|
当国内大模型圈正为智谱启动A股上市的消息兴奋时,GLM系列再次以其标志性的“卷王”姿态横扫市场。本月继GLM-4.6V、GLM-ASR、GLM‑TTS以及AutoGLM之后,更是把刚发布的旗舰GLM-4.7也直接开源了! 这次,一个核心变化是:GLM-4.7 不再是单纯的代码大模型,而是一个任务交付引擎。以任务交付核心,驱动开发流程形成从需求到成品的端到端闭环,一次性交付完整、可运行的解决方案。 实测上百项任务表明,GLM-4.7在Claude Code中的任务完成率显著提升,其定位已超越代码生成。 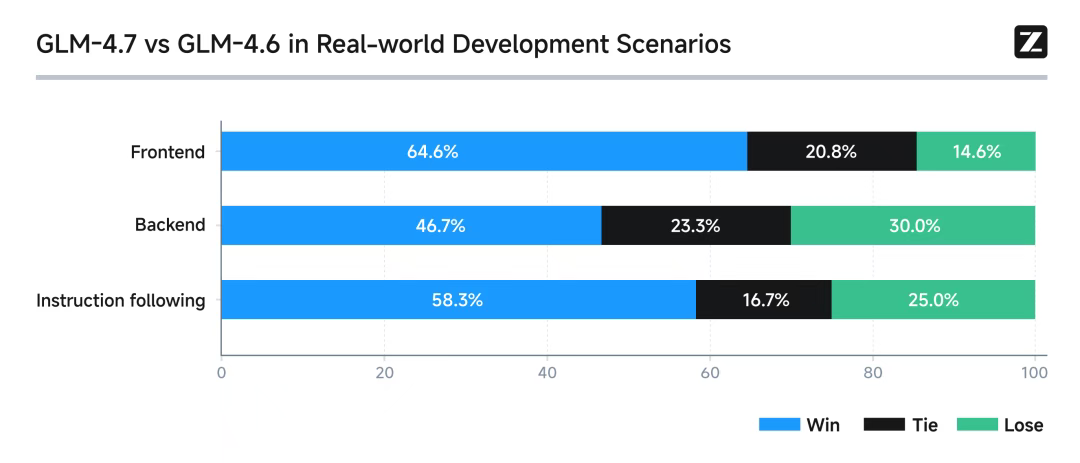 