|
在构建复杂的数据处理系统或任务调度平台时,如何将业务逻辑高效、灵活地表达出来,并以可扩展的方式进行执行,是许多工程师和架构师面临的核心挑战之一。本文从“程序编排”的角度出发,探讨在实际项目中常见的几种核心编排方式——包括单语句表达式、类结构映射、流程化配置以及并行化调度,并结合一个真实系统的演进过程,分享我们在设计高灵活性任务处理引擎中的实践经验。 这些编排方式不仅适用于特定的数据处理场景,更是一种通用的系统设计思维。无论你是开发数据流水线、搭建自动化运营平台,还是构建低代码任务引擎,掌握这些模式,都能帮助你在面对复杂逻辑时更加游刃有余。 表达式语句相对比较容易上手一些,其语法更接近 Java,而且有些表达式引擎还会将表达式编译成字节码,在执行速度和资源利用方面可能就更有优势。因此在业务没那么复杂,并且不想硬编码写的话,使用表达式语句性价比最高。犀牛系统中多处使用了表达式语句,通过数据库中配置表达式语句,提高系统灵活性。 MVEL(MVFLEX Expression Language)MVEL是一个基于java语法的表达式,为JAVA语言提供便捷灵活的动态性,是部分规则引擎的底层调用。 使用示例如下: Stringexpression="score>60";HashMap<String,Integer>vars=newHashMap<>(1);vars.put("score",100);if((Boolean)MVEL.eval(expression,vars)){System.out.println("分数及格");}OGNL(Object-Graph Navigation Language)OGNL主要用于获取和设置Java对象的属性,主要通过反射的方式实现。 使用方式: Map<String,Object>map=newHashMap<>();map.put("key","value");Stringexpression="#{key}";OgnlContextcontext=buildContext();Objectresult=Ognl.getValue(expression,context,map);System.out.println(result);AviatorAviator是一门高性能、轻量级的Java语言实现的表达式动态求值引擎,可将表达式编译成字节码。其有两种执行方式: 编译执行和不编译执行。 使用方式: Stringexpression="a*(b-c)";Map<String,Object>env=newHashMap<>();env.put("a",3.3);env.put("b",2.2);env.put("c",1.1);intnum=10000;//编译longl=System.nanoTime();ExpressioncompliedExp=AviatorEvaluator.compile(expression);for(inti=0;i<num;i++){compliedExp.execute(env);}System.out.println((System.nanoTime()-l)/1000000);l=System.nanoTime();//不编译for(inti=0;i<num;i++){AviatorEvaluator.execute(expression,env);}System.out.println((System.nanoTime()-l)/1000000);编译和不编译耗时相差7倍,但由于编译之后占用内存,首次编译加载耗时较长,因此需要根据调用次数以及编译成本,判断是否有必要进行编译。 总结: 如果追求性能,并且主要是简单的动态计算的话,不需要对对象进行操作,可以使用Aviator。如果方法调用和对象属性的访问等,倾向于使用OGNL,其基于反射,操作比较灵活。而MCEL介于两者之间。 较为适合快速开发。当然以上限制也不是绝对的,如果追求性能可以对其进行优化,如在OGML或者MVEL加一层缓存,命中缓存可以加快响应速度。 在项目开发当中,经常会出现某个类的属性或几个属性是另外一个类的查询条件,无论是数据库查询还是rpc调用,需要显式手动拼接,并且由于使用范围不同,只会取某些类,随着项目的迭代,这往往会导致代码中混乱调用,以及业务中有众多相似代码,但如果统一在一起加载,例如使用聚合根的思想,又会造成某些不需要的类加载,造成读放发大。 本节介绍model-view-builder框架,来解决上述问题。 model-view-buildergithub地址: https://github.com/PhantomThief/model-view-builder,这是一个能力非常强大的框架,其使用函数式编程定义加载动作,树状结构关联加载类,懒加载延时构建。 