处理用户查询生成核心响应,另一个专门筛查不当内容或违规请求。这种分工机制的效果通常优于让单个大语言模型同时承担内容审查和响应生成的双重职责。在评估大语言模型性能时,通过多个独立调用分别评估模型在特定提示下的不同性能维度。例如一个调用评估事实准确性,另一个评估逻辑连贯性,第三个评估指令遵循能力。 投票机制场景: 对某段代码进行漏洞审查时,使用多个差异化的检测提示并行扫描代码。只要任意提示发现潜在问题即触发告警,通过交叉验证提升漏洞识别覆盖率。评估内容合规性时部署多级审核机制:不同提示分别检测仇恨言论、暴力内容或色情元素。系统可设置差异化阈值(如需要3个提示同时标记才判定违规),通过可配置的投票规则在误判率和漏检率之间实现动态平衡。 fromtypingimportTypedDictfromlangchain_openaiimportChatOpenAIfromlanggraph.graphimportStateGraph,START,END#GraphstateclassState(TypedDict):topic:strjoke:strstory:strpoem:strcombined_output:str#llmllm=ChatOpenAI(model_name="qwen2.5:7b",openai_api_key="test",openai_api_base="https://localhost:11444/v1",temperature=0)#Nodesdefcall_llm_1(state:State):"""FirstLLMcalltogenerateinitialjoke"""msg=llm.invoke(f"Writeajokeabout{state['topic']}")return{"joke":msg.content}defcall_llm_2(state:State):"""SecondLLMcalltogeneratestory"""msg=llm.invoke(f"Writeastoryabout{state['topic']}")return{"story":msg.content}defcall_llm_3(state:State):"""ThirdLLMcalltogeneratepoem"""msg=llm.invoke(f"Writeapoemabout{state['topic']}")return{"poem":msg.content}defaggregator(state:State):"""Combinethejokeandstoryintoasingleoutput"""combined=f"Here'sastory,joke,andpoemabout{state['topic']}!\n\n"combined+=f"STORY:\n{state['story']}\n\n"combined+=f"JOKE:\n{state['joke']}\n\n"combined+=f"OEM:\n{state['poem']}"return{"combined_output":combined}#Buildworkflowparallel_builder=StateGraph(State)#Addnodesparallel_builder.add_node("call_llm_1",call_llm_1)parallel_builder.add_node("call_llm_2",call_llm_2)parallel_builder.add_node("call_llm_3",call_llm_3)parallel_builder.add_node("aggregator",aggregator)#Addedgestoconnectnodesparallel_builder.add_edge(START,"call_llm_1")parallel_builder.add_edge(START,"call_llm_2")parallel_builder.add_edge(START,"call_llm_3")parallel_builder.add_edge("call_llm_1","aggregator")parallel_builder.add_edge("call_llm_2","aggregator")parallel_builder.add_edge("call_llm_3","aggregator")parallel_builder.add_edge("aggregator",END)parallel_workflow=parallel_builder.compile()#Saveworkflowimg=parallel_workflow.get_graph().draw_png()withopen("parallel_graph.jpg","wb")asf:f.write(img)#Invokestate=parallel_workflow.invoke({"topic":"cats"})print(state["combined_output"])运行后工作流图示如下: 调用后输出如下:
08
路由(Routing)对输入进行分类并将其引导至后续任务。正如Anthropic博客中所提到的:路由对输入进行分类,并将其引导至专门的后续任务。这种工作流实现了关注点的分离,并能够构建更专业的提示。如果没有这种工作流程,针对某一种输入的优化可能会损害其他输入的性能。
何时使用这种工作流程:路由适用于复杂任务,其中存在明显不同的类别,这些类别更适合分开处理,并且分类可以通过LLM或更传统的分类模型/算法准确完成。路由发挥作用的示例: - 将不同类型的客户服务查询(一般问题、退款请求、技术支持)引导至不同的下游流程、提示和工具。
- 将简单/常见的问题路由到较小的模型(如Claude 3.5 Haiku),而将困难/不常见的问题路由到更强大的模型(如Claude 3.5 Sonnet),以优化成本和速度。
fromtypingimportTypedDictfromtyping_extensionsimportLiteralfrompydanticimportBaseModel,Fieldfromlangchain_openaiimportChatOpenAIfromlanggraph.graphimportStateGraph,START,ENDfromlangchain_core.messagesimportHumanMessage, SystemMessage