模型好不好用,光看榜单还不够,得上手,咱们直接实测一下GLM-4.7真实任务完成效果~ 月初,NeurIPS 2025会议结束,热点是啥,有哪些关键信息?是不是很想知道,这也是大家日常高频场景。 paper的摘要、作者、类型都有 在Claude Code中简单配置后就可以开工了 setANTHROPIC_BASE_URL=https://open.bigmodel.cn/api/anthropic
setANTHROPIC_AUTH_TOKEN=API-KEY
setANTHROPIC_MODEL=glm-4.7-coding-preview
有近6000篇文章的csv文件,我本以为它会要这要那,或者直接摆烂。但GLM-4.7的反应堪称“顶级外援”: 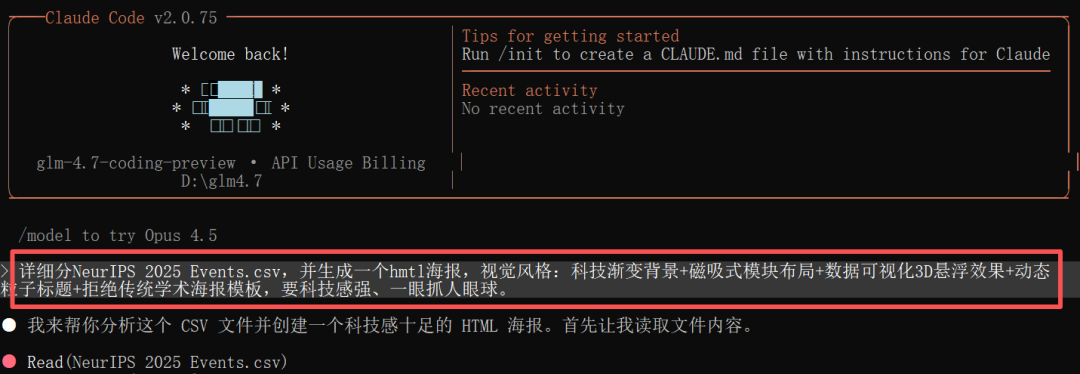 - 自动拆解任务:它没有盲目开始,而是先请求获取前50行数据作为“样章”,以理解数据结构。
 视觉效果也做了更精细化的拆解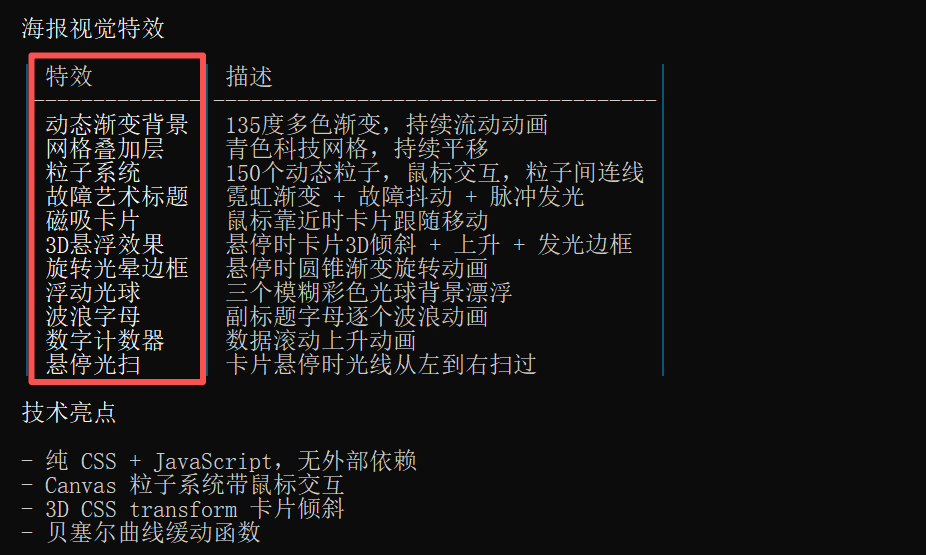 - 稳健分析:拿到数据后,直接写了一个完整的 analyze_neurips.py 脚本。不仅做了基础论文类型分布统计,还进行了关键词,逻辑清晰,注释到位。
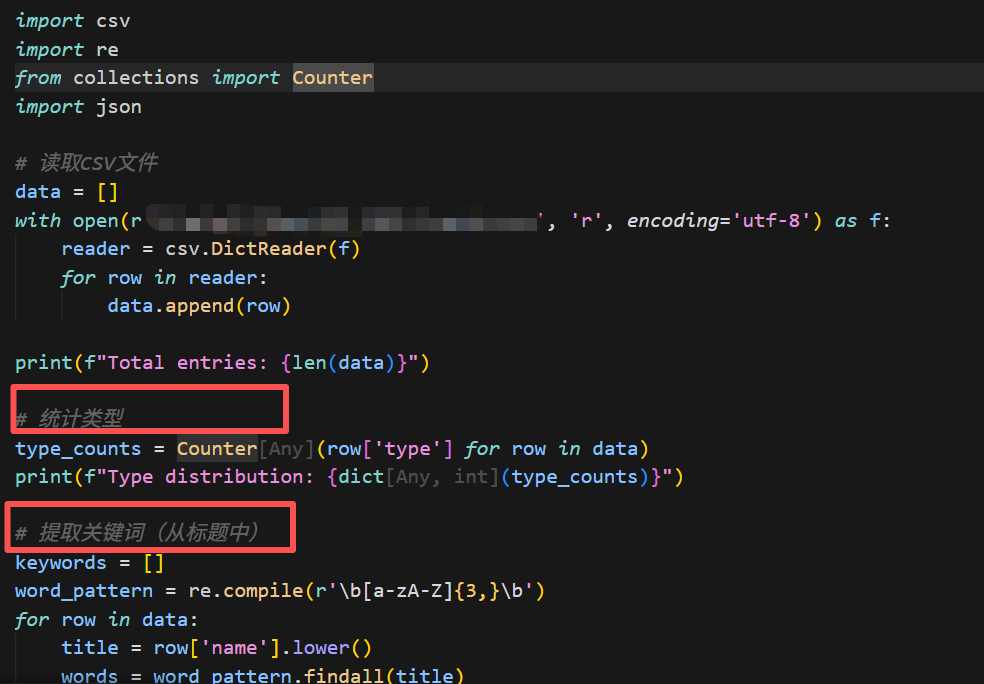 - 生成视觉炸弹:重头戏来了。它根据分析结果,生成了一个单独的html文件。