最近Claude Skills着实火了,技能(skill):一种受模式约束的操作,具有语义描述符、明确定义的输入-输出签名,并指定如何执行该操作的执行策略
2026,做Agentic AI,绕不开这两篇开年综述
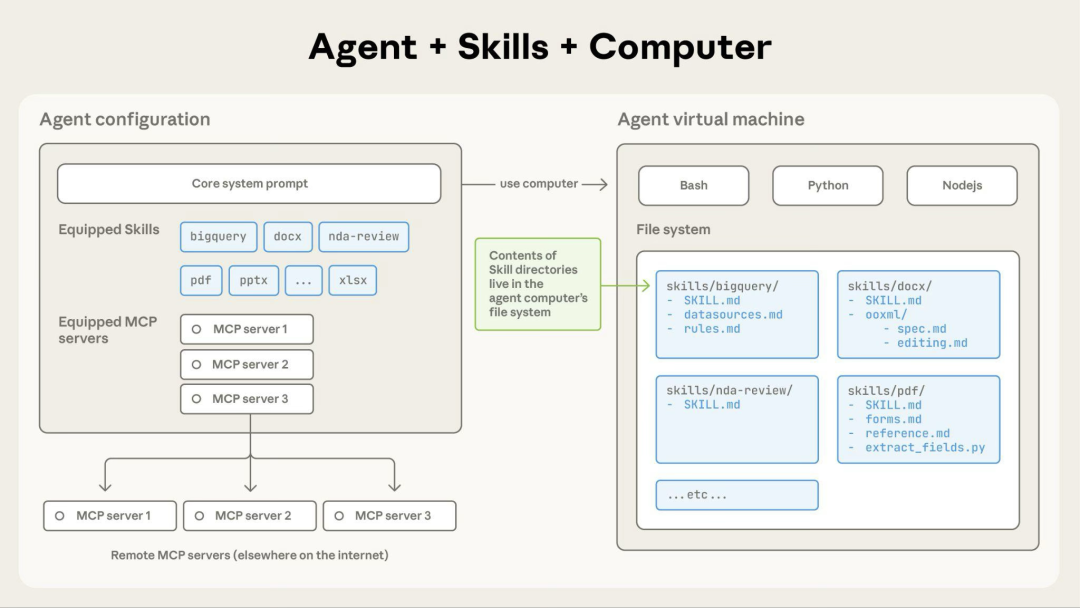
今天分享两篇关于Claude Skills的最新研究论文,PaperAgent从种总结出了三条有价值的结论:

- 26.1%的技能存在安全漏洞,数据泄露最普遍(42,447个技能被收集,31,132个技能接受扫描)
- 当Single-Agent技能数超过50-100个,准确率从95%暴跌至20%,这不是渐进的性能下降,而是系统性的相变
- 即使只有20个技能,如果语义高度相似(如"Calculate Sum"、"Compute Total"、"Sum Numbers"),准确率也会从100%降至37-70%
Single-Agent技能系统何时能取代Multi-Agent

