|
自从OpenAI变成CloseAI之后,只能看到他们发布一个个越来越强的模型(GPT3.5 -> GPT4 -> 4o -> o1 -> 4.5 -> o3 -> 4.1),并不知道他们最先进的模型的技术路线。
对于大家来说,这就变成了一个解密任务。需要先破解出这个谜题,有一个开源版本之后,跟班们才能疯狂跟进。 挺长时间没有发过算法相关内容了,目前经常看咱们号的应该非技术出身的同学更多了。本文尽量用最简单、容易理解的方式介绍这个内容~ DeepSeek R1在今年年初,模型和论文同时开源,以o1同等的智力水平,火爆全球。 R1之后,有各种蹭热度的R1-VL模型被开源。为什么说是蹭热度,因为真的只是把backbone换成了VL模型,其他的所有一切都当成纯语言的模型来训练的。 OpenAI o3强在哪里?跟这些R1-VL模型的区别在哪? o3其实是一个智能体,它可以自主的调用各种工具,来完成任务。 边看图边思考,图像不仅仅是第一轮的时候才会输入,中间会产生中间图片,继续作为信息输入到VL模型中。 下图为部分思考示例:  DeepSeek R1告诉大家o1谜底的答案是什么? 只需要对思考之后结果的正确性进行奖励,不需要蒙特卡洛树、步骤奖励等等复杂策略。 基于这个奖励 + 一个还不错的基础模型上 进行强化学习训练,就可以让模型在回答答案前深入思考,从而激发出模型更强的智力。 前天有篇论文,核心贡献成员是小红书团队的。为什么说他们“似乎破解了o3的谜题呢?”  o3的核心能力是调用工具,可以边看图边思考,每一次思考,产生Action,调用完工具获取的观察(Observation)结果会进入模型的输入,进而产生下一步的Action结果。 论文提到动机是基于一个观察:人在面对一个视觉问题时,绝对不是看一眼图,然后就在脑子里疯狂进行文本推理。而是会边看边想,甚至有些天生具备“视觉思维”的大佬,他们思考的主要方式就是图像和视觉化的。 前面提到,现在很多VLM处理图片的方式还是太“糙”了,图片在一开始输入给模型时,由vision encoder一次性转换成image embedding,然后这张图片就变成了纯静态的背景板。之后模型所有的“思考”几乎都是纯文本的CoT。这种方式在处理复杂的视觉信息时,无疑是“有损的”。 如果我们能让VLM真正做到边看图边思考,它就可能会进化出一些完全不同于文本CoT、独属于视觉领域的思考方式。 这里有一个很困难的问题是: VLM本身并不能直接输出图像token,所以如何让模型可以边看图边思考呢? DeepEyes给出的答案是——Agent框架!给模型配备了一个图像工具:image zoom-in(图像局部放大)。模型可以通过自己输出bounding box的坐标来调用这个工具,从而能够按照自己的“意愿”去观察图片中它感兴趣或者认为重要的部分。 为什么要选图像局部放大这个工具呢? 首先这个工具可以适用于任何视觉理解和推理任务。其次这个工具依赖模型对图片区域的定位输出,这个准确率是可以端到端RL训练优化的。 最后是,能让Agent的RL训练work,到底应该如何奖励? 最好的奖励是,只有做对了题目,并成功调用工具,才给一个额外的奖励 (如果没有调用工具做对题目奖励 < 调用工具且做对的奖励)。训练最稳定,效果最好。  他们的模型表现是非常好的,在一些特定场景可以拿出来跟o3中门对狙。 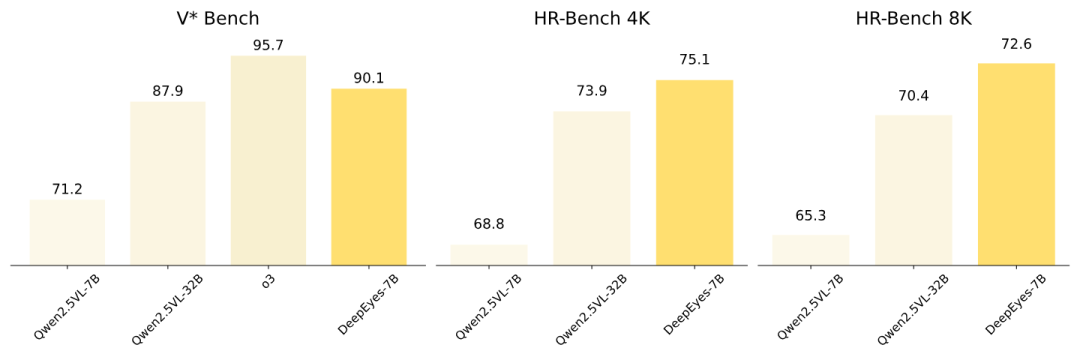  最后,谜底揭开了,可能会感觉很容易,就跟R1一样。 不过!把一个看起来很简单的idea真正做work,中间的坑远比很多人想象中多得多。
| 