打开的一瞬间,我就知道GLM-4.7它赢了:深蓝至紫的科技渐变背景上,动态粒子在标题文字间流动;关键数据(如“文章类型分布”)以3D悬浮柱状图的形式呈现,鼠标划过会有磁吸般的动态效果;
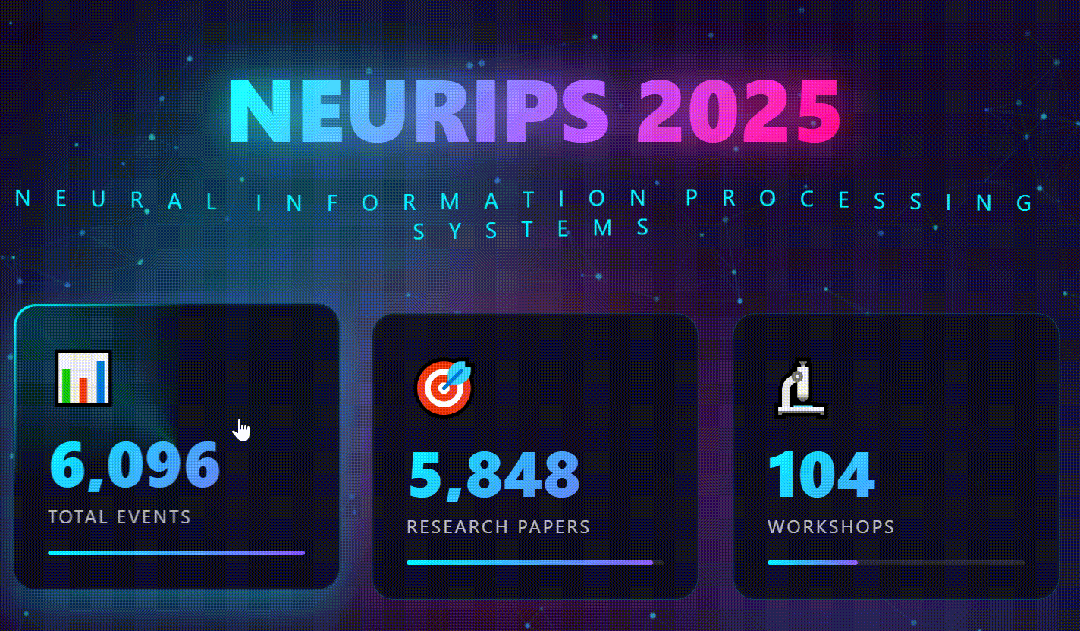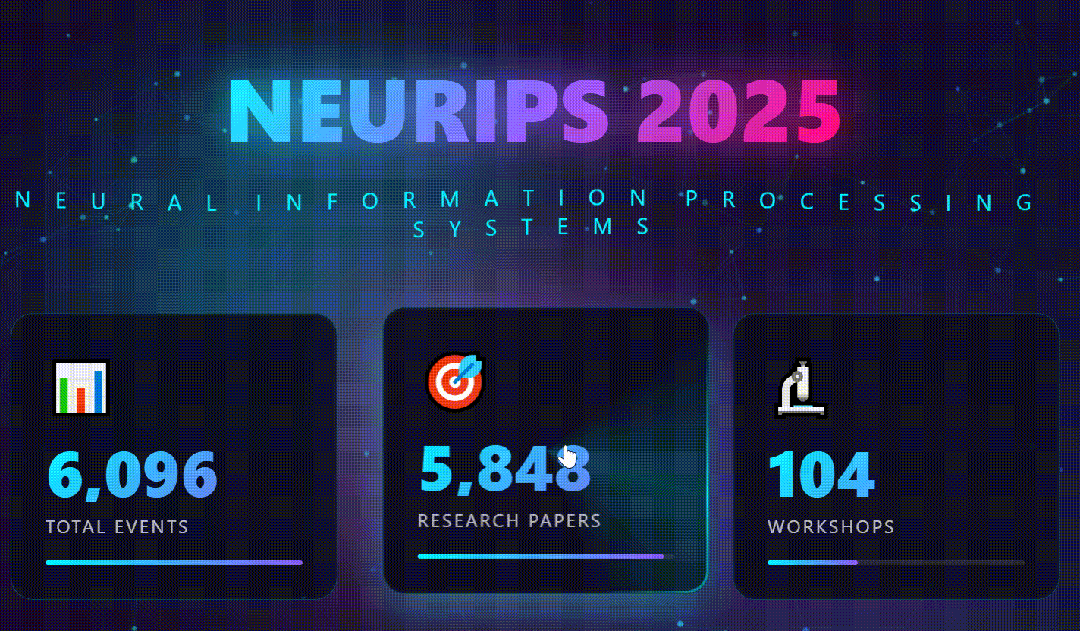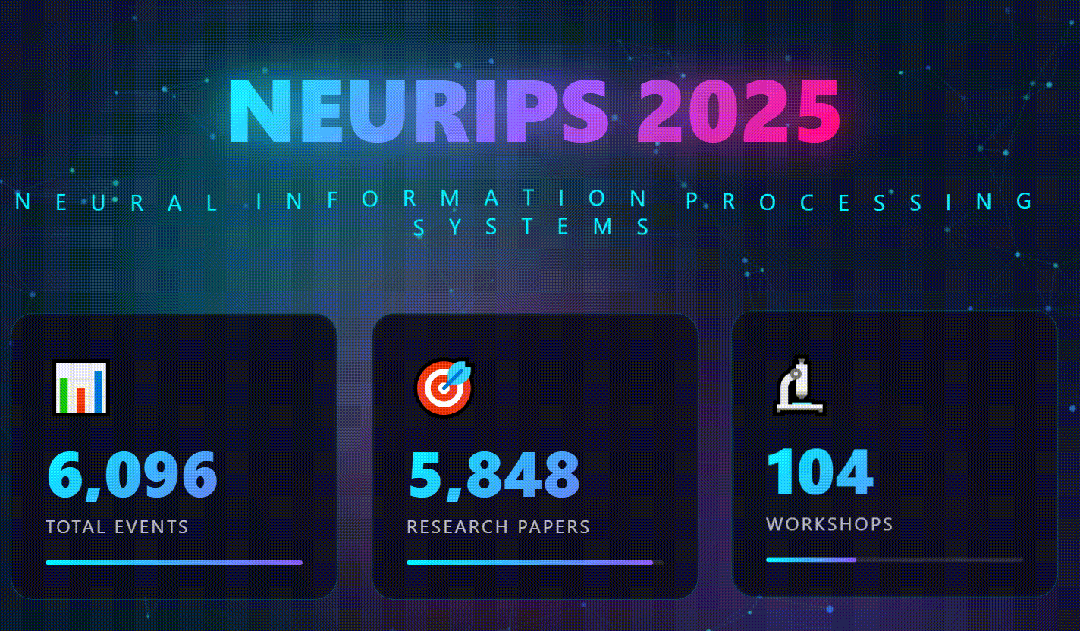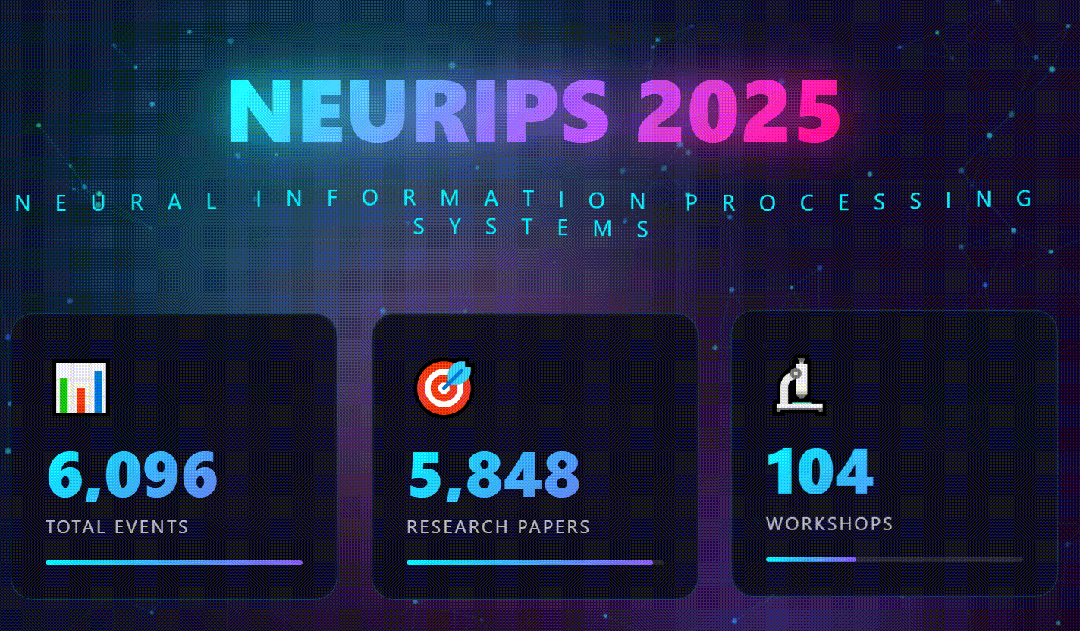 光有静态海报还不够。我决定继续压榨GLM-4.7,毕竟在Code Arena评测中,GLM-4.7拿下了两个双冠,开源第一、国产第一,超越GPT-5.2。  