|
介绍 在快速发展的生成式人工智能领域,某些流行术语已变得司空见惯:“提示工程”、“函数调用”、“RAG”和“微调”,你应该也经常遇到这些术语,但你是否能够理清这些概念之间的关系?这些其实都是一些大模型的应用策略和技术,本文将描述每个 LLM 策略的作用以及它们之间的关系,并简单介绍如何在它们之间选择最佳的用例。 回顾 LLM 的运作方式 在进一步讨论之前,让我们简单回顾一下 LLM 如何产生输出结果。 通俗地说,这就像完成完形填空一样: 
LLM 如何产生结果 更深入地,为了进行这些“完形填空”,LLM经历了一个训练过程,即阅读所有人类知识并记录将每个 token 视为下一个 token 的可能性。(注意:1 个 token 代表一个或多个单词) LLM 生成“完形填空”测试结果的过程就是“推理”过程。 训练和推理是使LLM能够按预期发挥作用的两个核心过程。 这也解释了为什么有时 LLM 会自信地说错话——它所训练的人类知识可能没有包含我们希望它谈论的主题的足够信息。 因此,为了使 LLM 能够正常运作,我们需要向 LLM 提供更多有关主题的背景有用信息。 所有策略,包括函数调用、RAG 和微调都是围绕这一点展开的。它们是为 LLM 提供更多上下文有用信息的不同方法。 这些策略有哪些?它们之间有何关系? 纯粹的提示 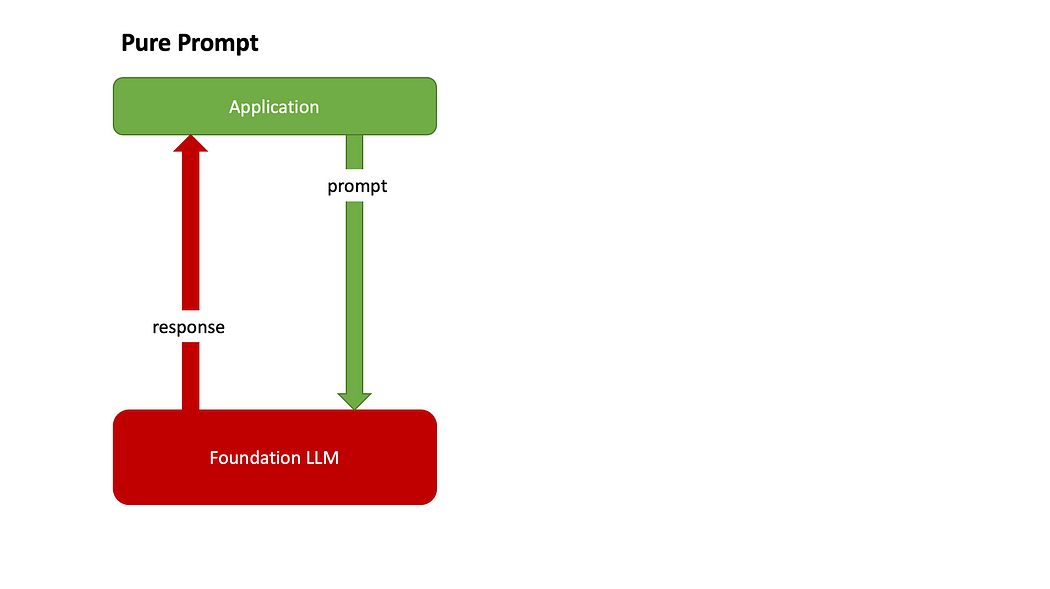
第一个策略是纯粹的提示。从名称上就可以看出这个策略是如何运作的: 这其实就是“聊天”。你和 LLM 聊天就像和另一个人聊天一样。 当我们与 LLM 驱动的聊天机器人(例如 ChatGPT、Gemini 和 Copilot)聊天时,我们每天都会使用此策略。 2.代理+函数调用 
第二种策略是 Agent 加函数调用。 此策略的工作原理如下: 这里的工具包是预先编写的函数或 API 调用的列表 LLM 将决定它想要使用的工具,并返回该工具的名称(即函数名称) 如果这听起来仍然很抽象,让我们举一个例子: 你以旅行社的身份向 LLM 发出查询,例如“为我规划一次即将到来的圣诞节假期巴厘岛之旅” LLM 认为,为了给你安排一个好的旅行,它首先需要你的预算信息。它参考了包含 get_budget()、get_destination_info()、get_weather() 等多个工具的给定工具包,并决定使用名为 get_budget() 的工具。 收到建议的工具名称后,您(作为应用程序)调用该函数get_budget()。假设它返回给您1000 元的预算。 你把1000元的预算信息传递给LLM,LLM会根据你的预算为你生成一份旅行计划清单
