本文主要介绍了一个名为 ROLL(Reinforcement Learning Optimization for Large-scale Learning) 的高效强化学习框架,专为大规模语言模型(LLM)的训练和优化而设计。文章从多个角度详细阐述了 ROLL 的设计理念、核心特性、技术架构、应用场景及实验效果。
作者:亚里、惟昕、淼平、明念、星霂
Q: 是什么?
是什么?
A:Reinforcement LearningOptimization forLarge-scaleLearning(ROLL!)
开源(欢迎star!!):https://github.com/alibaba/ROLL
报告:https://arxiv.org/abs/2506.06122
ROLL 是一个高效且用户友好的强化学习库,专为不同类型用户设计,它不仅能够在各种硬件资源条件下高效完成多样化的训练目标,还特别针对需要大规模 GPU 资源的大语言模型(LLM)优化设计。
ROLL在诸如人类偏好对齐、复杂推理和多轮自主交互场景等关键领域显著提升了大语言模型的性能。ROLL 利用基于 Ray 的多角色分布式架构实现灵活的资源分配和异构任务调度,集成了 Megatron-Core、Deepspeed、SGLang 和 vLLM 等前沿框架与技术,以加速模型训练和推理。
Q:为什么“我”要使用ROLL?
A:满足“你”的不同需求

当前已有多个针对大语言模型优化的强化学习框架,为什么要选择 ROLL?除了 ROLL 是我们内部自研的"原生框架"的“血脉认证”外,它在设计之初就从用户视角出发,深入分析了用户在使用类似框架时的痛点和高频需求。通过将这些需求作为"一等公民"优先实现,ROLL 更好地平衡了实用性与易用性,为用户提供了更优质的开发体验。
如果你是业务算法同学,当你有使用RL优化LLM的业务能力时,那你肯定会喜欢ROLL,因为ROLL具备以下特性:
当你想要在有限资源的约束下,预研一下RL优化LLM的业务优化空间或进行相关的前沿探索,那你肯定会喜欢ROLL,因为ROLL具备以下特性:
ROLL通过精细的资源控制和内存优化技术,ROLL 能在有限 GPU 资源(包括单卡场景)下实现高效训练,支持快速试错和迭代优化。
如果你肩负重要的线上业务指标,需要调配大规模计算资源使用RL进行 LLM 优化时,那你肯定会喜欢ROLL,因为ROLL具备以下特性:
ROLL能充分发挥高性能硬件潜能,显著提升 RL 训练速度,在大规模 GPU 集群上,有效降低训练成本和时间开销。
ROLL支持各类主流 LLM 训练和服务优化技术,支持跨数千个 GPU 对高达 200B + 参数的模型进行可扩展训练,配备高效的检查点与恢复机制,确保训练连续性与稳定性。
ROLL支持多种硬件平台(比如PPU)的 RL 训练,提供协同部署(colocation)和分离部署(disaggregation)方案,支持同步/异步执行模式,充分适配不同硬件架构特性。
如果现在你对ROLL有了兴趣,那么让我们进入ROLL的时间!
RLVR(RL with Verifiable Reward)
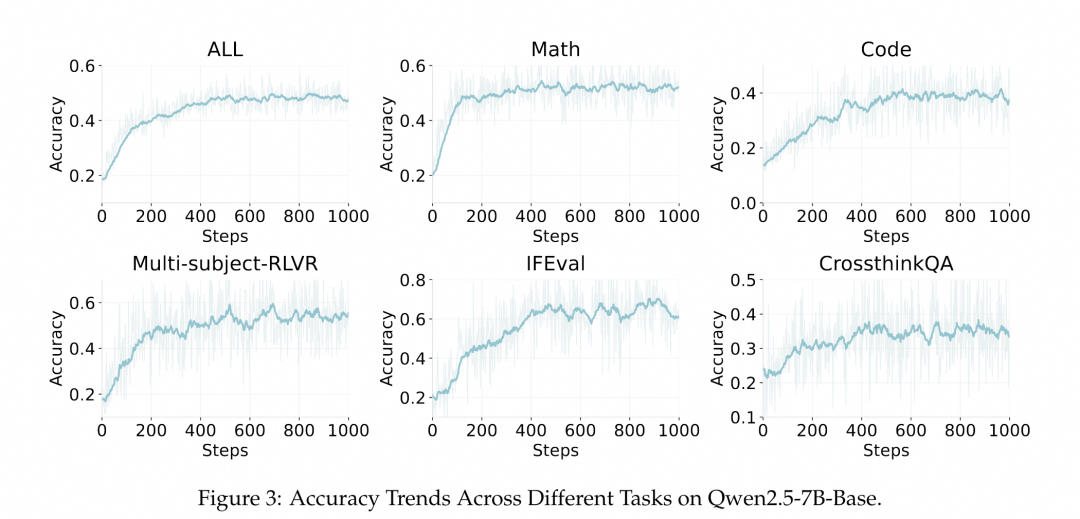
Figure3 a. Dense: Qwen2.5-7B-Base | 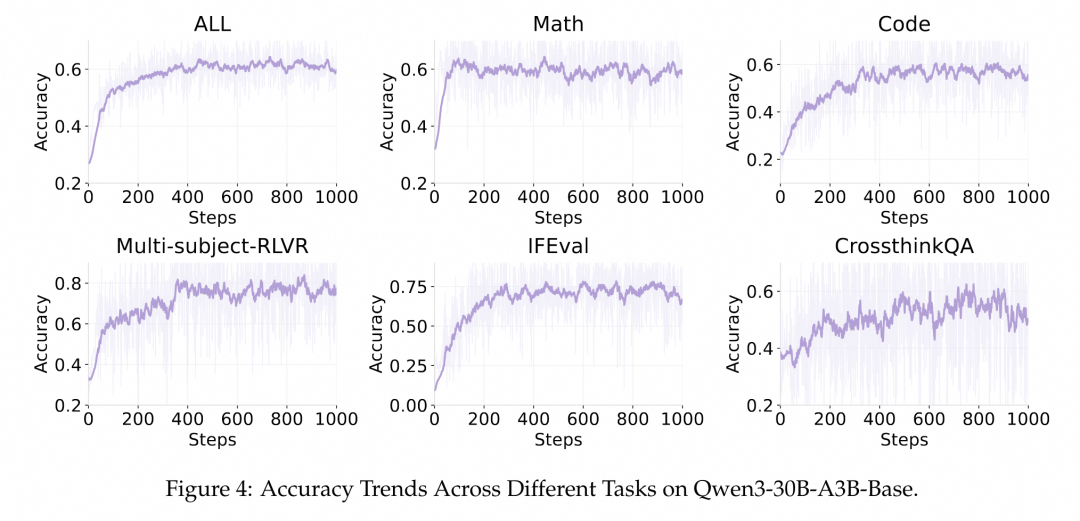