能不能基于这个论文库,设计一个交互式论文探索与分析网页?要能搜索、能筛选、能点击查看详情的那种。  GLM-4.7再次展现了其“全栈开发”的潜力。它没有东拼西凑,而是给出了一个完整的技术方案:  语义地形图、热门话题词云、全局搜索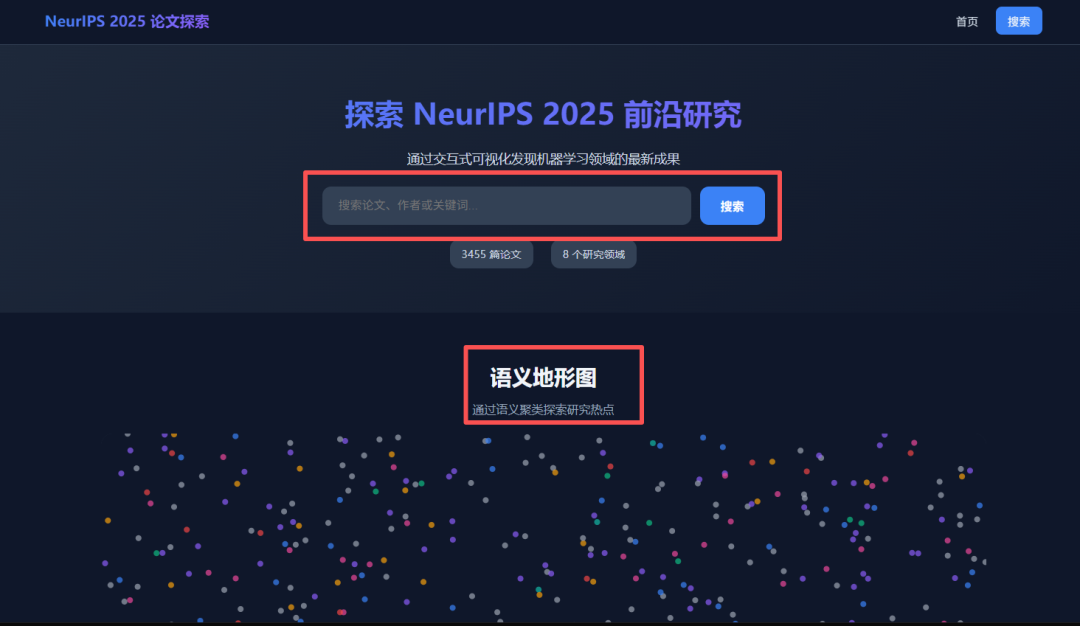 搜索页,左侧过滤器(类型、代码、作者),右侧卡片网格结果,PDF跳转下载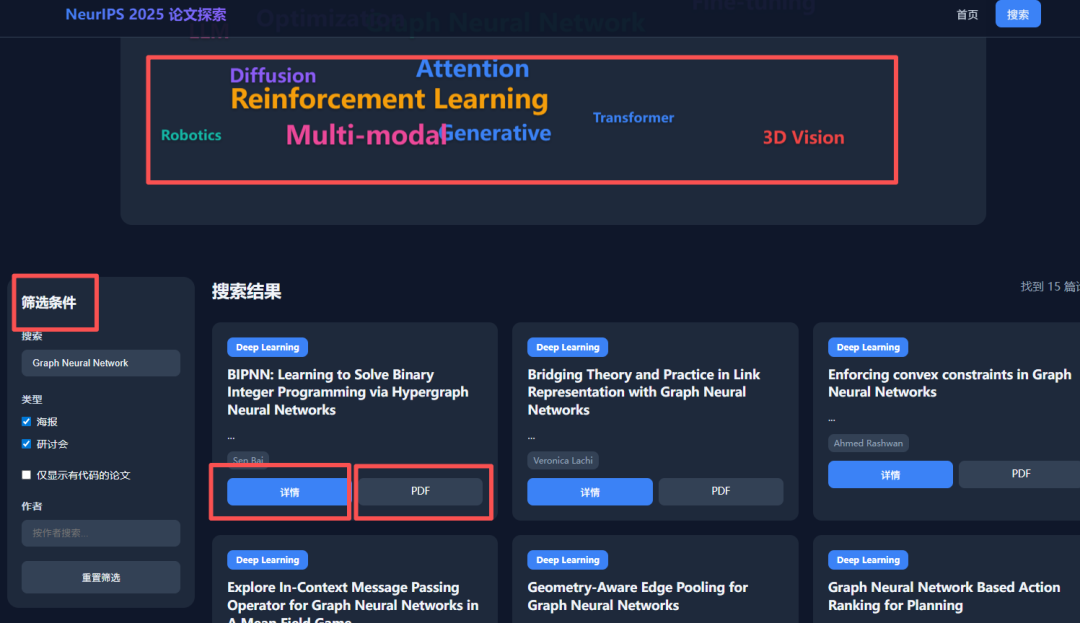 详情页,左侧:论文元数据,右侧:AI 聊天助手 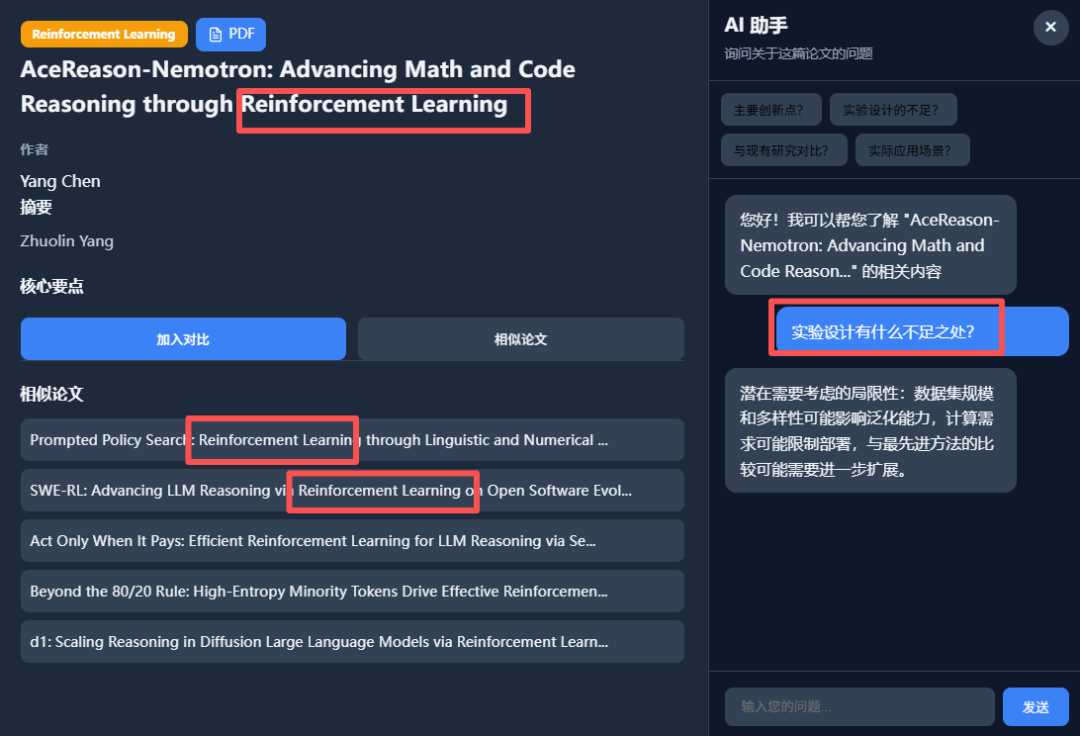 整体效果演示 最后一个任务,直击广大开发者的痛点:重构遗留代码。