论文摘要ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-indent: 0em;text-wrap: wrap;background-color: rgb(255, 255, 255);line-height: 1.5em;visibility: visible;">这篇论文介绍了一种名为LATS(Language Agent Tree Search)的框架,它将语言模型在规划、行动和推理方面的优势结合起来,以增强决策能力。LATS借鉴了基于模型强化学习中常用的蒙特卡罗树搜索方法,并利用环境提供外部反馈,从而实现更明智和适应性更强的问题解决机制。实验结果表明,在编程、HotPotQA和WebShop等不同领域中,LATS能够有效地进行决策并保持竞争性的推理性能。例如,在HumanEval上使用GPT-4时,LATS取得了94.4%的编程成绩;在WebShop上使用GPT-3.5时,平均得分为75.9。这证明了该方法的有效性和通用性。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;text-align: justify;">主要内容ingFang SC";letter-spacing: normal;color: rgb(63, 63, 63);-webkit-font-smoothing: antialiased;text-align: start;text-wrap: wrap;">方法描述ingFang SC";font-size: 14px;color: rgb(102, 102, 102);letter-spacing: normal;text-align: start;text-wrap: wrap;">本文提出的LATS是一种基于蒙特卡罗树搜索(MCTS)的推理决策框架,旨在支持自然语言任务中的推理和决策。该框架通过将一个思考序列作为节点,使用预训练的语言模型来评估每个节点的价值,并根据环境反馈更新价值函数。同时,它还具有自我反思功能,可以从失败的轨迹中学习并提高其决策能力。ingFang SC";font-size: 14px;color: rgb(102, 102, 102);letter-spacing: normal;text-align: start;text-wrap: wrap;"> ingFang SC";font-size: 14px;letter-spacing: 0.578px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);"/>ingFang SC";font-size: 14px;color: rgb(102, 102, 102);letter-spacing: normal;text-align: start;text-wrap: wrap;">表1:关于推理、行动和规划的相关工作的总结。LATS 是第一个结合了这三个领域的设计的工作,使其能够应用于所有相应的任务。我们把搜索算法的使用称为规划,将语言模型生成的反馈用于自我反思,将过去文本语境的存储视为外部记忆,以供将来对解决方案进行更新。ingFang SC";font-size: 14px;color: rgb(102, 102, 102);letter-spacing: normal;text-align: start;text-wrap: wrap;">从上表中可以看出LATS充分融合了计划、思考、行动、反思与记忆,效果也会更好。