Figure 4 a. MOE: Qwen3-30B-A3B-Base |

Figure3 b. MOE架构 200+B | 
Figure 4 b.MOE架构200+B |

Figure 4 c Qwen2.5-VL-7B-Instruct 训练score曲线 |
数据收集与训练设置
RLVR Pipeline的实验中,我们系统性地从三个领域中精选数据集进行数据采集:
数学领域:使用 DeepMath-103K,按难度比例采样 5,000 条样本。
代码领域:基于 KodCode数据集,首先过滤低质量数据,再按难度均匀采样 2,000 条记录。
通用推理领域:整合 Multi-subject-RLVR、Nemotron-CrossThink和 RLVR-IFeval,并去除低质量数据以提升整体质量。
在训练设置方面,我们选择了两个主流大语言模型:Qwen2.5-7B-Base 和 Qwen3-30B-A3B-Base。在策略优化过程中,我们采用 PPO 损失函数,并通过 REINFORCE 方法计算优势值,而非传统的 GAE 估计方法。
跨领域的采样比例设定为:数学占 40%,代码占 30%,通用推理占 30%。
我们在训练过程中引入了多种验证机制:规则验证用于数学任务,沙箱执行用于代码生成,而通用推理则结合规则验证与 LLM-as-Judge。
性能表现
如图 3a 所示,经过 ROLL 训练后,Qwen2.5-7B-Base 模型的整体准确率由初始的 0.18 提升至 0.52,提升了近 2.89 倍。具体来看,数学推理任务的准确率从 0.20 提高到 0.53,代码生成任务则从 0.13 上升至 0.41,充分体现了 ROLL 在特定任务上的有效性与准确性。
图 4a 展示了 Qwen3-30B-A3B-Base 模型在不同任务上的性能变化。该模型的总体准确率由 0.27 提升至 0.62,提升了约 2.3 倍。尽管 Qwen3-30B-A3B-Base 采用了 Mixture-of-Experts 架构,在训练过程中表现出更大的波动性,但其整体趋势依然明显上升,并最终达到了更优的性能表现。
两个组实验都是多任务混合训练,模型在整个训练过程中均展现出稳定且持续的性能提升,未出现模型崩溃现象,进一步验证了 ROLL 方法的鲁棒性与实用性。两组实验训练配置与数据,均可在ROLL仓库中获得。
值得一提的是,图 3b 和图 4b 展示的是在内源200B+ MOE架构模型上的训练score 曲线。图 3b 训练曲线 crash 的原因源自于算法设置、数据分布等,不过利益于ROLL高效的检查点和恢复机制,能及时地针对不合理训练设置导致的crash进行中断和恢复。图4 b展示了在生产训练设置下,内源200B+ MOE模型 score 稳定上升的过程。
另外,我们还在ROLL中开放了多模态vl模型的训练pipeline,图4 c 展示了Qwen2.5-VL-7B-Instruct模型在leonardPKU/GEOQA_R1V_Train_8K数据集上的训练曲线,可见score持续上涨,具体设置参见ROLL仓库qwen2.5-vl-7B-math配置。
https://github.com/alibaba/ROLL/tree/main/examples/qwen2.5-vl-7B-math
