刚刚,DeepSeek在更新FlashMLA的flash_mla_interface.py时,提到了一款新模型MODEL1,总共有4处修改。
Agentic AI,绕不开这两篇开年综述" data-itemshowtype="0" linktype="text" data-linktype="2">2026,做Agentic AI,绕不开这两篇开年综述
 Twitter压箱底的算法被马斯克开源了
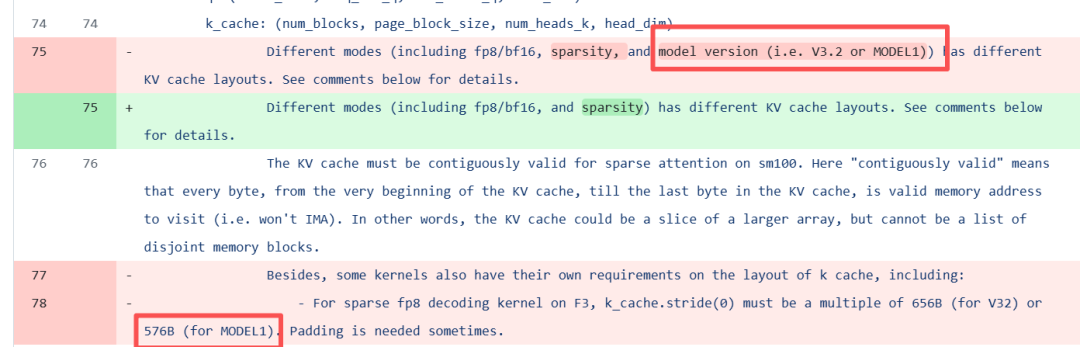
Twitter压箱底的算法被马斯克开源了从这段 diff 可以看出,MODEL1在 MLA(Multi-head Latent Attention)KV-Cache 的存储与访问方式),与V3/V3.2系列有 3 个本质差异:
- 物理排布更“紧凑”
V3 系列 FP8 块是 128 B 数据 + 16 B scale + 128 B RoPE 三段式;MODEL1 把 NoPE 与 RoPE 交错放在一起,紧接着就放 scale,整块只有 576 B(V32 是 656 B)。
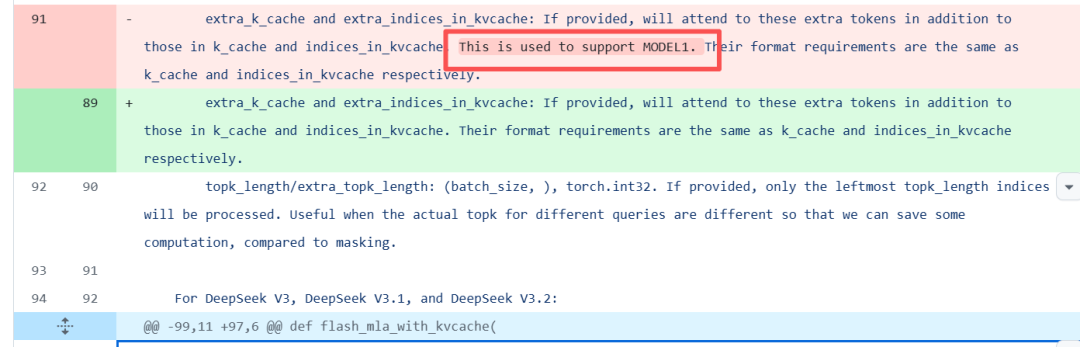
- 引入了“extra” 两段式 cache
函数签名里把原来写死的 “MODEL1 专用” 字样删掉,但 extra_k_cache / extra_indices_in_kvcache 参数仍然保留。
- 头维固定 512×512,彻底取消 128/192 等可变维度

注释把 “head_dim should be 512 while head_dim_v is also 512” 整段删掉,是因为代码里已经硬编码检查,不再支持其它尺寸。
https://github.com/deepseek-ai/FlashMLA/commit/48c6dc426f045cb7743b18f5c7329f35f1b7ed79