函数式编排SimpleModelBuilderbuilder=newSimpleModelBuilder<SimpleBuildContext>().self(TaskInfo.class,TaskInfo::getTaskId).on(TaskInfo.class).id(TaskInfo::getTaskId).to(Decision.class).on(TaskInfo.class).id(TaskInfo::getTaskId).to(Disposal.class).on(TaskInfo.class).id(TaskInfo::getTaskId).to(RiskControl.class).on(TaskInfo.class).id(TaskInfo::getPoiId).to(DeepInfo.class).on(TaskInfo.class).id(TaskInfo::getPoiId).to(PoiInfo.class).build(Decision.class,decisionDao::getDecisionMap).build(Disposal.class,disposalDao::getDisposalMap).build(RiskControl.class,riskControlDao::getRiskControlMap).build(DeepInfo.class,deepInfoDao::getDeepInfoMap).build(PoiInfo.class,poiInfoDao::getPoiInfoMap); 树状结构关联
懒加载构建builder=newSimpleModelBuilder<UgcBuildContext>().self(A.class,A::getId).lazyBuild(A.class,(BuildContextcontext,Collection<String>ids)->BService.get(ids),B.class)//只有在调用获取的B的时候,才会执行BService.get取值逻辑buildContext.get(B.class) 其中lazyBuild是懒加载,只有在读取的时候会调用;重复获取数据的时候也不会重复调用,可以避免读放大。 该框架使用多层Map维护类与函数,以及类与类之间的映射关系,使其具有编排、聚合的能力,这些能力天然就适合领域划分,通过领域划分确定边界作为上下文信息,在方法中传递使用,提高代码可读性的同时,也为研发人员提供高效获取数据的体验。 业务示例描述:有这么一个需求,先查询帖子,再查询评论,最后查询是否是粉丝。 构建modelBuilder 
构建与读取结果

框架缺点同样也很明显: 在考虑引入该框架的时候,需要考虑以上缺点在团队中是否成问题,如果没问题,可放心使用,你大概率会成为它的重度用户。 有限状态机编排如果项目中有很多实体,每个实体都有很多状态,各状态会经过不同事件触发后转换到另一个状态,当实体状态或者状态转换变多时,处理这些状态的业务代码会分散在各处,往往会对开发和维护造成不小的挑战,有限状态机可以缓解这一情况。 使用状态机来表达状态的流转,语义会更加清晰,会增强代码的可读性和可维护性。 Stateless4jstateless4j是一个轻量级的状态机库,其核心概念是基于枚举的事件和状态。 例子: 超级玛丽闯关 publicfinalstaticStateMachineConfig<CurrentState,Trigger> config=newStateMachineConfig<>();
static{ //最初为小状态 config.configure(CurrentState.SMALL) .permit(Trigger.MUSHROOM,CurrentState.BIG)//遇到蘑菇触发-->big状态 .permit(Trigger.MONSTER,CurrentState.DEAD);//妖怪触发,死亡状态 //最初为大状态 config.configure(CurrentState.BIG) .ignore(Trigger.MUSHROOM) .permit(Trigger.FLOWER,CurrentState.ATTACH)//遇到花花,状态变为可攻击状态 .permit(Trigger.MONSTER,CurrentState.SMALL);//遇到妖怪,状态变为small //最初为攻击状态 config.configure(CurrentState.ATTACH) .ignore(Trigger.MUSHROOM) .ignore(Trigger.FLOWER) .permit(Trigger.MONSTER,CurrentState.SMALL);//遇到妖怪,状态变为small //最初为死亡状态 config.configure(CurrentState.DEAD) .ignore(Trigger.MUSHROOM) .ignore(Trigger.FLOWER) .ignore(Trigger.MONSTER);