很多做RAG的小伙伴都用过raptor(树层级检索)框架:我只想保留其核心的tree的构建逻辑,其余部分请你用更现代、更清晰的方式对其进行重构。 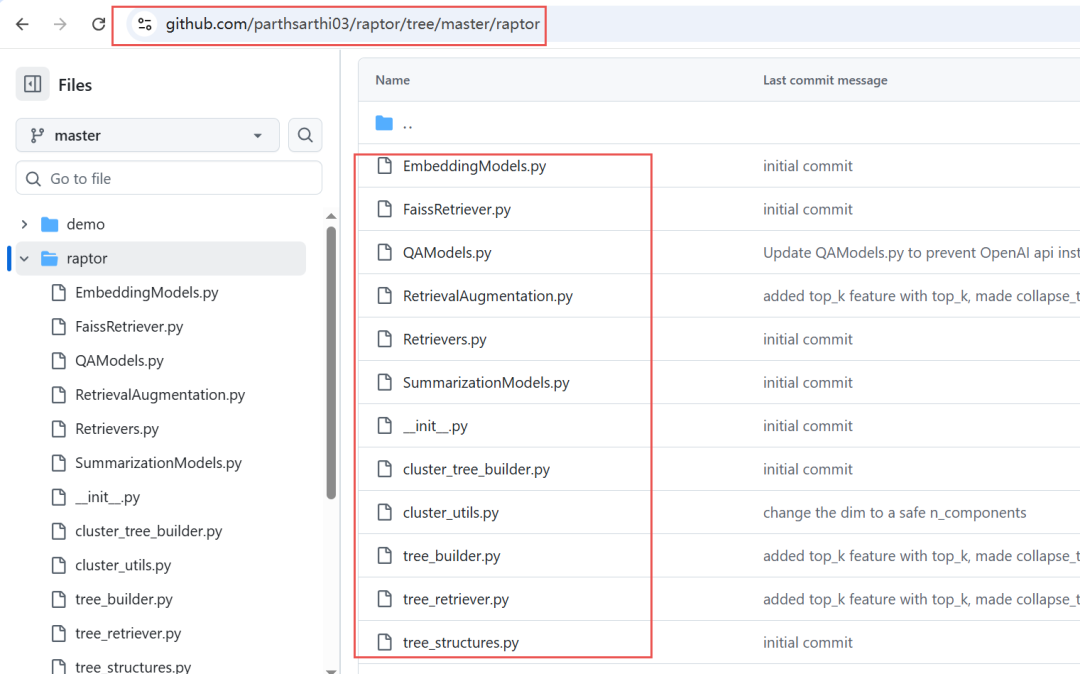 面对这块难啃的骨头,GLM-4.7开启了“深度思考”模式。它首先精准地识别出原代码中树结构构建、节点编码和检索这三个核心模块,然后果断地将臃肿的混合类拆分为职责单一的独立类。它引入了更清晰的配置文件管理,用dataclass优化数据结构,并重写了混乱的递归逻辑,使其更易读、易维护。 