为了验证agentic pipeline在不同任务场景下的适应性与性能表现,我们选择了三个具有代表性的环境:Sokoban(推箱子)、FrozenLake(冰湖)以及 WebShop(模拟在线购物)。这些环境分别代表了离散动作控制、不确定状态转移和复杂自然语言交互等典型挑战。
Sokoban 环境:经典解谜任务中的智能体能力提升
在 Sokoban 环境中,我们设计了三种不同复杂度的变体,包括 6×6 网格的 SimpleSokoban、8×8 网格的 LargerSokoban,以及使用不同符号表示元素的 SokobanDifferentGridVocab。智能体通过上、下、左、右四个方向移动来推动箱子至目标位置。训练方面,我们基于 Qwen2.5-0.5B-Instruct 模型,在 8 块 GPU 上进行分布式训练,采用 Rollout batch size 为 1024,并结合 PPO loss 与 REINFORCE returns 进行策略优化。为了提高训练稳定性,我们引入 advantage clipping(10.0)和 reward clipping(20),并加入格式惩罚项(-0.001)以规范动作输出。
实验结果显示,模型在 SimpleSokoban 环境中取得了显著进步:训练成功率从 16.8% 提升至 26.0%,验证集成功率达到 35.2%,有效动作比例从 43.6% 增加到 73.4%。此外,我们将在SimpleSokoban上训练的模型,直接在 FrozenLake 环境中应用也表现出良好的泛化能力,验证了 ROLL 训练框架的鲁棒性。
FrozenLake 环境:不确定状态下的决策优化
FrozenLake 是一个具有挑战性的导航任务,智能体需在冰面上避开陷阱,最终抵达终点。由于“滑冰”机制的存在,智能体的每一步都可能随机滑动,增加了任务的不确定性。本实验沿用 Sokoban 的相同模型与训练配置,保持一致性以方便对比分析。
如图 6 所示,模型在训练过程中展现出稳定的性能提升趋势:训练成功率从 16.8% 提高到 26.0%,提升幅度达 55%;有效动作比例从 69.1% 上升至 88.8%,表明智能体逐步掌握了更高质量的动作策略。验证集上的成功率也从 12.9% 提升至 23.8%。更令人印象深刻的是,该模型在未见过的 Sokoban 验证环境中也能取得 23.8% 的成功率,显示出良好的跨环境迁移能力。
WebShop 环境:自然语言驱动的复杂交互任务
WebShop 是一个模拟在线购物的任务环境,要求智能体根据自然语言指令完成搜索、选择商品、查看详细信息并下单等操作。每个轨迹最多包含 50 步,对模型的上下文理解能力和任务执行效率提出了较高要求。为此,我们采用了支持长上下文交互的 Qwen-2.5-7B-Instruct 模型,设置序列长度为 8192 tokens,并保留 REINFORCE 算法与相同的剪切参数。同时,我们将格式惩罚项加强至 -0.05,进一步鼓励生成高质量响应。
实验结果表明,模型在 WebShop 环境中表现出色:任务成功率从 37% 大幅提升至超过 85%,平均每回合的操作数从 7 次降至 4 次,说明 LLM 学会了更高效地完成任务。整体来看,LLM 在此环境中展现出了强大的任务理解和操作效率,具备应对真实世界复杂交互场景的能力。

Figure 7 算法抽象 WorkFlow
ROLL 框架以模块化与灵活性为核心设计理念,通过一系列创新机制,实现了对大规模语言模型(LLM)在强化学习训练流程中的高效管理与性能优化。