# Schema for structured output to use as routing logicclassRoute(BaseModel): step iteral["poem","story","joke"] = Field( iteral["poem","story","joke"] = Field( None, description="The next step in the routing process" )
# Augment the LLM with schema for structured outputllm = ChatOpenAI( model_name ="qwen2.5:7b", openai_api_key ="test", openai_api_base ="https://localhost:11444/v1", temperature =0 )router = llm.with_structured_output(Route)
# StateclassState(TypedDict): input:str decision:str output:str
# Nodesdefllm_call_1(state: State): """Write a story"""
result = llm.invoke(state["input"]) return{"output": result.content}
defllm_call_2(state: State): """Write a joke"""
result = llm.invoke(state["input"]) return{"output": result.content}
defllm_call_3(state: State): """Write a poem"""
result = llm.invoke(state["input"]) return{"output": result.content}
defllm_call_router(state: State): """Route the input to the appropriate node"""
# Run the augmented LLM with structured output to serve as routing logic decision = router.invoke( [ SystemMessage( content="Route the input to story, joke, or poem based on the user's request." ), HumanMessage(content=state["input"]), ] )
return{"decision": decision.get("step")}
# Conditional edge function to route to the appropriate nodedefroute_decision(state: State): # Return the node name you want to visit next ifstate["decision"] =="story": return"llm_call_1" elifstate["decision"] =="joke": return"llm_call_2" elifstate["decision"] =="poem": return"llm_call_3"
# Build workflowrouter_builder = StateGraph(State)
# Add nodesrouter_builder.add_node("llm_call_1", llm_call_1)router_builder.add_node("llm_call_2", llm_call_2)router_builder.add_node("llm_call_3", llm_call_3)router_builder.add_node("llm_call_router", llm_call_router)
# Add edges to connect nodesrouter_builder.add_edge(START,"llm_call_router")router_builder.add_conditional_edges( "llm_call_router", route_decision, { # Name returned by route_decision : Name of next node to visit "llm_call_1":"llm_call_1", "llm_call_2":"llm_call_2", "llm_call_3":"llm_call_3", },)router_builder.add_edge("llm_call_1", END)router_builder.add_edge("llm_call_2", END)router_builder.add_edge("llm_call_3", END)
# Compile workflowrouter_workflow = router_builder.compile()
# Save the workflowimg = router_workflow.get_graph().draw_png()withopen("router_graph.jpg","wb")asf: f.write(img)
# Invokestate = router_workflow.invoke({"input":"Write me a joke about cats"})print(state["output"])
运行后工作流图示如下: 调用后输出如下: 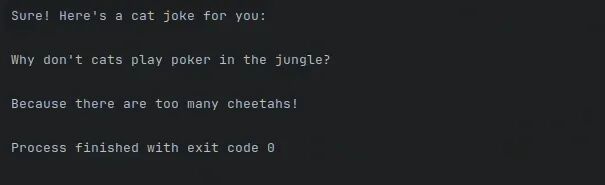
09
协调者-工作者模式通过智能任务调度实现复杂问题处理。正如Anthropic技术博客所述:在协调者-工作者工作流中,中央协调者(通常是大语言模型)动态分解任务,将子任务分派给多个工作者模型,并整合它们的处理结果。
适用场景:该模式特别适合无法预先确定子任务结构的复杂场景。例如在代码修改场景中,需要变更的文件数量、每个文件的修改方式都取决于具体任务需求。虽然与并行化在结构上类似,但其核心差异在于动态灵活性——子任务并非预先定义,而是由协调者根据输入内容实时决策生成。 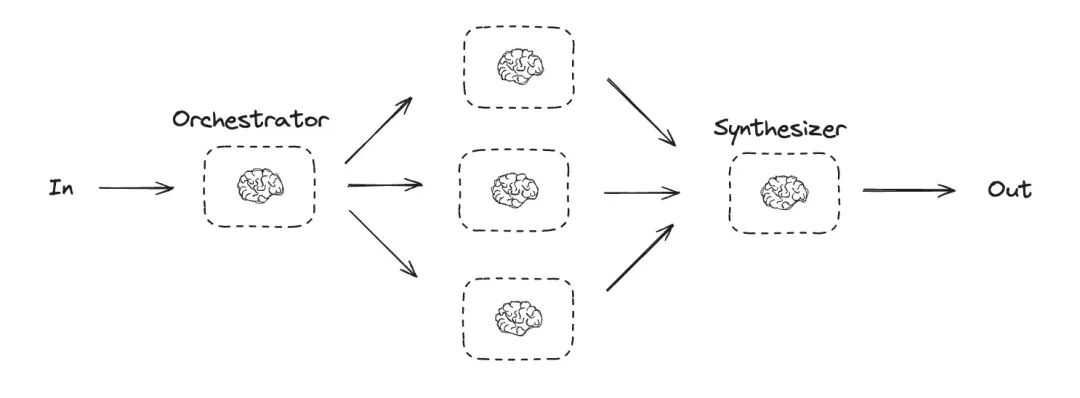
协调者-工作者模式应用案例: - 智能代码重构引擎
开发能自动实施复杂代码变更的AI产品:协调者分析需求后,动态识别需要修改的代码文件,为每个文件生成独立修改指令分派给工作者模型,最终整合所有变更并验证系统兼容性。
- 多源情报分析系统
构建信息检索解决方案:协调者将搜索任务拆解为多个垂直领域的子查询(如技术文档、行业报告、社交媒体),工作者模型并行执行专项检索并提炼关键信息,协调者综合所有结果生成多维分析报告。
用例代码如下: fromtypingimportAnnotated,Listimportoperator
