ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin-right: auto;margin-bottom: 1em;margin-left: auto;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">使用Qwen-Agent将上下文记忆扩展到百万量级ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">Qwen 团队开发了一个智能体用于理解包含百万字词的文档,虽然仅使用Qwen2模型的8k上下文,但效果超过RAG和长序列原生模型。我们还利用此智能体合成长上下文数据,用于训练长上下文的Qwen模型。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.1em;font-weight: bold;margin-top: 2em;margin-right: 8px;margin-bottom: 0.75em;padding-left: 8px;border-left: 3px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">引言ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">近期,能够原生处理数百万字输入的大型语言模型(LLMs)成为了一种趋势。大部分工作集中在模型架构调整,如位置编码扩展或线性注意力机制等。然而,准备足够长度的微调数据作为讨论较少但同样重要的议题,却鲜少被提及。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">Qwen团队采取以下方法准备数据:
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;padding-left: 1em;color: rgb(63, 63, 63);" class="list-paddingleft-1">1.利用一个较弱的8k上下文聊天模型构建一个相对强大的智能体,能够处理1M的上下文。 2. 随后,使用该智能体合成微调数据,并应用自动化过滤确保数据质量。 3.最终,使用合成数据对预训练模型进行微调,得到一个强大的1M上下文聊天模型。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">目前的研究主要聚焦于第一步,后续步骤的详情将在未来几周或几个月内揭晓。