}
代码逻辑如下: privatestaticStateMachine<CurrentState,Trigger>stateMachine=newStateMachine<CurrentState,Trigger>(CurrentState.BIG,StateConver.config);publicstaticvoidmain(String[]args){stateMachine.fire(Trigger.FLOWER);System.out.println("currentState-->"+stateMachine.getState());}当前状态为大马里奥,当遇到花之后,状态就变为可攻击了。 Cola-StateMachine是一个功能丰富的状态机框架,支持XML和Java API定义状态机,提供图形化建模工具。 使用起来比较复杂,这里就贴一个github地址:https://github.com/spring-projects/spring-statemachine.git 总结:Cola-StateMachine比stateless4j功能更丰富,更完备,有更多高级的玩法。 语法树编排Antlr4Antlr4具有强大的语法分析能力,可以生成解析指定语言的Java代码;可用于解析和处理各种数据格式,帮助我们快速构建数据解析器,同时也有静态代码分析的能力。 使用示例:解析某文件格式 定义g4文件: grammar load; //定义规则文件grammar//parserssta load ender)*; //定义sta规则,里面包含了*(0个以上)个 load ender组合规则 load ender)*; //定义sta规则,里面包含了*(0个以上)个 load ender组合规则ender:';'; //定义ender规则,是一个分号load //定义load : LOAD format'.'path astableName//load语法规则,大致就是 load json.'path' as table1,load语法里面含有format,path, as,tableName四种规则 ; //load规则结束符as: AS; //定义as规则,其内容指向AS这个lexertableName: identifier; //tableName 规则,指向identifier规则format: identifier; //format规则,也指向identifier规则path: quotedIdentifier;//path,指向quotedIdentifieridentifier: IDENTIFIER | quotedIdentifier; //identifier,指向lexer IDENTIFIER 或者parser quotedIdentifierquotedIdentifier: BACKQUOTED_IDENTIFIER; //quotedIdentifier,指向lexer BACKQUOTED_IDENTIFIER//lexers antlr将某个句子进行分词的时候,分词单元就是如下的lexer//keywords 定义一些关键字的lexer,忽略大小写AS: [Aa][Ss];LOAD: [Ll][Oo][Aa][Dd];//base 定义一些基础的lexer,fragment DIGIT:[0-9]; //匹配数字fragment LETTER:[a-zA-Z]; //匹配字母STRING //匹配带引号的文本 :'\''( ~('\''|'\\') | ('\\'.) )*'\'' |'"'( ~('"'|'\\') | ('\\'.) )*'"' ;IDENTIFIER //匹配只含有数字字母和下划线的文本 : (LETTER | DIGIT |'_')+ ;BACKQUOTED_IDENTIFIER //匹配被``包裹的文本 :'`'( ~'`'|'``')*'`' ;//--hiden 定义需要隐藏的文本,指向channel(HIDDEN)就会隐藏。这里的channel可以自定义,到时在后台获取不同的channel的数据进行不同的处理SIMPLE_COMMENT:'--'~[\r\n]*'\r'?'\n'? -> channel(HIDDEN); //忽略行注释BRACKETED_EMPTY_COMMENT:'/**/'-> channel(HIDDEN); //忽略多行注释BRACKETED_COMMENT :'/*'~[+] .*?'*/'-> channel(HIDDEN) ; //忽略多行注释WS: [ \r\n\t]+ -> channel(HIDDEN); //忽略空白符