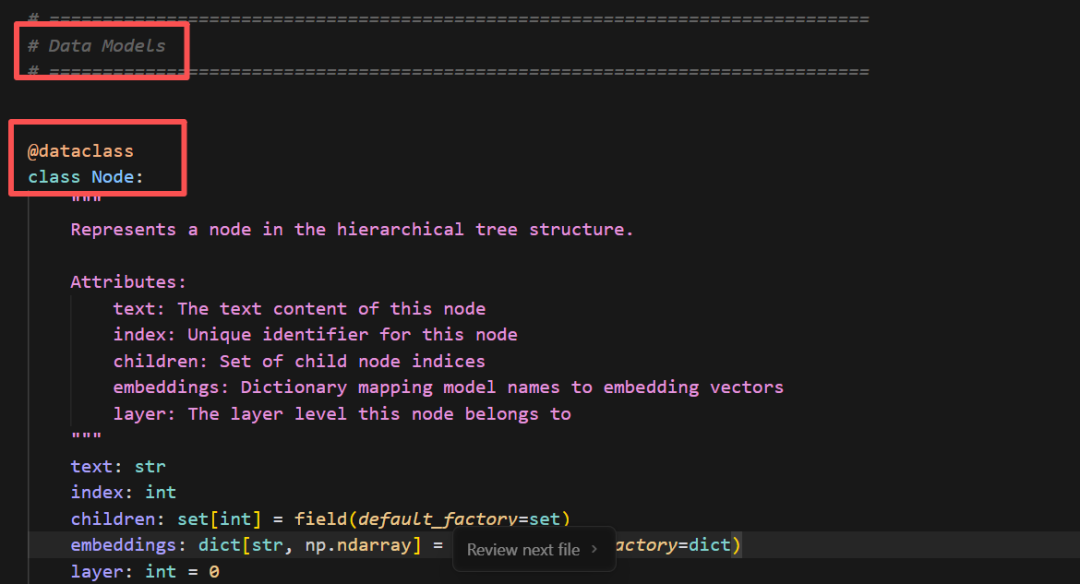 最后,它还贴心地补上了关键单元测试的示例。 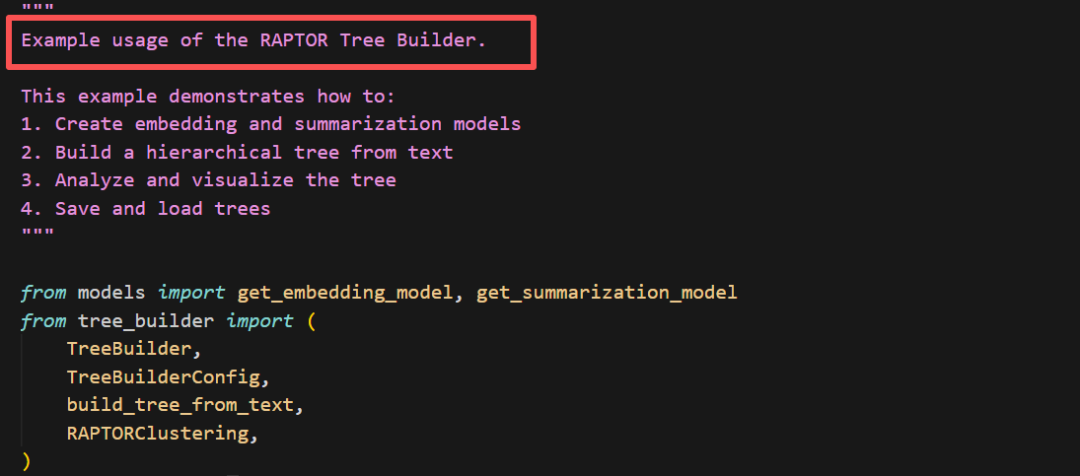 整个过程,它就像一个经验丰富的系统架构师,不仅完成了重构,还提交了一份清晰的“重构说明文档”。 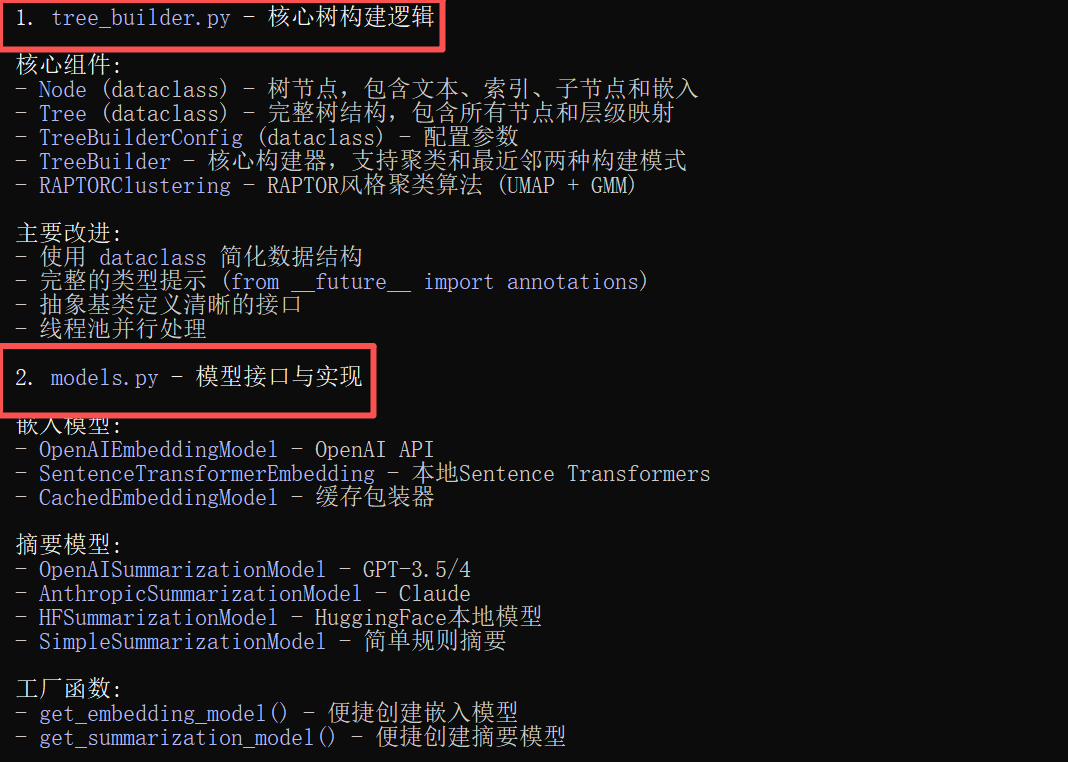 这已经远超简单的代码补全,上升到理解设计意图并进行优化的层面。 GLM4.7,这可能是你今年最值得尝试的编程外脑经过这一轮高强度、全场景的实测,GLM-4.7给我的体感极度丝滑。它不再是那个只会接单段指令的“助手”,而是一个能理解复杂意图、主动拆解任务、统筹技术方案、并交付高质量代码的“协作者”。 