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.1em;font-weight: bold;margin-top: 2em;margin-right: 8px;margin-bottom: 0.75em;padding-left: 8px;border-left: 3px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">构建智能体ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">智能体包含三个复杂度级别,每一层都建立在前一层的基础上。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-weight: bold;margin: 2em 8px 0.5em;color: rgb(15, 76, 129);">级别一:检索处理100万字上下文的一种朴素方法是简单采用增强检索生成(RAG)。RAG将上下文分割成较短的块,每块不超过512个字,然后仅保留最相关的块在8k字的上下文中。挑战在于如何精准定位最相关的块。经过多次尝试,我们提出了一种基于关键词的解决方案: 步骤1:指导聊天模型将用户查询中的指令信息与非指令信息分开。例如,将用户查询"回答时请用2000字详尽阐述,我的问题是,自行车是什么时候发明的?请用英文回复。"转化为{"信息": ["自行车是什么时候发明的"], "指令": ["回答时用2000字", "尽量详尽", "用英文回复"]}。 步骤2:要求聊天模型从查询的信息部分推导出多语言关键词。例如,短语"自行车是什么时候发明的"会转换为{"关键词_英文": ["bicycles", "invented", "when"], "关键词_中文": ["自行车", "发明", "时间"]}。 步骤3:运用BM25这一传统的基于关键词的检索方法,找出与提取关键词最相关的块。 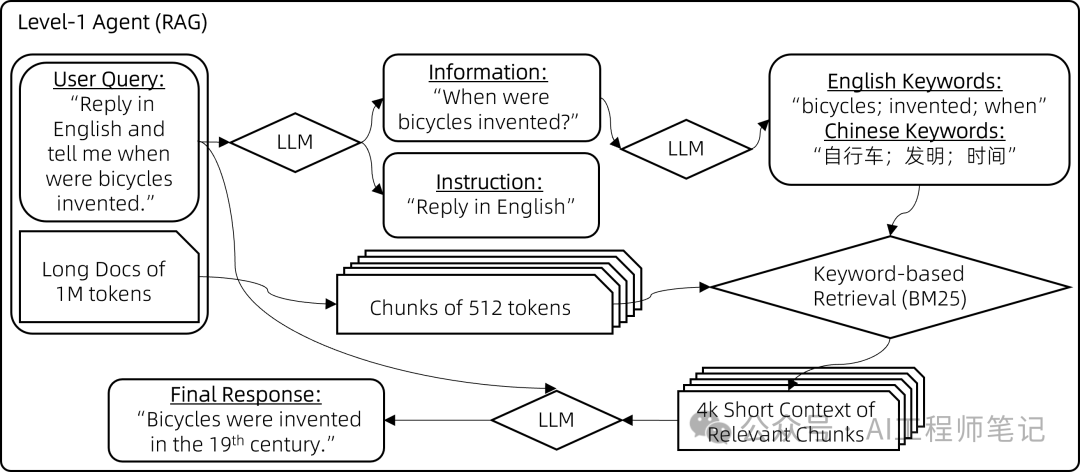
Qwen团队也尝试了基于向量的检索,但在大多数情况下,它带来的改进并不显著,不足以抵消部署单独向量模型所带来的额外复杂性。 实现代码: https://github.com/QwenLM/Qwen-Agent/blob/main/examples/assistant_rag.py 级别二:分块阅读上述RAG方法很快速,但常在相关块与用户查询关键词重叠程度不足时失效,导致这些相关的块未被检索到、没有提供给模型。