# Schema for structured output to use in planningclassSection(BaseModel): name:str= Field( description="Name for this section of the report.", ) description:str= Field( description="Brief overview of the main topics and concepts to be covered in this section.", )
classSections(BaseModel): sectionsist[Section] = Field( description="Sections of the report.", )
# Augment the LLM with schema for structured outputfromlangchain_anthropicimportChatAnthropicllm = ChatAnthropic(model="claude-3-5-sonnet-latest")planner = llm.with_structured_output(Sections)
由于协调者-工作者模式在工程实践中广泛应用,LangGraph框架专门设计了Send API来支持此类工作流。它允许大家动态创建工作者节点,并向每个节点发送特定的输入。每个工作者都有自己的状态,所有工作者的输出都会被写入一个共享的状态键中,协调者图可以访问该键。这使得协调者能够获取所有工作者的输出,并将其综合为最终输出。如下图所示,我们遍历一个部分列表,并将每个部分Send到一个工作者节点。 fromlanggraph.constantsimportSend
# Graph stateclassState(TypedDict): topic:str# Report topic sections:list[Section] # List of report sections completed_sections: Annotated[ list, operator.add ] # All workers write to this key in parallel final_report:str# Final report
# Worker stateclassWorkerState(TypedDict): section: Section completed_sections: Annotated[list, operator.add]
# Nodesdeforchestrator(state: State): """Orchestrator that generates a plan for the report"""
# Generate queries report_sections = planner.invoke( [ SystemMessage(content="Generate a plan for the report."), HumanMessage(content=f"Here is the report topic:{state['topic']}"), ] )
return{"sections": report_sections.sections}
defllm_call(state: WorkerState): """Worker writes a section of the report"""
# Generate section section = llm.invoke( [ SystemMessage( content="Write a report section following the provided name and description. Include no preamble for each section. Use markdown formatting." ), HumanMessage( content=f"Here is the section name:{state['section'].name}and description:{state['section'].description}" ), ] )
# Write the updated section to completed sections return{"completed_sections": [section.content]}
defsynthesizer(state: State): """Synthesize full report from sections"""
# List of completed sections completed_sections = state["completed_sections"]
# Format completed section to str to use as context for final sections completed_report_sections ="\n\n---\n\n".join(completed_sections)
return{"final_report": completed_report_sections}
# Conditional edge function to create llm_call workers that each write a section of the reportdefassign_workers(state: State): """Assign a worker to each section in the plan"""
# Kick off section writing in parallel via Send() API return[Send("llm_call", {"section": s})forsinstate["sections"]]
# Build workfloworchestrator_worker_builder = StateGraph(State)
# Add the nodesorchestrator_worker_builder.add_node("orchestrator", orchestrator)orchestrator_worker_builder.add_node("llm_call", llm_call)orchestrator_worker_builder.add_node("synthesizer", synthesizer)
# Add edges to connect nodesorchestrator_worker_builder.add_edge(START,"orchestrator")orchestrator_worker_builder.add_conditional_edges( "orchestrator", assign_workers, ["llm_call"])orchestrator_worker_builder.add_edge("llm_call","synthesizer")orchestrator_worker_builder.add_edge("synthesizer", END)
# Compile the workfloworchestrator_worker = orchestrator_worker_builder.compile()
# Show the workflowdisplay(Image(orchestrator_worker.get_graph().draw_mermaid_png()))
# Invokestate = orchestrator_worker.invoke({"topic":"Create a report on LLM scaling laws"})
fromIPython.displayimportMarkdownMarkdown(state["final_report"])