// 匹配其他的不能使用上面的lexer进行分词的文本UNRECOGNIZED: .;
文件自动生成: 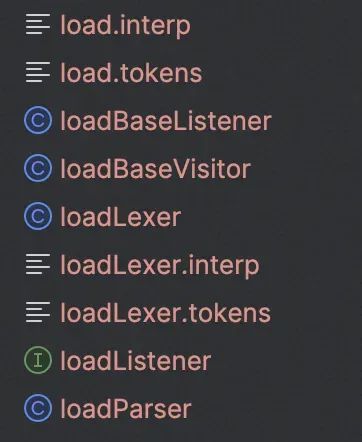
覆盖BaseListen的enterLoad方法: 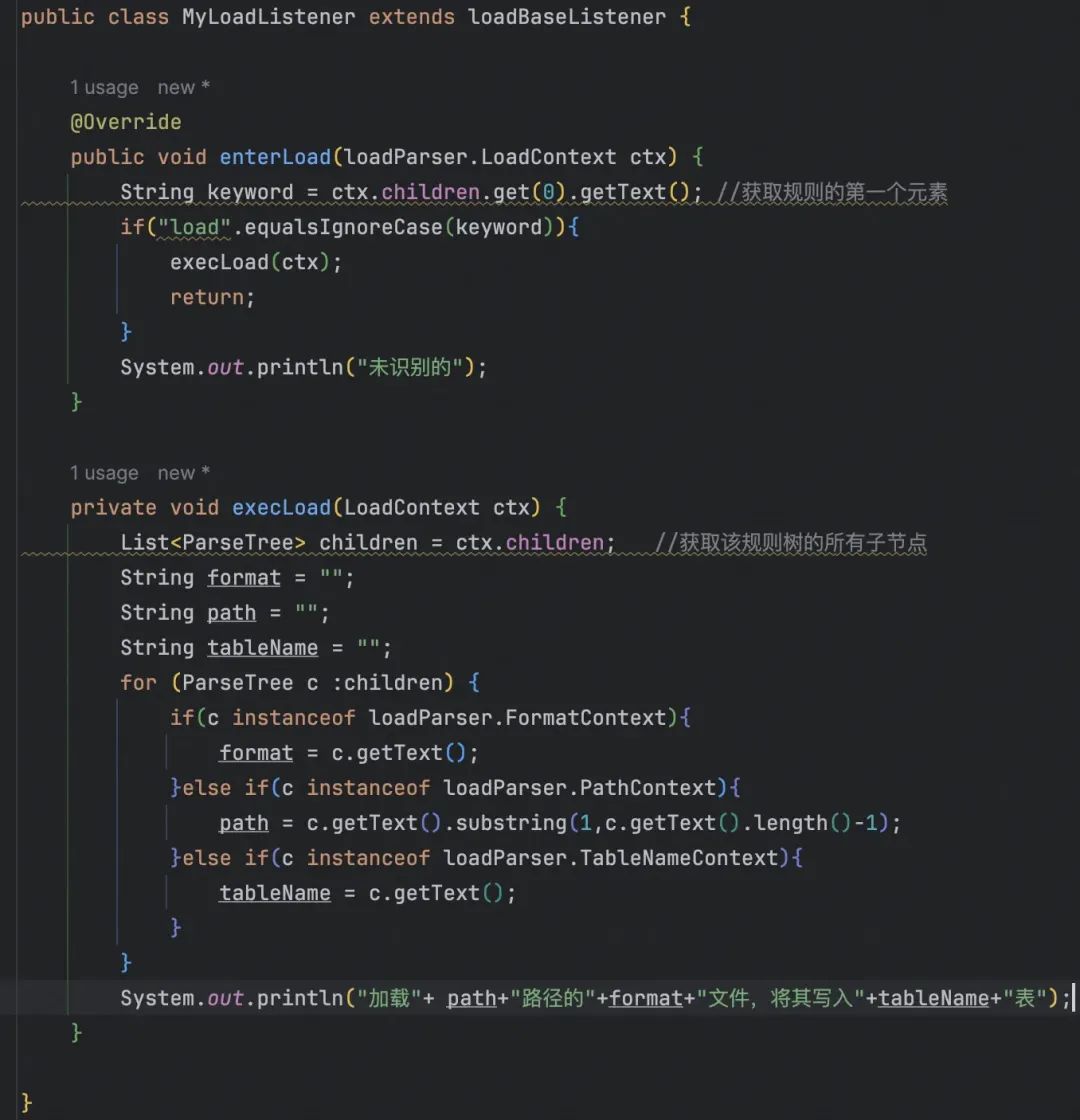
测试代码: publicstaticvoidmain(String[]args){StringoriStr="loadjson.`F:\\tmp\\temp.json`astemp;";ANTLRInputStreaminput=newANTLRInputStream(oriStr);loadLexerlexer=newloadLexer(input);CommonTokenStreamtokens=newCommonTokenStream(lexer);loadParserparser=newloadParser(tokens);loadParser.LoadContexttree=parser.load();MyLoadListenerlistener=newMyLoadListener() arseTreeWalker.DEFAULT.walk(listener,tree);} arseTreeWalker.DEFAULT.walk(listener,tree);}结果: 
可以看到这个框架非常强大,但是理解成本和实现成本比较高,如果你发现市面上没有框架实现你想要的编排能力,可以考虑使用该框架进行挑战。 引擎编排Drools(规则引擎)规则引擎的主要思想是将应用程序中的业务决策部分分离出来,使用指定的语句编写业务规则,由用户或开发者在需要时进行配置、管理。 drools是基于Java语言开发的开源规则引擎,将复杂的业务规则从硬编码中解放出来,以规则脚本的形式存储起来,当业务规则改变的时候不用修改代码。 示例如下: 规则配置: //图书优惠规则package book.discountimportdrools.Order
//规则一:所购图书总价在100元以下的没有优惠rule"book_discount_1" when $order:Order(originalPrice<100) then $order.setRealPrice($order.getOriginalPrice()); System.out.println("成功匹配到规则一:所购图书总价在100元以下的没有优惠");end
//规则二:所购图书总价在100到200元的优惠20元rule"book_discount_2" when $order:Order(originalPrice<200&&originalPrice>=100) then $order.setRealPrice($order.getOriginalPrice()-20); System.out.println("成功匹配到规则二:所购图书总价在100到200元的优惠20元");end
//规则三:所购图书总价在200到300元的优惠50元rule"book_discount_3" when $order:Order(originalPrice<=300&&originalPrice>=200) then $order.setRealPrice($order.getOriginalPrice()-50); System.out.println("成功匹配到规则三:所购图书总价在200到300元的优惠50元");end
//规则四:所购图书总价在300元以上的优惠100元rule"book_discount_4" when $order:Order(originalPrice>=300) then $order.setRealPrice($order.getOriginalPrice()-100); System.out.println("成功匹配到规则四:所购图书总价在300元以上的优惠100元");end