尽管理论上向量检索可以缓解这一问题,但实际上效果有限。为了解决这个局限,我们采用了一种暴力策略来减少错过相关上下文的几率: 步骤1:对于每个512字块,让聊天模型评估其与用户查询的相关性,如果认为不相关则输出"无", 如果相关则输出相关句子。这些块会被并行处理以避免长时间等待。 步骤2:然后,取那些非"无"的输出(即相关句子),用它们作为搜索查询词,通过BM25检索出最相关的块(总的检索结果长度控制在8k上下文限制内)。 步骤3:最后,基于检索到的上下文生成最终答案,这一步骤的实现方式与通常的RAG相同。 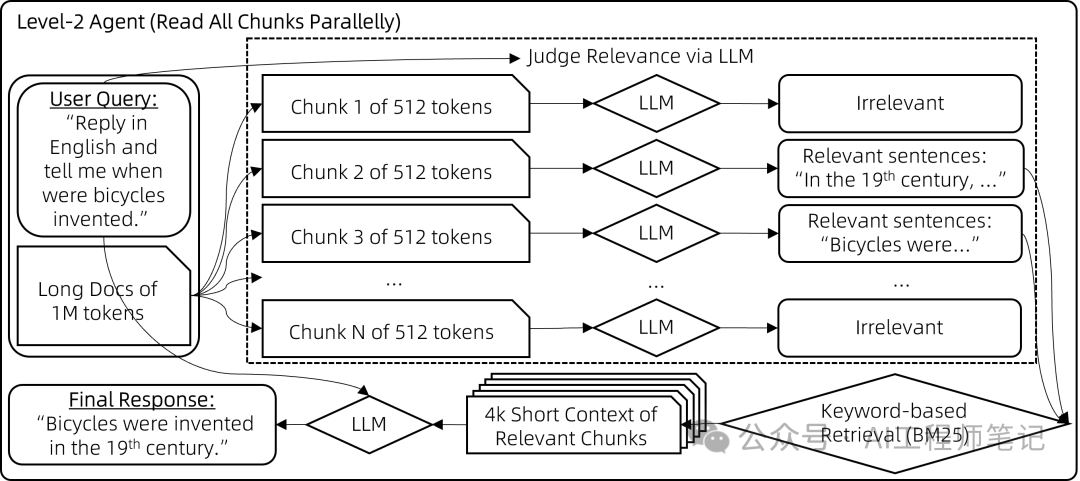
实现代码: https://github.com/QwenLM/Qwen-Agent/blob/main/examples/parallel_doc_qa.py 级别三:逐步推理在基于文档的问题回答中,一个典型的挑战是多跳推理。例如,考虑回答问题:“与第五交响曲创作于同一世纪的交通工具是什么?”模型首先需要确定子问题的答案,“第五交响曲是在哪个世纪创作的?”即19世纪。然后,它才可以意识到包含“自行车于19世纪发明”的信息块实际上与原始问题相关的。 工具调用(也称为函数调用)智能体或ReAct智能体是经典的解决方案,它们内置了问题分解和逐步推理的能力。因此,我们将前述级别二的智能体(Lv2-智能体)封装为一个工具,由工具调用智能体(Lv3-智能体)调用。工具调用智能体进行多跳推理的流程如下: 向Lv3-智能体提出一个问题。
while(Lv3-智能体无法根据其记忆回答问题){
Lv3-智能体提出一个新的子问题待解答。
Lv3-智能体向Lv2-智能体提问这个子问题。
将Lv2-智能体的回应添加到Lv3-智能体的记忆中。
}
Lv3-智能体提供原始问题的最终答案。
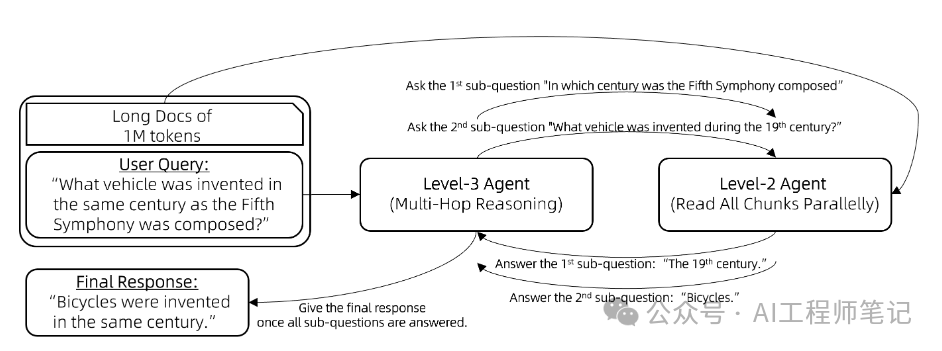
例如,Lv3-智能体最初向Lv2-智能体提出子问题:“贝多芬的第五交响曲是在哪个世纪创作的?”收到“19世纪”的回复后,Lv3-智能体提出新的子问题:“19世纪期间发明了什么交通工具?”通过整合Lv2-智能体的所有反馈,Lv3-智能体便能够回答原始问题:“与第五交响曲创作于同一世纪的交通工具是什么?” 实验效果在两个针对256k上下文设计的基准测试上进行了实验: NeedleBench,一个测试模型是否能在充满大量无关句子的语境中找到最相关句子的基准,类似于“大海捞针”。回答一个问题可能需要同时找到多根“针”,并进行多跳逐步推理。 