运行后工作流图示如下: 
调用后输出如下: 
10
评估者-优化器工作流通过双模型协同实现迭代优化。在该流程中,一个模型负责生成初始响应,另一个模型在循环中执行评估与反馈修正。适用场景:该模式尤其适用于具备明确评估标准且迭代优化能产生显著价值增益的场景。有效应用的两个关键标志:首先,当人类提供明确反馈时,大语言模型的输出质量能获得可验证的提升;其次,模型自身具备提供类似反馈的能力。这种机制类似于人类作者在撰写精品文档时经历的"初稿-评审-修正"循环过程。 评估者-优化器模式应用案例: 用例代码如下: #GraphstateclassState(TypedDict):joke:strtopic:strfeedback:strfunny_or_not:str#SchemaforstructuredoutputtouseinevaluationclassFeedback(BaseModel):gradeiteral["funny","notfunny"]=Field(description="Decideifthejokeisfunnyornot.",)feedback:str=Field(description="Ifthejokeisnotfunny,providefeedbackonhowtoimproveit.",)#AugmenttheLLMwithschemaforstructuredoutputevaluator=llm.with_structured_output(Feedback)#Nodesdefllm_call_generator(state:State):"""LLMgeneratesajoke"""ifstate.get("feedback"):msg=llm.invoke(f"Writeajokeabout{state['topic']}buttakeintoaccountthefeedback:{state['feedback']}")else:msg=llm.invoke(f"Writeajokeabout{state['topic']}")return{"joke":msg.content}defllm_call_evaluator(state:State):"""LLMevaluatesthejoke"""grade=evaluator.invoke(f"Gradethejoke{state['joke']}")return{"funny_or_not":grade.grade,"feedback":grade.feedback}#Conditionaledgefunctiontoroutebacktojokegeneratororendbaseduponfeedbackfromtheevaluatordefroute_joke(state:State):"""Routebacktojokegeneratororendbaseduponfeedbackfromtheevaluator"""ifstate["funny_or_not"]=="funny":return"Accepted"elifstate["funny_or_not"]=="notfunny":return"Rejected+Feedback"#Buildworkflowoptimizer_builder=StateGraph(State)#Addthenodesoptimizer_builder.add_node("llm_call_generator",llm_call_generator)optimizer_builder.add_node("llm_call_evaluator",llm_call_evaluator)#Addedgestoconnectnodesoptimizer_builder.add_edge(START,"llm_call_generator")optimizer_builder.add_edge("llm_call_generator","llm_call_evaluator")optimizer_builder.add_conditional_edges("llm_call_evaluator",route_joke,{#Namereturnedbyroute_joke:Nameofnextnodetovisit"Accepted":END,"Rejected+Feedback":"llm_call_generator",},)#Compiletheworkflowoptimizer_workflow=optimizer_builder.compile()#Showtheworkflowdisplay(Image(optimizer_workflow.get_graph().draw_mermaid_png()))#Invokestate=optimizer_workflow.invoke({"topic":"Cats"})print(state["joke"]) 运行后工作流图示如下: 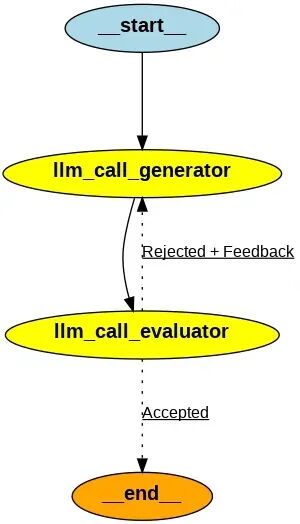
调用后输出如下: 11
智能体(Agents)通常被实现为一个大型语言模型(LLM),在一个循环中根据环境反馈执行操作(通过工具调用)。正如Anthropic博客中所指出的:智能体能够处理复杂的任务,但其实现往往相对简单。它们通常只是LLM在一个循环中根据环境反馈使用工具。因此,清晰而周到地设计工具集及其文档至关重要。
何时使用智能体:智能体适用于开放式问题,这些问题难以或无法预测所需的步骤数量,并且无法硬编码固定的路径。LLM可能会进行多次操作,因此大家必须对其决策能力有一定的信任。智能体的自主性使其成为在受信任环境中扩展任务的理想选择。
 智能体的自主性也意味着更高的成本和错误累积的可能性。我们建议在沙盒环境中进行广泛的测试,并设置适当的防护措施。 智能体适用的示例:以下示例来自Anthropic的实践:
工具定义代码如下: fromlangchain_core.toolsimporttool
# Define tools@tooldefmultiply(a:int, b:int) ->int: """Multiply a and b.
Args: a: first int b: second int """ returna * b
@tooldefadd(a:int, b:int) ->int: """Adds a and b.