Worker 抽象机制:构建灵活的 RL pipeline基础
为了支持多样化的强化学习任务,ROLL 将训练流程抽象为多个可插拔的 Worker 组件:
Actor Worker:可配置为 Actor 或 Reference实例,用于支持policy model 生成与ref policy对比,以及policy model 训练。
Critic Worker(可选):根据算法需求决定是否启用,用于状态价值估计。
Reward Worker:集成多种奖励计算方式,包括规则验证、代码沙箱执行和基于 LLM 的评判系统(LLM as Judge),满足不同场景下的奖励建模需求。
Environment Worker:提供丰富的环境接口,确保 LLM 能够与各类任务环境进行多轮对话交互,实现复杂行为模拟。
这种 Worker 抽象机制不仅提高了系统的扩展性,也增强了对不同训练算法的支持能力。
Single Controller Pipleline:统一控制强化学习训练流程
我们借鉴了 HybridFlow 的混合编程模型理念,采用统一控制视角,协调各 Worker 的运行时行为,实现训练流程的简化与高效管理。
Single Controller 的设计显著降低了系统复杂度,提升了开发效率与部署灵活性,使用户能够专注于算法设计本身,而非底层调度逻辑。
样本级 Rollout 生命周期控制:提升资源利用率的关键设计
传统的大语言模型强化学习系统通常采用批量处理提示样本的方式以提高吞吐量。然而,由于 LLM 生成过程存在“长尾问题”,即部分样本耗时远高于平均值,导致推理节点间资源利用率不均,影响整体训练效率,在动态过滤场景下,批量处理样本的方式对效率损害更加严重。
为此,ROLL 引入了 样本级的 Rollout 生命周期管理机制,通过以下关键设计显著提升了系统的动态采样效率和资源利用率:
异步奖励计算:解耦 LLM 响应生成与奖励计算之间的同步依赖,打破同步计算中的等待瓶颈;
请求动态添加:基于实时负载状态,灵活地将新提示样本分发到空闲推理节点;
请求提前终止:在达到有效样本数量后,及时中止冗余推理流程,减少无效计算开销。
此外,系统会对训练样本进行过采样,并从中筛选出具有梯度信息的有效中间状态样本(剔除准确率为 0 或 1 的样本),从而进一步提升训练质量与收敛效率。这种基于样本的动态采样策略,是 ROLL 实现高效强化学习训练的核心机制之一。
奖励与环境的样本级管理:提升系统吞吐与响应速度
ROLL 在奖励计算和环境交互方面也引入了样本级别的精细管理机制:用户可根据负载需要部署多个Reward Worker和Environment Worker,并行处理计算请求;支持多种类型的 Reward Worker 同时运行,包括规则验证、沙箱执行和 LLM-As-Judge;通过样本级控制灵活路由样本,实现异步奖励计算和并行环境交互,避免性能瓶颈。
值得一提的是,随着Agentic RL的兴起,ROLL配备了以下功能,以实现可扩展的Agentic RL训练:
可扩展的多轮agent-env交互:受RAGEN启发,支持agent与env之间的多轮交互,可扩展到长周期任务。
样本级可扩展环境:可以方便、灵活地进行env scaling,用户可灵活扩展env,采样足够的训练轨迹,实现高吞吐量的rollout。