测试代码: KieServiceskieServices=KieServices.Factory.get(); KieContainerkieClasspathContainer=kieServices.getKieClasspathContainer(); //创建会话,用于和规则引擎交互 KieSessionkieSession=kieClasspathContainer.newKieSession(); //构造订单对象,设置原始价格 Orderorder=newOrder(); order.setOriginalPrice(210.0); //将数据提供给规则引擎,规则引擎会根据提供的数据进行规则匹配 kieSession.insert(order); //激活规则引擎,如果规则匹配成功则执行规则 kieSession.fireAllRules(); //关闭会话 kieSession.dispose();
System.out.println("优惠前原始价格:"+ order.getOriginalPrice() + ",优惠后价格:"+ order.getRealPrice());
结果: 
配置文件和代码逻辑分开来,如果活动变动,只需要修改配置文件就行了。 BPMN(流程引擎)流程引擎的关注的是业务流程,编排业务流程,使用文件或者指定语言规则进行配置。 示例代码: 犀牛系统中任务的调度流程: 
其中streamMainProcess为xml文件的key。 调用逻辑: 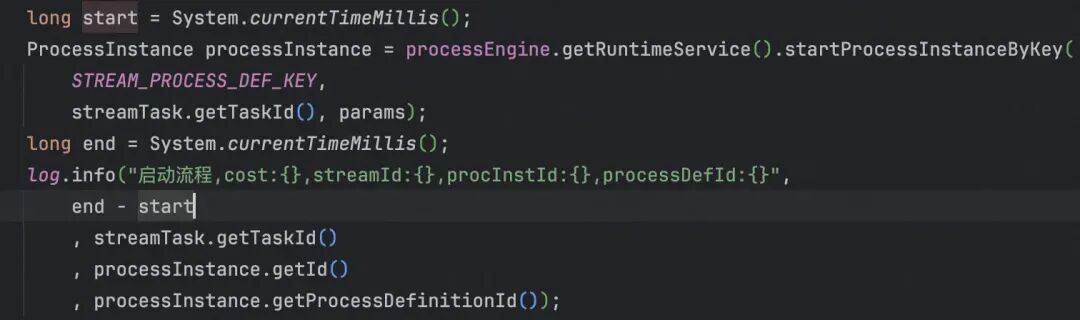
其中STREAM_PROCESS_DEF_KEY=streamMainProcess。 流程的配置和代码逻辑分开,如果变动流程只需要变动xml文件就可以了。 虽然规则引擎和流程引擎都可以将相应配置分开,但当业务较为复杂时,会有不易维护的特点,因此需要更方便的可视化来帮助理解,代表引擎有ice(https://waitmoon.com/),通过二叉树组织,一个节点表示条件,另一个节点表示结果/动作。除此之外,规则引擎还有一定的性能问题,高并发业务下容易成为性能瓶颈。 如果有a,b,c,d四个线程,b,c运行的前提是a运行结束,d运行的前提是b,c运行结束。业务简单的话硬编码是没有问题的,但当并行线程达到十几个,你要如何进行进行编排呢,本节就此问题抛砖引玉,聊聊并行化编排。 CompleteFutureCompletableFuture 是一种高级的并发工具,它允许你组合多个异步操作,创建复杂的异步流程。 使用示例如下: CompletableFuture<String>taskA=CompletableFuture.supplyAsync(()->executeA());CompletableFuture<String>taskC=taskA.thenApplyAsync(result->executeC());CompletableFuture<String>taskB=taskA.thenApplyAsync(result->executeB());CompletableFuture<Void>voidCompletableFuture=CompletableFuture.allOf(taskC,taskB).whenComplete((result1,result2)->executeD());voidCompletableFuture.join(); 可以看到CompletableFuture为我们提供了并发编排的能力,但如果线程数量较多,其维护性就比较差了。 Reactorreactor是基于reactive stream规范实现的一个响应式编程框架,使用函数式编程的概念来操作数据流。相比于CompletableFuture,代码量少,流程更清晰,功能更加强大。 使用示例如下: 
其实现了响应式编程模型思想,有自定义操作符,同时支持背压机制,能够控制生产消费速度,因此它更适合响应式开发以及复杂数据流处理。 算法编排当线程数量比较多的时候,线程与线程之间相互关联,并以图的方式进行链接,开源框架也不适用此类场景。可以考虑使用图的广度优先遍历来进行编排,参考LeetCode207(https://leetcode.com/problems/course-schedule/description/)。 入参之需要描述线程与线程之前的关系,通过关系先建图,然后一层一层遍历图,每一层都并发执行,最后将结果汇总。 编排相对比较小众,主要是因为在用它的时候既需要平衡性能和灵活性的关系,又要考虑学习成本和适应场景,考虑不当往往会为了用而用。 本文主要为了抛砖引玉,提供一些市面上流行的编排框架,供大家参考。 | 