LV-Eval是一个要求同时理解众多证据片段的基准测试。我们对LV-Eval原始版本中的评估指标进行了调整,因为其匹配规则过于严苛,导致了许多假阴性结果。 我们比较了以下方法: 32k-模型:这是一个7B对话模型,主要在8k上下文样本上进行微调,并辅以少量32k上下文样本。为了扩展到256k上下文,我们采用了无需额外训练的方法,如基于RoPE的外推。 4k-RAG:使用与32k-模型相同的模型,但采取了Lv1-智能体的RAG策略。它仅检索并处理最相关的4k上下文。 4k-智能体:同样使用32k-模型的模型,但采用前文描述的更复杂的智能体策略。该智能体策略会并行处理多个片段,但每次请求模型时至多只使用模型的4k上下文。 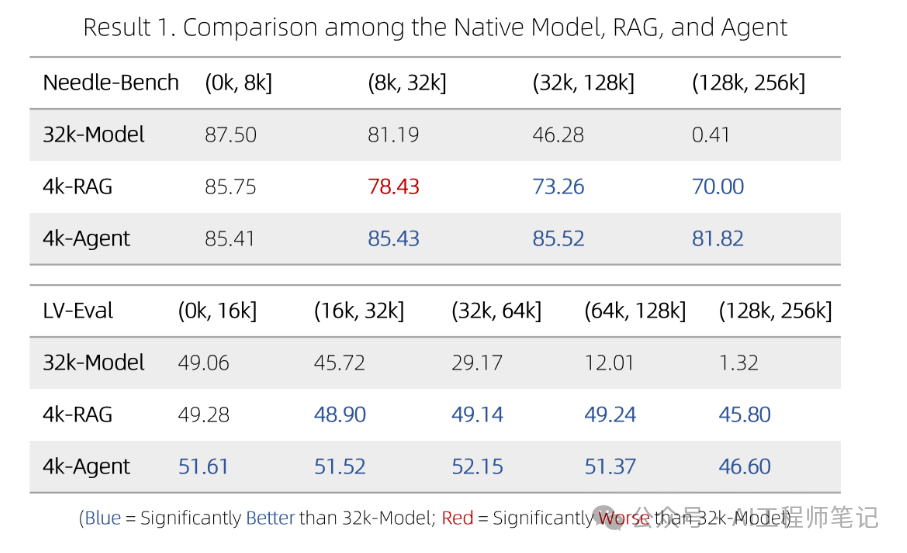
实验结果说明了以下几点: •在短上下文场景中,4k-RAG的表现可能不如32k-模型。这可能是由于RAG方案难以检索到正确的信息或理解多个片段造成的。 •相反,随着文档长度的增加,4k-RAG越发表现出超越32k-模型的趋势。这一趋势表明32k-模型在处理长上下文方面并没有训练到最优的状态。 •值得注意的是,4k-智能体始终表现优于32k-模型和4k-RAG。它分块阅读所有上下文的方式使它能够避免原生模型在长上下文上训练不足而带来的限制。
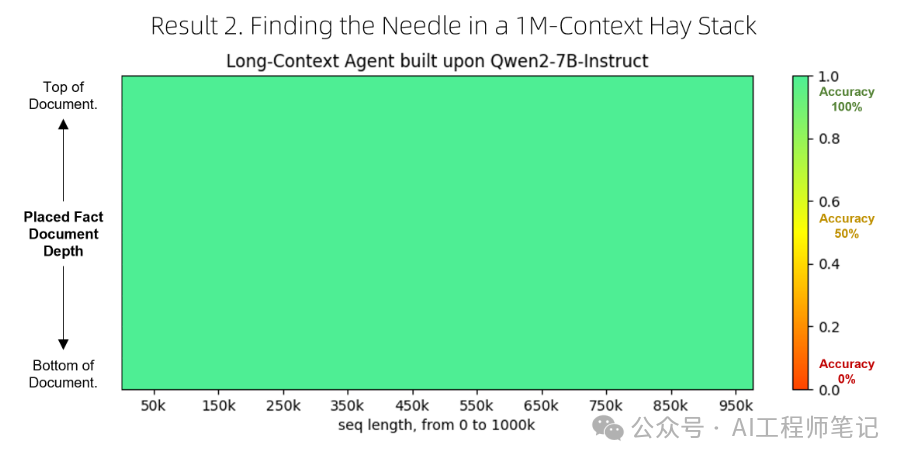
总的来说,如果得到恰当的训练,32k-模型理应优于所有其他方案。然而,实际上由于训练不足,32k-模型的表现不及4k-智能体。 最后,我们还对该智能体进行了100万个字词的压力测试(在100万个字词的大海中寻找一根针),并发现它能够正常运行。然而,我们仍然缺乏一个更贴近真实使用场景的可靠基准来系统量化它在100万字词任务上的表现。 Qwen-Agent项目地址:https://github.com/QwenLM/Qwen-Agent 注意: 以上内容摘录自Qwen官方博客https://qwenlm.github.io/zh/blog/qwen-agent-2405/。 @misc{qwen-agent-2405,
title={GeneralizinganLLMfrom8kto1MContextusingQwen-Agent},
url={https://qwenlm.github.io/blog/qwen-agent-2405/},
author={QwenTeam},
month={May},
year={2024}
}
|