异步并行的agent-env交互:通过样本级环境管理,env粒度上执行env step和actor geneate。通过env scaling实现并行环境执行,减少GPU空闲时间,最大化资源利用率。
在算法抽象之上,ROLL 构建了一套高度模块化、可扩展的分布式执行架构,支持多种先进 LLM 推理与训练引擎的无缝集成,适用于从单机部署到大规模 GPU 集群的多样化场景。
ROLL 支持无缝切换多个先进的 LLM 执行引擎,包括 DeepSpeed、Megatron、vLLM 和 SGLang,并为每个引擎扩展了高效的GPU offload/reload 实现,达到卓越的适应性和扩展性。这种集成既能充分发挥大规模 GPU 集群的并行计算优势,支持高性能的强化学习优化,也能在资源受限环境下保持高效的训练与推理能力。
Parallel Worker:资源持有的基本单元
Parallel Strategy:统一管理训练推理后端
训练阶段 整合 MegatronCore 和 DeepSpeed 框架,构建包含数据并行 (DP)、流水线并行 (PP)、张量并行 (TP)、上下文并行 (CP) 和专家并行 (EP) 的先进 5D 并行架构。
结合 ZeRO2/ZeRO3/ZeRO-offload 等优化方案以及梯度重算(gradient checkpointing)和模型卸载(offloading)策略,有效降低 GPU 显存开销,使得资源受限设备也能高效运行。
推理与生成阶段 整合 vLLM 和 SGLang 技术,实现 TP、EP 和 PP 等并行策略的无缝衔接,进一步提升性能表现。
在 ROLL 框架中,Rollout Scheduler 是实现样本级生命周期管理的关键组件。它提供了一种精细化的调度机制,能够精准管理每个请求的完整生命周期,而非仅限于batch级别的粗粒度控制。
该调度器具备以下核心能力:
实时感知资源状态:根据当前各推理实例的负载和响应进度,智能决策何时添加新任务或终止冗余任务;
支持异步执行流:通过异步奖励计算和任务并行处理,最大化硬件资源的利用率;
灵活的任务路由:结合样本优先级和资源可用性,动态分配提示样本到最优的推理节点。
这些能力使得 Rollout Scheduler 成为 ROLL 高效执行强化学习训练的重要支撑,尤其是在大规模分布式环境中,其调度灵活性和资源敏感性显著优于传统的批量处理方式。样本级的灵活调度能力对动态过滤场景更是尤为重要。
AutoDeviceMapping:灵活的资源管理体系
AutoDeviceMapping 整合了所需的 CPU 和 GPU 资源,ROLL实现的ResourceManager能够将资源精准分配给相应的worker和 scheduler,扩展了ray对GPU的管理能力,构建起一个灵活高效的资源调度体系。
相比传统的 RLHF 训练框架(如 OpenRLHF 和 NeMo),ROLL 引入了 用户自定义设备映射(User-defined Device Mapping)机制,允许来自不同训练阶段的 LLM 共享同一计算设备。
这种设计不仅提升了硬件资源的利用效率,也为用户提供了更大的部署自由度,使其能够根据具体需求和硬件条件自主规划模型在设备间的分配方式,提供GPU时分复用及独立部署能力。
github仓库:https://github.com/alibaba/ROLL