ingFang SC";font-size: 14px;color: rgb(102, 102, 102);letter-spacing: normal;text-align: start;text-wrap: wrap;">方法改进 ingFang SC";font-size: 14px;letter-spacing: 0.578px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);"/>ingFang SC";font-size: 14px;color: rgb(102, 102, 102);letter-spacing: normal;text-align: start;text-wrap: wrap;">表1:关于推理、行动和规划的相关工作的总结。LATS 是第一个结合了这三个领域的设计的工作,使其能够应用于所有相应的任务。我们把搜索算法的使用称为规划,将语言模型生成的反馈用于自我反思,将过去文本语境的存储视为外部记忆,以供将来对解决方案进行更新。ingFang SC";font-size: 14px;color: rgb(102, 102, 102);letter-spacing: normal;text-align: start;text-wrap: wrap;">从上表中可以看出LATS充分融合了计划、思考、行动、反思与记忆,效果也会更好。ingFang SC";font-size: 14px;color: rgb(102, 102, 102);letter-spacing: normal;text-align: start;text-wrap: wrap;">方法改进
ingFang SC";font-size: 14px;color: rgb(102, 102, 102);letter-spacing: normal;text-align: start;text-wrap: wrap;">与传统的基于MCTS的推理决策框架相比,LATS的主要改进在于:使用了蒙特卡罗树搜索算法,可以有效地探索可能的解决方案。 利用了预训练的语言模型来评估节点的价值,从而更好地指导搜索过程。 引入了自我反思机制,可以从失败的轨迹中学习并提高决策能力。
解决的问题本文主要解决了自然语言任务中的推理和决策问题。具体来说,它可以用于以下场景: - 推理问题:当输入一个问题时,可以通过LATS生成一系列中间想法(思考序列),最终得到答案。
- 决策问题:当需要在多个选项之间做出选择时,LATS可以根据不同的情况生成不同的决策路径,并从中选择最优解。
总之,LATS提供了一种灵活、高效且可扩展的方式来处理自然语言任务中的推理和决策问题。实现解析我们先拆解下LATS主要内容,包含了节点选择、拓展、评分、执行、反向传播、反思。选择节点后进行拓展子节点,每个子节点通过LLM评分。任务不断执行直到达到设定的指定步数或获取最优质的结果,再将结果反向传播给各父节点进行更新。而输出内容经过LLM进行反思更新结果。
主要有四个主要步骤: - 选择:根据下面步骤 (2) 中的总奖励选择最佳的下一步行动。要么做出响应(如果找到解决方案或达到最大搜索深度),要么继续搜索。
- 扩展和执行:生成 N(在我们的例子中为 5)个潜在操作以并行执行并执行它们。
- 反思+评估:观察这些行动的结果并根据反思(以及可能的外部反馈)对决策进行评分。
总结一下,选择当前节点,行动、反思、评分,并将结果反向传播给父节点,同时根据节点数量是否达到上限以及结果情况决定是否继续向下延伸或输出结果。
总结思考LATS通过融合计划、思考、行动、反思与记忆,使用蒙特卡罗树搜索算法,相较ReAct、ToT、CoT、Reflection等框架具有显著优势,下图为LATS与其他框架的对比。 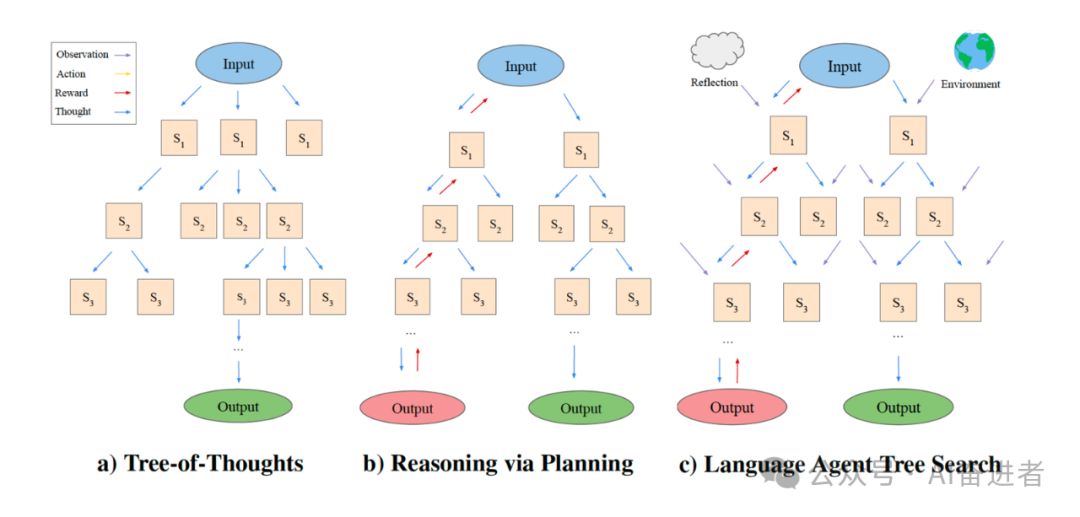
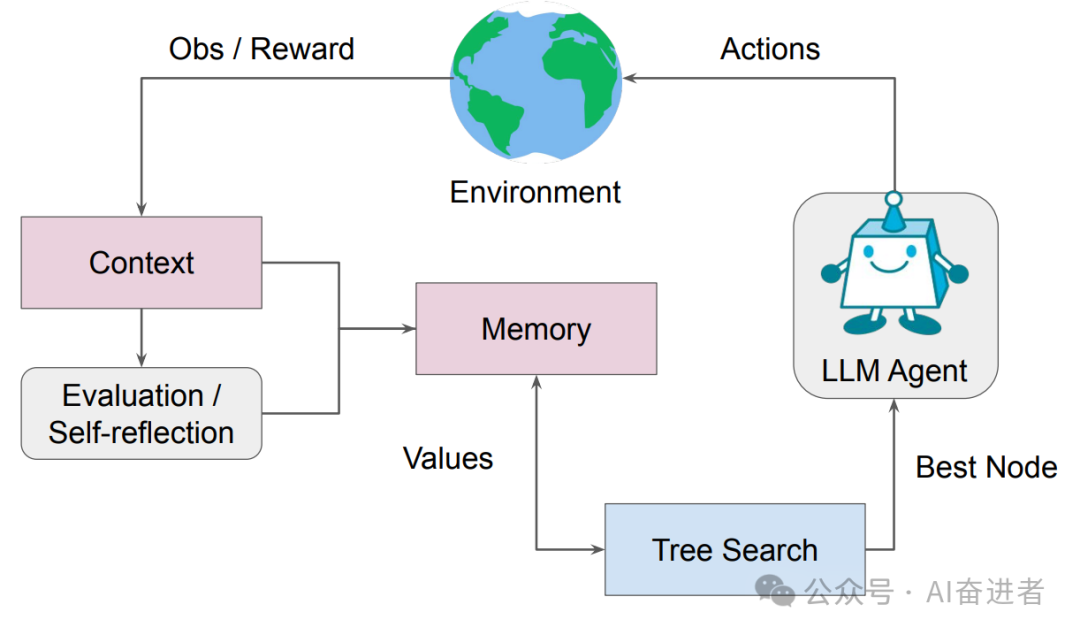
核心亮点之一在于引入了内部反思与外部条件反馈,将内外反馈条件作为记忆存储与利用,以获得更好的效果。 | 









