|
ingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif;color: rgb(31, 35, 41);margin: 0px 0px 4px;word-break: break-all;min-height: 20px;">Agent 为什么被追捧,核心的原因就是它切入业务场景,而大模型只是在信息的节点进行了转换,其实 LLM 也可以做到,只不过对于普通人还是有一定门槛的。 我们假设揭开大多数行业专家的共识背后的面纱, 如果我们深入了解提示词就会发现,其实提示词也可以写工作流, 不论是 工信部 AI 内容生成师的 RMAP 框架, 还是市面上的 LangGPT 框架, CRISPE 框架,BROKE 框架,你都会看到一个提示词块:工作流 ingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif;letter-spacing: 0.578px;margin-top: 0px;margin-bottom: 8px;font-size: 22px;padding-bottom: 0px;">## workflowingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif;color: rgb(31, 35, 41);margin: 0px 0px 4px;word-break: break-all;min-height: 20px;">1, **** ingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif;color: rgb(31, 35, 41);margin: 0px 0px 4px;word-break: break-all;min-height: 20px;">2, **** ingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif;color: rgb(31, 35, 41);margin: 0px 0px 4px;word-break: break-all;min-height: 20px;">3, **** ingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif;color: rgb(31, 35, 41);margin: 0px 0px 4px;word-break: break-all;min-height: 20px;">也就是说,其实没有 Agent,也可以用提示词解决,我们追寻 Agent 最重要的一点,就是期望结果是稳定,而大模型未必能达到,但是是不是我们可以就着这条思路来看呢? 到底大模型 LLM 是不是也可以分析流程呢? ingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif;color: rgb(31, 35, 41);margin: 0px 0px 4px;word-break: break-all;min-height: 20px;">理论说:工作流不是一个 AI 的认知,而是一个思维能力 ingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif;color: rgb(31, 35, 41);margin: 0px 0px 4px;word-break: break-all;min-height: 20px;">我做运营的感受就是:一切任务都可以抽象成一个工作流来执行 ingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif;color: rgb(31, 35, 41);margin: 0px 0px 4px;word-break: break-all;min-height: 20px;">我们一直在说,某种程度上, 我们需要大模型用提示词工程去准确抓取大模型的信息, 我们还忽略了一件事情就是行业 knowhow, 其实我们还忽略了一件事情,就是工作流分析, 这也是很多咨询公司,帮助公司做 BPM 的机会。 ingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif;color: rgb(31, 35, 41);margin: 0px 0px 4px;word-break: break-all;min-height: 20px;">所有的流程抽象过程,基本经历四个阶段, 任务识别:清晰知道自己的 Agent 的具体任务是什么? 流程抽象:对于任务进行管理流程的显性化,画出流程图 思维能力:理解并分析工作流程的能力 稳定性期望:期望通过流程实现一致的稳定的结果。 大型语言模型 (LLM) 应用流程LLM 应用流程的设计理念可以类比为数据管道 (data pipeline),类似于传统的 ETL(提取、转换、加载)流程。 ETL 是Extract, Transform, Load的缩写,中文意思是抽取、转换、加载,它是一种用于数据仓库的数据集成过程。 ETL 过程将来自多个数据源的数据整合到一个统一的目标数据仓库中,以便进行分析和报告。 ETL 过程通常包括以下三个步骤: - 抽取 (Extract):
•从各种数据源(如数据库、文件、API 等)中提取数据。 •数据源可以是结构化的(如关系型数据库)、半结构化的(如 XML 文件)或非结构化的(如文本文件)。 •在这个阶段,需要确保数据的完整性和一致性。 - 转换 (Transform):
•对提取的数据进行清理、转换和格式化,使其符合目标数据仓库的要求。 •转换操作可能包括数据清洗、数据类型转换、数据去重、数据聚合等等。 •这个阶段的目标是确保数据的质量和可用性。 - 加载 (Load):
•将转换后的数据加载到目标数据仓库中。 •数据仓库可以是关系型数据库、NoSQL 数据库或其他数据存储系统。 •在这个阶段,需要确保数据的正确性和完整性。 为什么我要在这里多做解释,主要是这个跟未来我们的知识库建立有关联,其实这个是我们构建自己知识库的本质。 这种流程的核心在于将复杂任务分解为一系列顺序步骤,确保系统的可靠性和可理解性。 以下是一个典型的 LLM 应用流程,被人统称为(IPO): - 输入(Input):
- 数据:来自各种来源,如电子邮件、社交媒体或数据库。
- 提示:用户指令或预定义的指令,引导 LLM 生成特定输出。
- 处理(Process):
- 调用 LLM 生成文本、翻译语言、回答问题或执行其他任务。
- 中间函数:对数据进行预处理、后处理或执行特定计算。
- 外部 API 调用:与其他服务交互以获取额外信息或执行特定操作。
- 这通常是 LLM 发挥作用的地方,可以是一个简单的步骤,也可以是包含多个步骤的复杂链。
- 处理步骤可以包括:
- 处理流程的设计应遵循顺序方法,例如有向无环图 (DAG),确保数据单向流动,提高系统的可靠性。
- 输出(Output):
- LLM 生成的输出,例如文本、代码、翻译或其他数据。
- 输出可以存储在数据库中,显示在前端应用程序中,或用于触发其他操作。