近年来,多智能体系统(MAS)成为解决复杂推理任务的利器。无论是AutoGen的灵活对话框架,还是MetaGPT的标准化协作流程,都证明了专业分工的价值。但代价是什么?
- 重复上下文交换:每个agent都要重新理解任务背景
研究者提出一个诱人设想:能否把多智能体的协作模式"编译"成单个LLM内部的技能库(Skill Library)?就像把几个专家的对话,变成一个人切换不同工具干活。

核心思想:从"多人协作"到"一人多能"
论文提出了单智能体技能系统(SAS)框架。每个技能是一个三元组:

关键洞察:多智能体间的通信图可以转化为技能间的隐式约束。比如,agent A的输出必须能被agent B消费,这在SAS中就变成了技能A的输出格式要求。
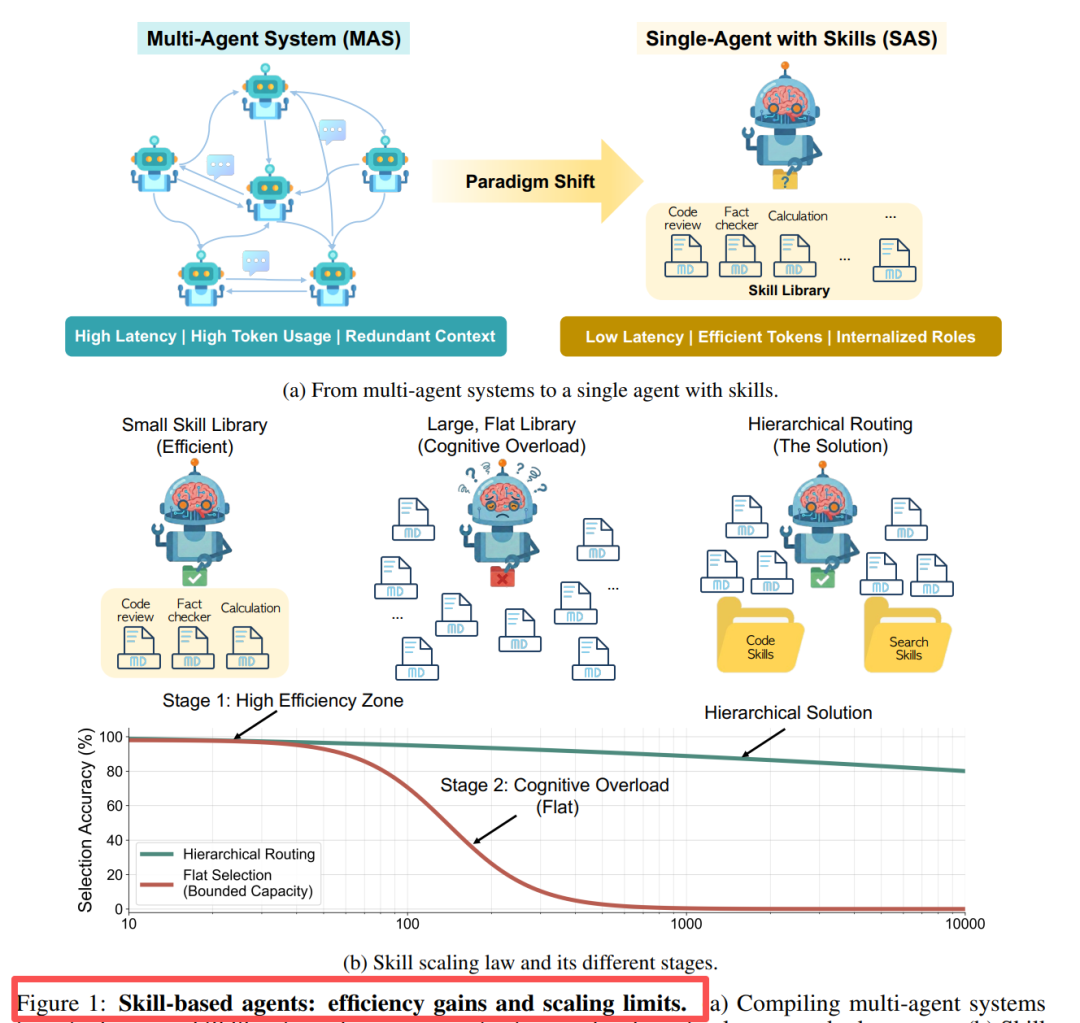
图1显示:左侧是多智能体的高通信成本,右侧是单智能体的技能选择成本。当技能库规模扩大时,会出现类似人类认知超载的非线性退化。
实验验证:编译后的效率飞跃
研究团队选取了三种可编译的多智能体架构进行测试:
结果令人振奋:
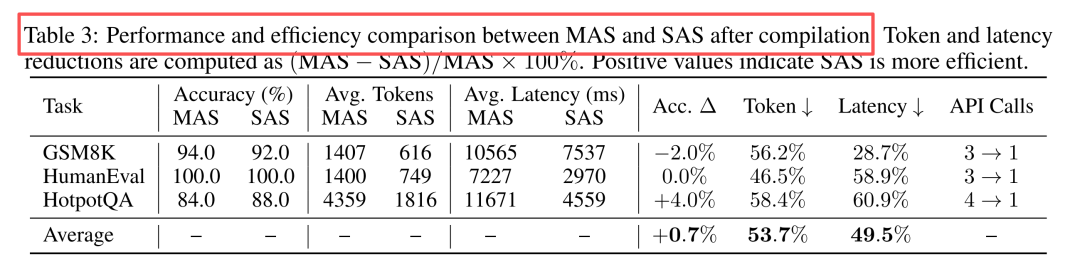
