|
本地部署AI应用的一个重要原因就是要用RAG技术对知识库进行管理。 简单来说就是大语言模型的上下文通常只有16K-128K,也就是3万字到12万字,这对于知识库管理显然是不够,且过长的文本对于大模型来说存在注意力衰退问题。当然也有例外,比如谷歌的Gemini和海螺的Minimax,这两者的上下文分别达到了一百万和四百万。 RAG技术就是通过embedding模型对大文本进行向量化匹配问题进行初步筛选,再由reranke模型进行排序,再交由大语言模型进行处理。有兴趣的可以看: [[RAG系列(一):一文让你由浅到深搞懂RAG实现]] [[为什么RAG一定需要Rerank?]] 本文以在MAC上部署Xinference+bge-m3/bge-reranker-v2-m3为例:
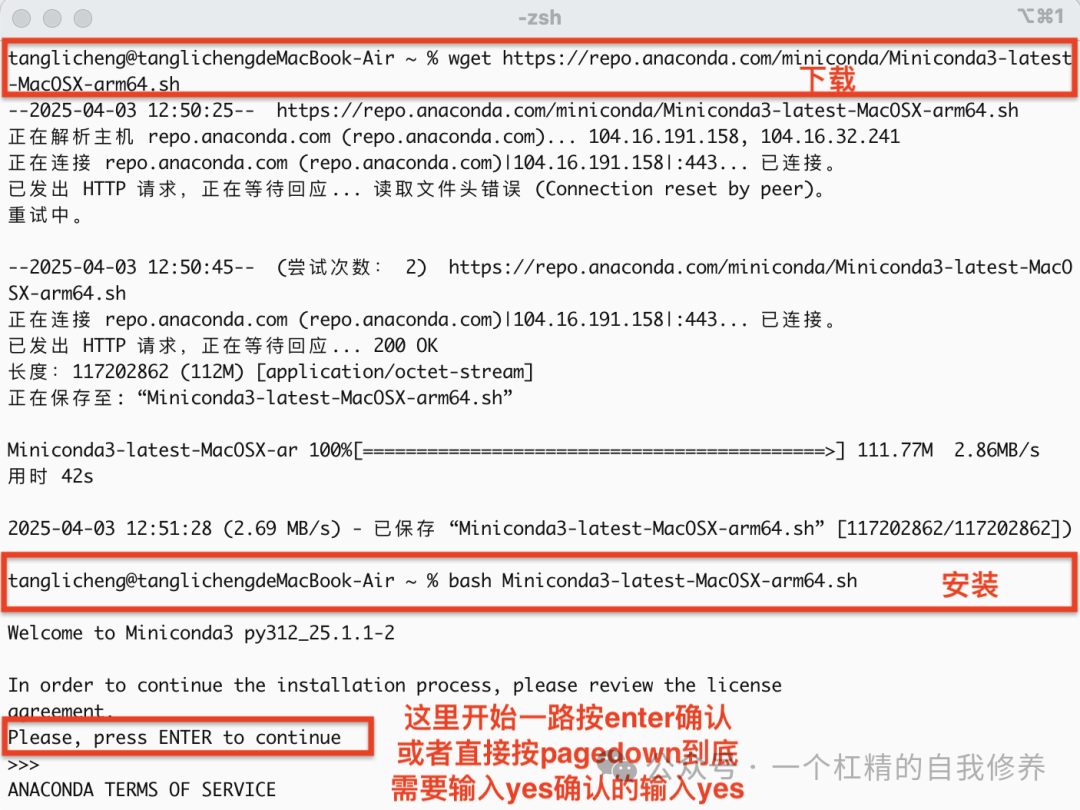
一、部署Conda1. 下载Miniconda安装脚本下载Mac系统的安装脚本: wget https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh
注1:如果出现zsh: command not found: wget时,执行brew install wget来安装 wget ,也可以拿报错日志问豆包注2:Intel芯片Mac或PC需访问Miniconda官网查询对应版本替换脚本文件名
安装wget,如果连homebrew也没有,问大模型如何安装homebrew 2. 运行安装脚本bash Miniconda3-latest-MacOSX-arm64.sh
3. 刷新Shell环境source~/.bashrc
#刷新环境
~/miniconda3/bin/conda init zsh
#激活conda ~换成实际路径
4. 验证安装conda --version
二、使用Conda安装Xinference1. 创建并激活虚拟环境conda create --name xinference_env310 python=3.10
#创建虚拟环境
conda activate xinference_env310
#激活虚拟环境
2. 安装必要依赖pip install torch
pip install"transformers>=4.36.0"
pip install"sentence-transformers>=3.2.0"
3. 硬件加速(可选)# Apple M系列
CMAKE_ARGS="-DLLAMA_METAL=on"pip install llama-cpp-python
# 英伟达显卡
CMAKE_ARGS="-DLLAMA_CUBLAS=on"pip install llama-cpp-python
# AMD显卡
CMAKE_ARGS="-DLLAMA_HIPBLAS=on"pip install llama-cpp-python
4. 安装Xinferencepip install xinference
三、启动Xinference服务# 前台运行
xinference-local --host 0.0.0.0 --port 9997
# 后台运行
nohup bash -c'xinference-local --host 0.0.0.0 --port 9997'> xinference.log 2>&1 &
验证地址:http://localhost:9997
四、模型安装通过WebUI下载: - 推荐模型:
bge-m3、bge-reranker-v2-m3
五、创建后台守护服务(macOS)
source/opt/anaconda3/etc/profile.d/conda.sh
conda activate xinference_env
nohup xinference-local -H 0.0.0.0 --port 9997 > /tmp/xinference.log 2>&1 &
保存为XinferenceDaemon.ap``p至/Applications 系统偏好设置 → 用户与群组 → 登录项中添加该应用
查看日志: tail -f /tmp/xinference.log
六、dify调用配置安装OpenAI-API-Compatible插件 填入对应的Xinference接口信息(如host.docker.internal:9997)
| 