•ETL 侧重于知识数据的集成和预处理,目标是构建知识库以供分析和报告使用。 •LLM 应用流程侧重于利用 LLM 的能力来处理特定任务,例如文本生成、翻译、问答等等。 关键设计模式: - 责任链模式 (Chain of Responsibility Pattern):将处理步骤分解成独立的模块,每个模块负责特定的任务,并按顺序执行。
- 注册表模式 (Registry Pattern):根据输入数据的类型或其他条件,动态选择和执行相应的处理管道。
示例:我们以电子邮件的回复为例 如何将 LLM 应用流程构建成一个 Agent。 应该包含以下步骤: - 接收电子邮件:我把多个文档放进大模型的对话框,让大模型接收到这些电子邮件。
- 分类邮件:使用 LLM 对电子邮件进行分类,例如确定其主题或意图。
- 生成回复:使用 LLM 根据邮件分类和预定义的模板生成各自独立的回复。
- 发送回复:将生成的回复,单独黏贴发送给发件人。
这样不用智能体,加点人工也能完成。 所以都是带着 LLM 去思考,写出流程让 LLM 跟着执行结果也不会偏差太大。 LLM prompt 提示词添加流程思维的优势就出来了: - 简单性:将复杂任务分解成简单步骤,更易于理解、实现和维护。
- 可靠性:顺序处理流程确保每个步骤按预期执行,减少错误和意外结果的可能性。
- 可扩展性:可以轻松地添加、删除或修改处理步骤,以适应不断变化的需求。
- 可控性:可以对每个步骤进行监控和调试,更容易识别和解决问题。
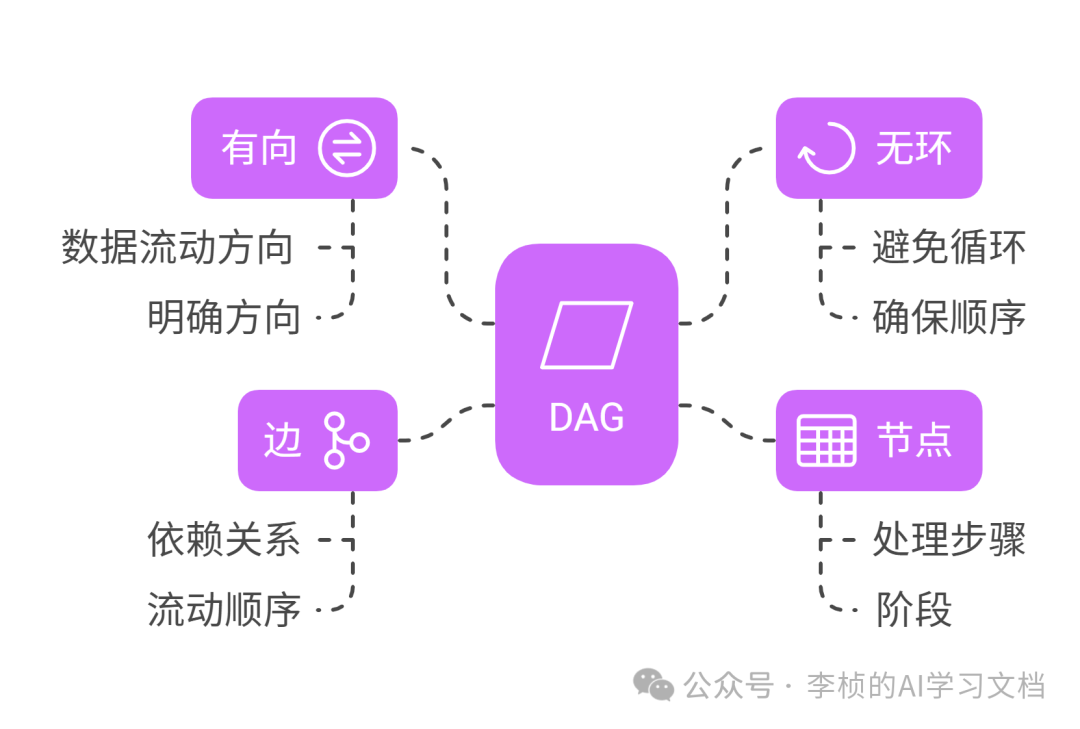
将 LLM 应用流程设计为智能体的流程也可以大大提高系统的可靠性、可扩展性和可控性,从而更有效地利用 LLM 解决实际问题。所以我经常在培训里说, 我们面对 AI 时代最大的两个看, 就是提示词的构建方法&工作流的设计思维。 初学者建议 - DAG (Directed Acyclic Graph)要想工作流思维学号, 可靠性增强:顺序工作流程,也称为有向无环图 (DAG),确保数据仅在一个方向流动。这种方法消除了循环依赖性,从而简化了调试和维护,同时提高了应用程序的整体稳定性。  什么是有向无环图 (DAG)?有向无环图 (DAG)是一种数据结构,它由节点和边组成,其中边表示节点之间的方向性关系(是不是跟我们教学的 Coze 很有关系? ) .DAG 的关键特征是它不包含循环,这意味着从任何节点出发,沿着边的方向行进,都无法回到起点。 在构建可靠的 LLM 应用中,DAG 经常被用来设计数据处理流程,即数据管道。这是因为 DAG 的无环特性可以确保数据流是单向的,从而提高系统的可靠性。 以下是对 DAG 特性的进一步解释: - 有向:DAG 中的每条边都有一个明确的方向,指示数据流动的方向。
- 无环:DAG 中不存在任何循环路径,这意味着数据不能沿着边循环流动。
- 节点:节点表示数据处理步骤或阶段。
- 边:边表示节点之间的依赖关系,指示数据从一个节点流向另一个节点的顺序。
使用 DAG 设计数据管道的好处: - 可靠性:DAG 的无环特性确保每个处理步骤都依赖于其前序步骤的完成,从而避免循环依赖和潜在的死锁问题。
- 可理解性:DAG 提供了数据处理流程的清晰可视化表示,使其易于理解和维护。
- 可扩展性:可以轻松地向 DAG 添加或删除节点和边,以适应不断变化的需求。
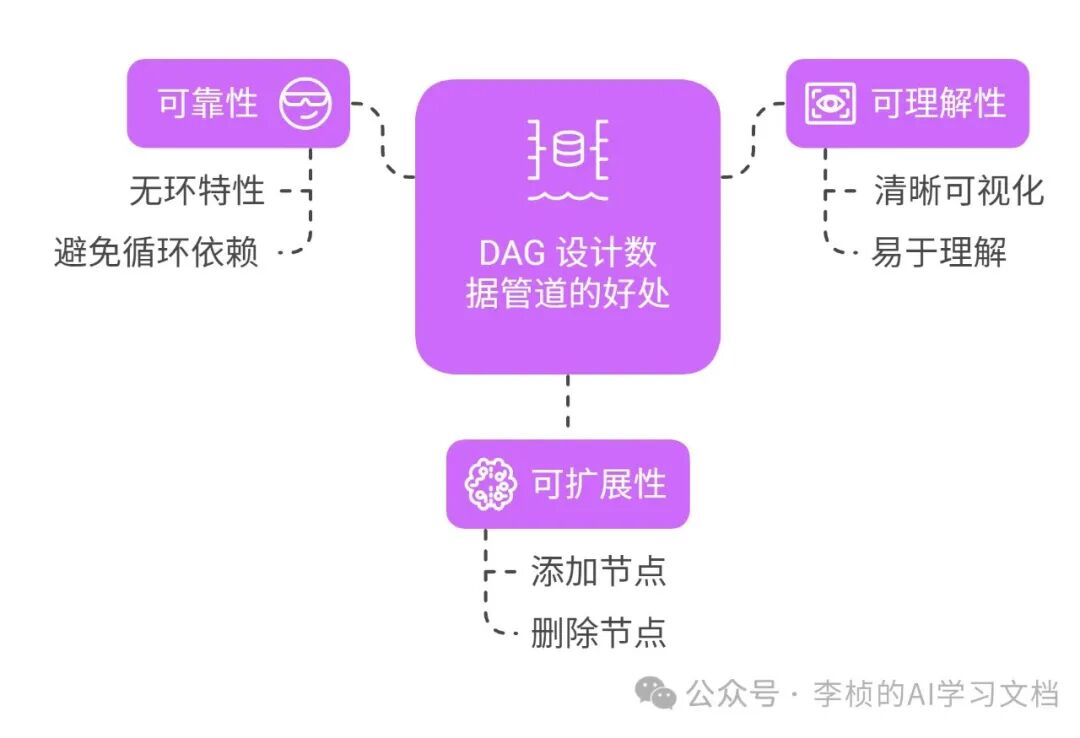
DAG 是一种强大的数据结构,可以用来构建可靠、可扩展和易于理解的数据处理流程。 在 LLM 应用中,DAG 可以作为设计提示词工作流的设计基础,从而提高 LLM 的整体回复质量和性能。在 Agent 应用中, DAG 可以增加循环,批处理等节点,但是 DAG 是新手学习工作流思维以及 Agent 的基础。
|