Args: a: first int b: second int """ returna + b
@tooldefdivide(a:int, b:int) ->float: """Divide a and b.
Args: a: first int b: second int """ returna / b
# Augment the LLM with toolstools = [add, multiply, divide]tools_by_name = {tool.name: toolfortoolintools}llm_with_tools = llm.bind_tools(tools)
调用代码如下: fromlanggraph.graphimportMessagesStatefromlangchain_core.messagesimportSystemMessage, HumanMessage, ToolMessage
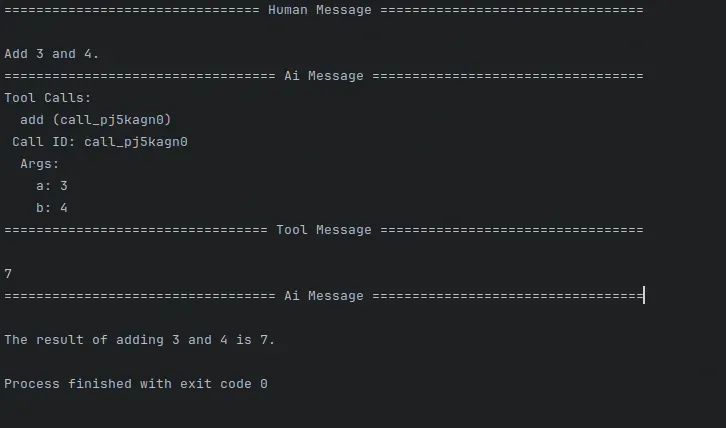
# Nodesdefllm_call(state: MessagesState): """LLM decides whether to call a tool or not""" return{ "messages": [ llm_with_tools.invoke( [ SystemMessage( content="You are a helpful assistant tasked with performing arithmetic on a set of inputs." ) ] + state["messages"] ) ] }deftool_node(state:dict): """erforms the tool call""" result = [] fortool_callinstate["messages"][-1].tool_calls: tool = tools_by_name[tool_call["name"]] observation = tool.invoke(tool_call["args"]) result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"])) return{"messages": result}# Conditional edge function to route to the tool node or end based upon whether the LLM made a tool calldefshould_continue(state: MessagesState) ->Literal["environment", END]: """Decide if we should continue the loop or stop based upon whether the LLM made a tool call""" messages = state["messages"] last_message = messages[-1] # If the LLM makes a tool call, then perform an action iflast_message.tool_calls: return"Action" # Otherwise, we stop (reply to the user) returnEND# Build workflowagent_builder = StateGraph(MessagesState)# Add nodesagent_builder.add_node("llm_call", llm_call)agent_builder.add_node("environment", tool_node)# Add edges to connect nodesagent_builder.add_edge(START,"llm_call")agent_builder.add_conditional_edges( "llm_call", should_continue, { # Name returned by should_continue : Name of next node to visit "Action":"environment", END: END, },)agent_builder.add_edge("environment","llm_call")# Compile the agentagent = agent_builder.compile()# Show the agentdisplay(Image(agent.get_graph(xray=True).draw_mermaid_png()))# Invokemessages = [HumanMessage(content="Add 3 and 4.")]messages = agent.invoke({"messages": messages})forminmessages["messages"]: m.pretty_print()
运行结果如下: 
12
AI智能体(AI Agents)与代理工作流(Agentic Workflows)是互补的,可以整合以实现最佳效果,尤其是在复杂的现实应用中:●增强自动化:AI智能体自主处理特定任务,而代理工作流则将这些任务协调为一个连贯、高效的流程。 典型案例:智能制造中的整合应用 在智能工厂系统中: ●AI Agent层: 监测设备运行状态,预测故障并触发维护指令 基于实时数据优化生产排程(如能耗、订单优先级)
●Agentic Workflow层: 13
LLM(大型语言模型)领域的成功,并不在于构建最复杂的系统,而在于构建适合你需求的系统。从简单的提示开始,通过全面的评估进行优化,只有在更简单的解决方案无法满足需求时,才引入多步骤的代理系统。- 过程透明化:明确展示智能体的规划步骤,使其决策过程清晰可见。
- 接口精研化:通过详尽的工具文档和测试,确保接口的可靠性和易用性。
虽然现成框架可以帮助大家快速上手,但在进入生产环境时,不要犹豫减少抽象层,使用基础组件进行构建。遵循这些原则,我们可以创建出不仅功能强大,而且可靠、可维护并赢得用户信任的智能体系统。 |