关键数据:
- 准确率:几乎无损(平均提升+0.7%),HotpotQA甚至提升4%
- Token消耗:平均减少**53.7%**,最高58.4%
惊人发现:技能选择的"认知容量限制"
当研究者试图扩大技能库规模时,发现了非线性相变现象。
实验H1:非线性相变
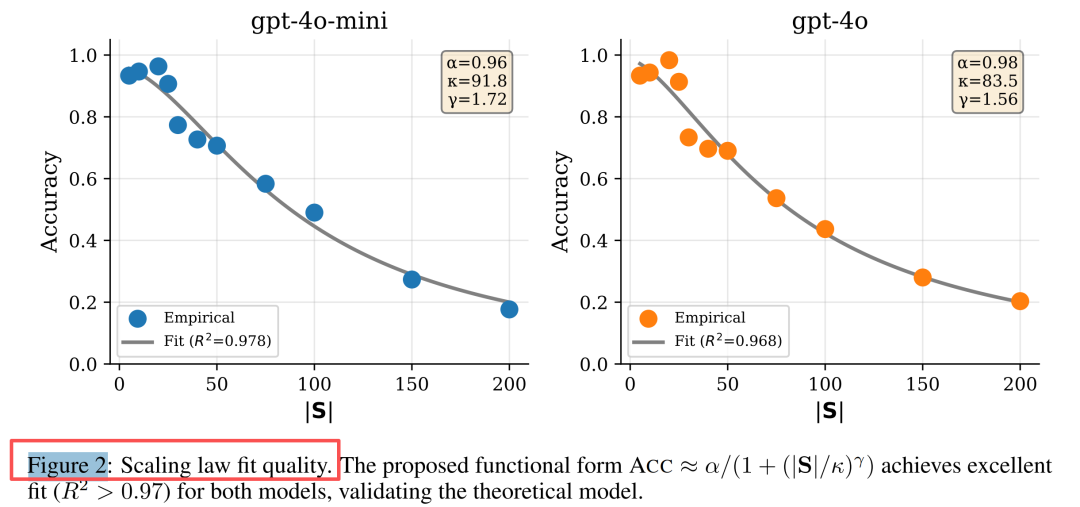
实验设计:在GPT-4o-mini和GPT-4o上测试技能库大小从5到200的选择准确率。
结果触目惊心:
这完全不是线性退化!研究者用认知科学中的希克定律和工作记忆容量限制来解释:就像人脑无法同时处理超过7±2个选项,LLM的选择能力也存在一个临界阈值κ(约50-100个技能)。
实验H2:语义混淆才是罪魁祸首
是数量的问题,还是"相似度"的问题?
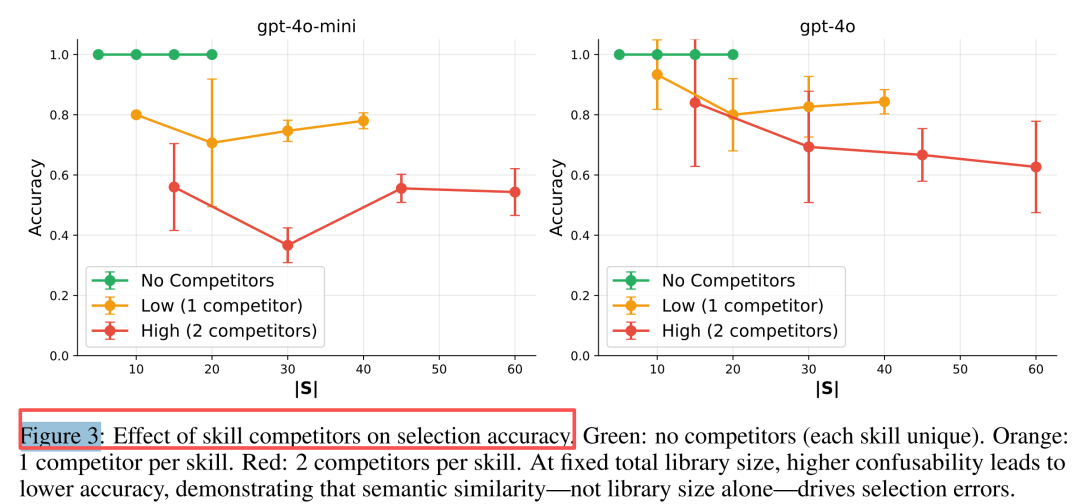
这印证了ACT-R模型的扇形效应:共享检索线索的记忆项会相互抑制激活。
解决方案:层次化路由的"分而治之"
既然扁平选择会过载,那就像人类菜单设计一样分层?
