|
为什么传统 RAG 会“断链”- 单跳场景:把文档切成 200 字左右的 chunk,做向量相似度检索 → LLM 直接答,够用。
- 多跳场景:需要把 2-4 份文档里的证据拼成一条“推理链”。chunk 粒度粗,一次就带回一整段,里面 60% 是干扰句,关键句反而被淹没 → 链条断了,LLM 开始“胡编”。
作者一句话总结:“不是检索不准,是检索单元太胖,逻辑关系太乱。” 传统 chunk 图 SentGraph 句图
[整段1]——相似——[整段2] [S1]—因果→[S2]—对比→[S3]
↓ 含 6 句废话 ↓ 句句相关
上下文爆炸 推理链清爽
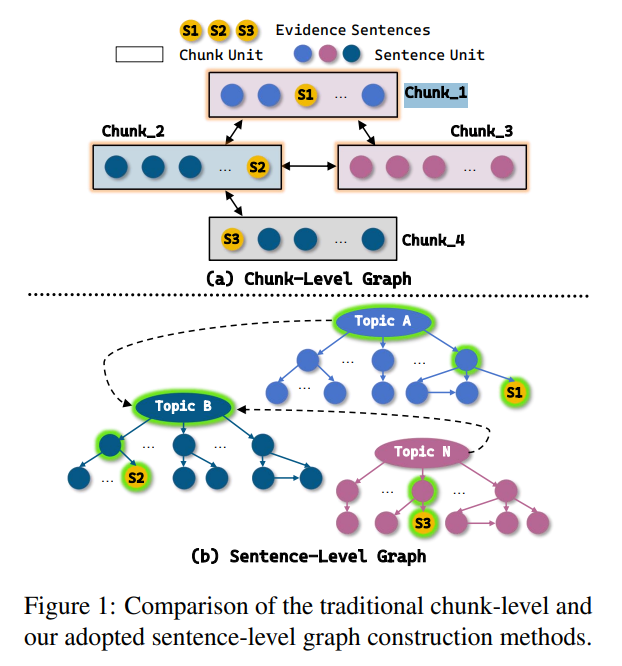
SentGraph 的“瘦身”思路把检索单元从“段”缩到“句”,再把这些句子按真正的逻辑关系画成一张三层图,线下建好,线上直接按图索骥。 图长啥样? Topic 层——跨文档“桥梁”
↑
Core 句层——核心事实
↑
Sup 句层——背景、因果、举例
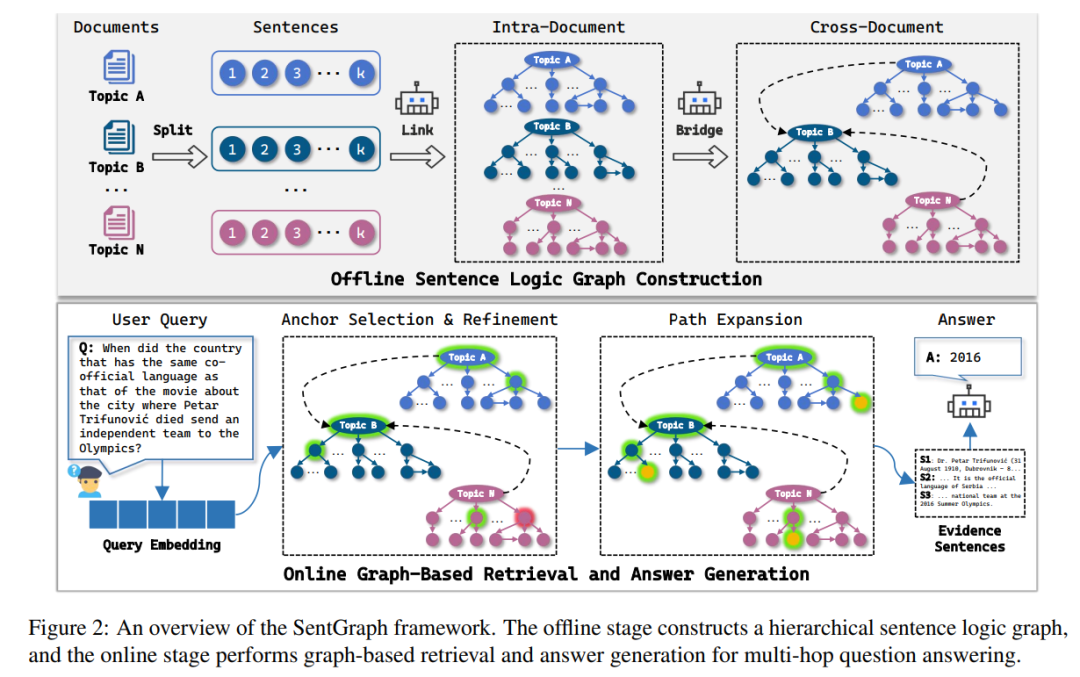
线下建图三步曲例:
文档 A「克罗地亚官方语言为克罗地亚语。」
文档 B「电影《围城》使用克罗地亚语拍摄。」
系统线下就在 Topic 层建一条边:(克罗地亚语, 被用于, 电影《围城》)
线上推理三步曲Anchor 初选
用 dense retriever 把“问题向量”和所有句子向量比对,先取 Top-K 候选句。
SentGraph: Hierarchical Sentence GraphforMulti-hop Retrieval-Augmented Question Answering
https://arxiv.org/pdf/2601.03014
| 