无论是数据科学、全栈开发、还是代码重构,它都能提供真正专业级的助力,将开发者从重复劳动和琐碎细节中解放出来,专注于真正的创意和架构设计。 而对于需要高频、深度使用的小伙伴,“GLM Coding Plan”是不错的性价比之选,已经全面升级支持GLM-4.7。 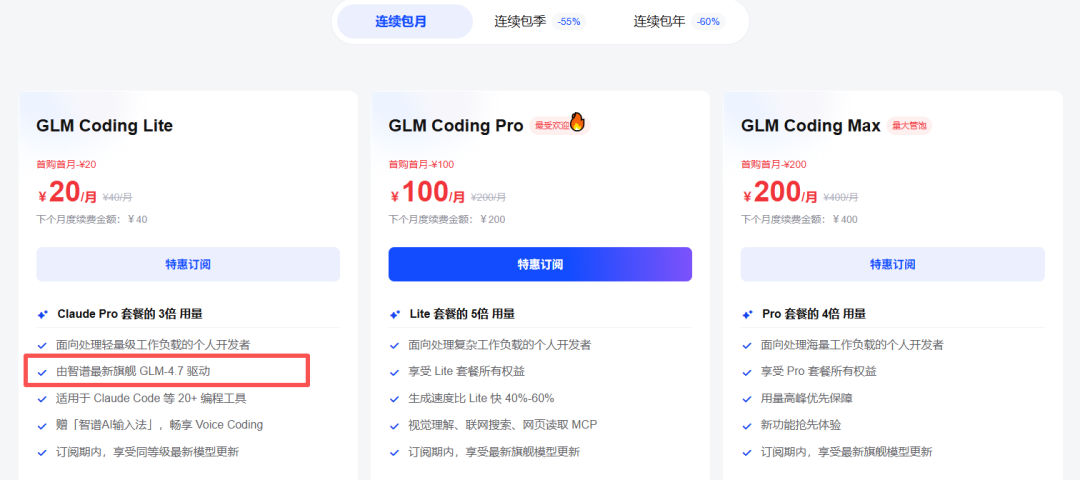 Hugging Face:huggingface.co/zai-org/GLM-4.7
Blog:https://z.ai/blog/glm-4.7
在线体验GLM-4.7全栈开发:https://z.ai/
| 