注意:函数调用绝对不仅限于单个函数。在此示例中,LLM 可能决定它还需要天气信息和目的地信息,因此它可能会选择其他工具。将调用哪些函数get_destination_info()以及get_weather()调用多少个函数取决于不同的因素,其中包括: 工具包中提供了哪些功能 上下文包括系统提示、用户提示和历史用户信息 等等
您可能已经注意到,这个过程涉及LLM(提供任何可能的答案)以及函数/API 调用(带有预设逻辑)。 与使用硬编码逻辑(例如 if else)来决定何时调用哪个函数/API 的传统方法不同,此过程利用 LLM 的强大功能根据上下文动态地决定何时调用哪个函数/API。 而且不同于单纯的提示,这个过程使得LLM能够通过函数/API调用与外部系统集成。 3. RAG(检索增强生成) 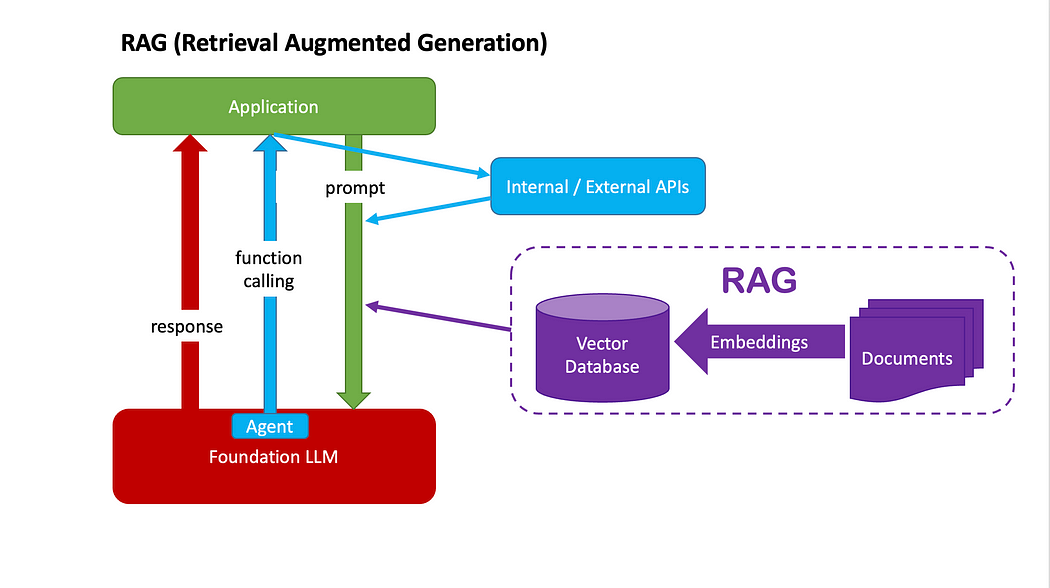
第三个策略是RAG。 除了上面 Agent + Function Calling 中提到的函数/API工具包之外,我们还可以为LLM提供一个知识库,知识库一般通过向量数据库来实现。 构建知识库: 这个策略的工作原理如下: 检索到的信息将成为传递给 LLM 的最终提示的一部分。这是“增强”的过程(增强提示) LLM 根据最终提示生成答案。这是“生成”的过程 4. 微调 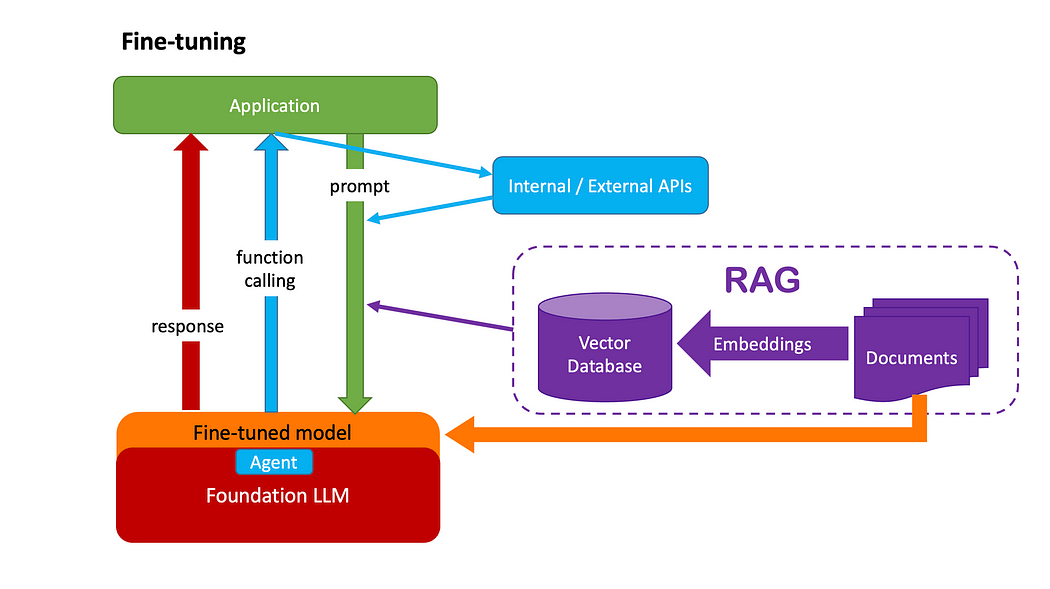
第四个策略是微调。 就像编写函数一样,有两种方法可以将变量传递给它: 一是,从参数中传入变量,以便可以在运行时获取它; 二是,将其作为函数内的局部变量。
类似地,我们在上面的 RAG 策略中作为运行时提示传入的上下文知识,也可以在模型训练期间将其嵌入其中。这就是微调的情况。 想象一下,一家专门从事制药业的公司可能拥有庞大的知识库,但公众对此并不知情。在这种情况下,该公司可以选择基础大模型(LLM),并通过将知识库嵌入新模型本身来对其进行微调。 何时使用哪种策略? 下图不是黄金法则,但可以提供一些指导: 
虽然微调看起来像是最终的解决方案,但它通常成本更高且需要付出更多努力。 考虑到 RAG 的核心优势,您可能会发现RAG足以解决 70% 到 80% 的用例: 可能考虑微调的场景: 模型输出的稳定性至关重要 在用户数量庞大的情况下,优化推理成本意义重大 LLM 的生成速度具有重要意义 私人托管是必须的
| 









