|
今天,Qwen2.5-1M模型开源。 2个尺寸,7B & 14B。开源并且,并结合vllm,集成了稀疏注意力机制,推理速度提升3到7倍。 - 技术报告地址:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
- hf: https://huggingface.co/collections/Qwen/qwen25-1m-679325716327ec07860530ba
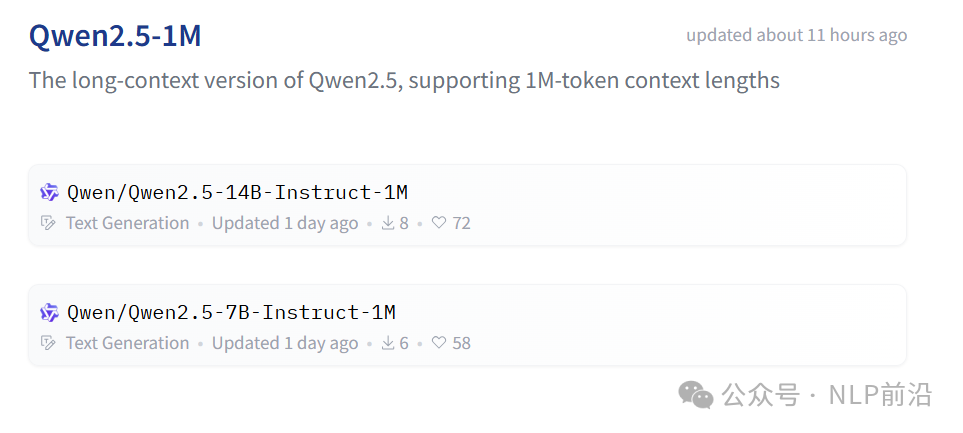 14B模型的大海捞针获得了全绿的成绩,7B仅少量错误 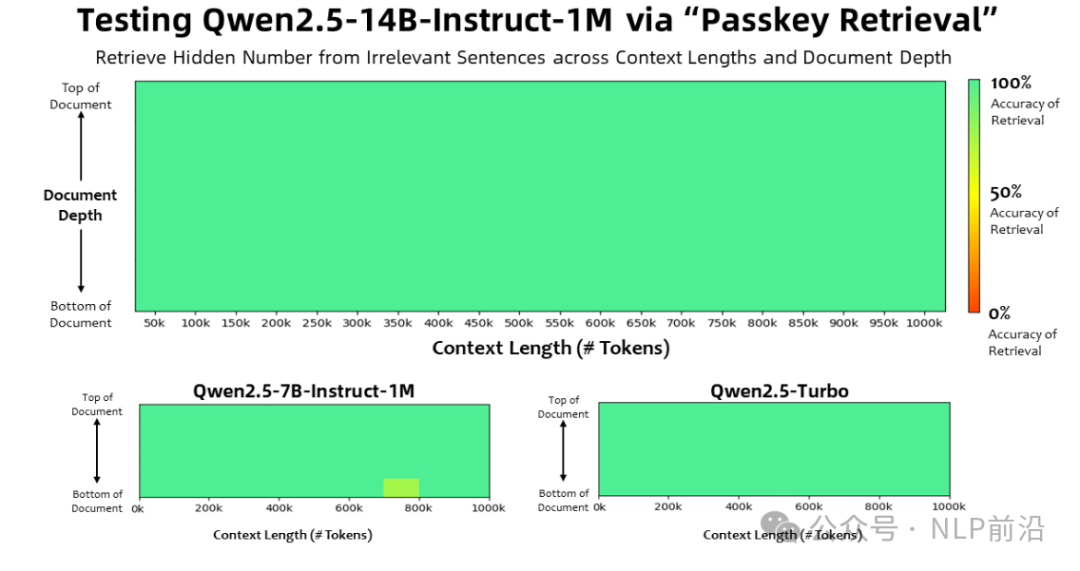 长度提升的同时,短序列的成绩依然保持优异!  训练策略: 逐步变长到256K。 然后使用长度外推,外推用到了DCA的策略, 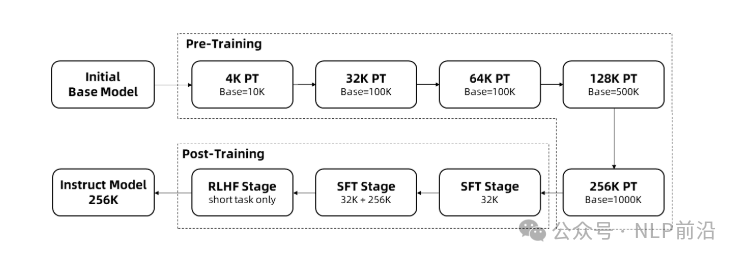 DCA通过将大的相对位置,按chunk分组,映射为较小的值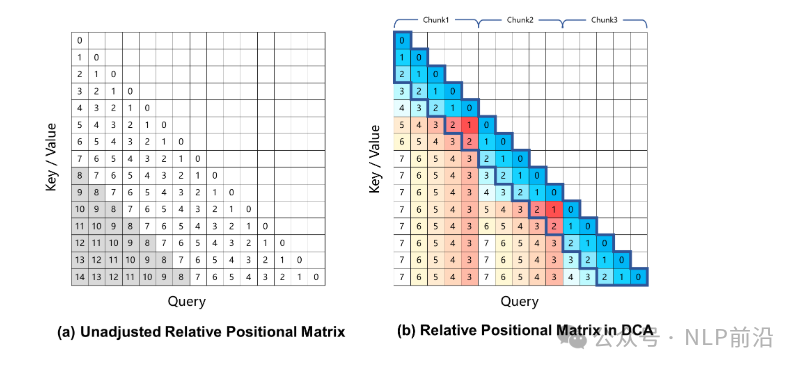 最后是硬件依赖: 对于处理 1M 长度的序列: - Qwen2.5-7B-Instruct-1M:至少需要 120GB 显存(多 GPU 总和)。
- Qwen2.5-14B-Instruct-1M:至少需要 320GB 显存(多 GPU 总和)。
如果 GPU 显存不满足以上要求,仍然可以使用 Qwen2.5-1M 进行较短任务的处理。 最后,祝大家新年快乐!
| 