实验H4:层次化路由的救赎
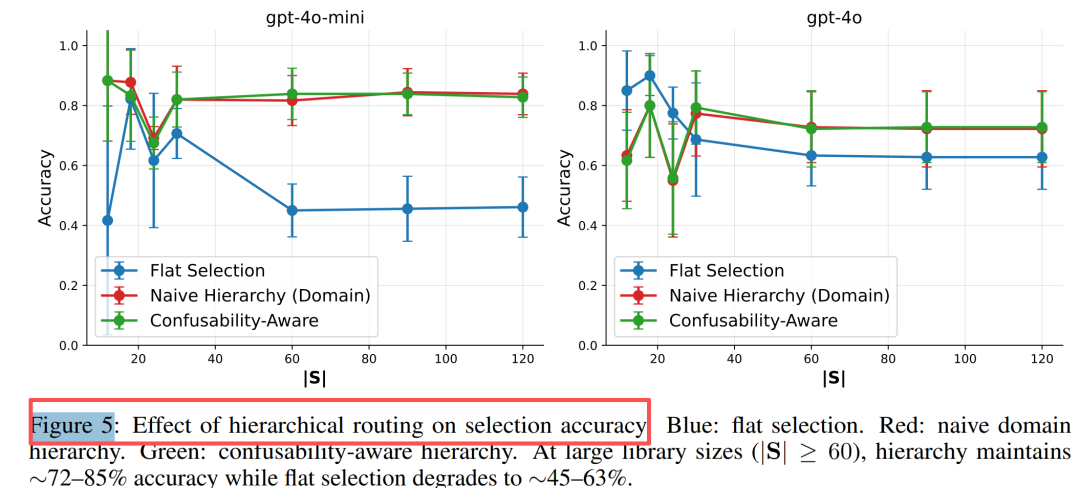
三种策略对比:
- 朴素域层次:先选大类(如数学、写作),再选具体技能
- 混淆感知层次:将易混淆技能分在同一子组,先选组再细分
结果:
- 当|S|>60(超过阈值),层次化提升**37-40%**准确率(GPT-4o-mini)
认知科学框架:AI也有"选择困难症"
论文提出了一个结合认知理论的技能扩展法则:
其中:
四大认知基础:
- 希克定律:选项增加导致决策时间对数增长,但超过8个选项后策略崩溃
- 认知负荷理论:内在负荷超过工作记忆时,性能断崖式下跌
- 相似性干扰:Shepard的泛化定律,混淆概率随心理距离指数衰减
https://arxiv.org/pdf/2601.04748
When Single-Agent with Skills Replace Multi-Agent Systemsand When They Fail
Agent Skills安全分析

随着AutoGPT、LangChain等Agent框架的流行,“技能(Skill)”成了新的乐高积木:一段自然语言指令+可执行代码,就能让Agent瞬间学会“订机票”“发邮件”“爬网页”。
但问题来了——
这些技能谁来安检?
如果技能里藏着“偷数据”“提权”“投毒”呢?
研究设计:SkillScan照出漏洞
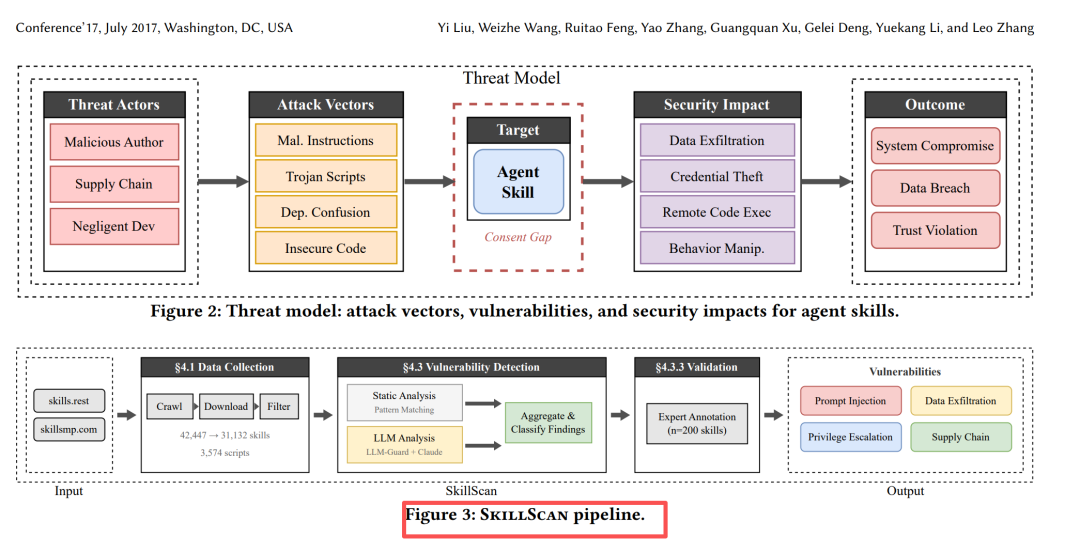
| | |
|---|
| 采集 | | |
| 去重/过滤 | | |
| 检测引擎 | SkillScan三阶段流水线:
① 静态分析(AST、正则、依赖图)
② LLM语义分类(GPT-4o微调)
③ 人工验证+打标签 | |
| 评估 | precision 86.7%,recall 82.5%,F1 84.6% | |
漏洞全景:14种套路,4大阵营