ROLL文档:https://alibaba.github.io/ROLL/docs/English/QuickStart/config_guide
Step 1
gitclonehttps://github.com/alibaba/ROLL.gitcdROLL
Step 2
#cdROLL确保pwd是在ROLL目录下#run其他job执行对应的命令即可#ROLL按目录管理实验配置,可自由发挥#直接运行examples配置,需要单机8卡GPU配置shexamples/qwen2.5-0.5B-agentic_ds/run_agentic_pipeline_frozen_lake.sh
sh执行后,便可启动训练,更多细节可以阅读ROLL的文档(持续完善中)。
quick start以后,便能基于ROLL提供的examples 配置和数据运行起rlvr pipeline和agentic pipeline。后续使用会涉及到各种自定义操作,如pipeline、reward、业务env和多轮交互。
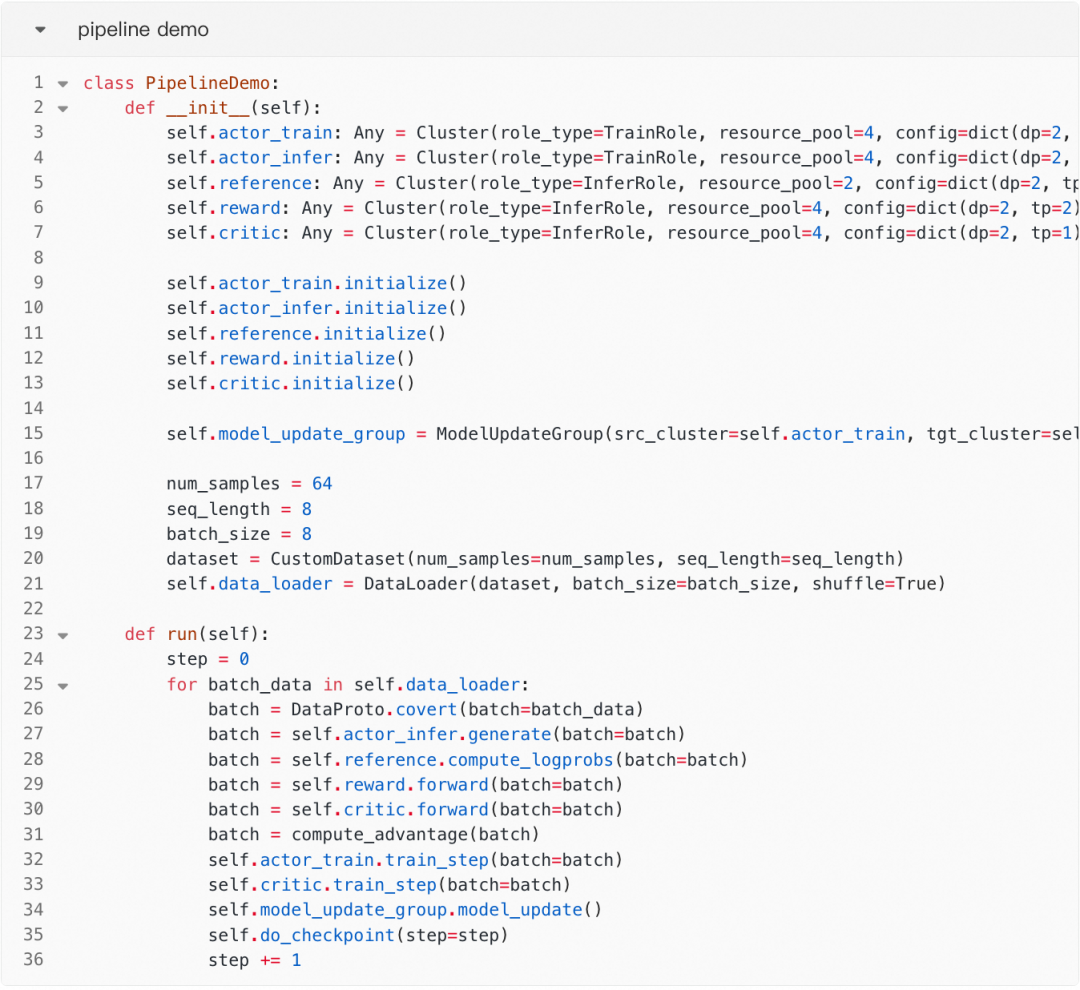
pipeline描述RL计算流,编排各个角色的计算流程,是算法同学直接DIY的地方,包括各模型的分布式计算调用、数据处理、reward处理、adv计算等等。
这一设计使得算法同学能够专注于业务逻辑本身,而不必关心底层的分布式执行细节。
开箱即用与可扩展性:我们提供了 rlvr_pipeline 和 agentic_pipeline 作为标准模板,算法同学可根据具体任务需求进行扩展或自定义实现。
在实际业务场景中,Reward 的计算逻辑往往是最重要的可定制部分之一。ROLL已经内置了多种常用的奖励计算方式,方便用户快速构建和部署强化学习训练流程。
这些 Reward 实现可以直接在 rlvr_pipeline 中使用,并支持多任务联合训练(multi-task training)。
如果你的业务有特殊需求,也可以根据自己的逻辑自定义 Reward 实现。ROLL 提供了清晰的接口规范和模块化设计,使得扩展新的 Reward 类型变得简单高效。用户只需继承基础类并实现相关方法即可,无需关心底层调度和分布式细节。

在强化学习中,Environment 是 agent 与env交互的核心实现。ROLL 提供了高度灵活的 Environment 抽象机制,支持用户根据业务需求快速构建和扩展自定义环境。
这种设计使得 ROLL 不仅适用于标准任务,也能够轻松应对复杂、定制化的业务场景。
致谢
ROLL 是淘天和爱橙紧密合作的产出,RL框架研发、迭代、应用都充满了挑战,迎难而上的旅程缺少不了项目组的伙伴们的团结,更缺少不了算法同学们的支持和陪伴。
另外,特别致敬开源的相关工作:
RAGEN:Training Agents by Reinforcing Reasoning:https://ragen-ai.github.io/:https://github.com/OpenRLHF/OpenRLHF
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
PAI-ChatLearn :灵活易用、大规模 RLHF 高效训练框架(阿里云最新实践)
TRL - Transformer Reinforcement Learning:https://github.com/huggingface/trl
NVIDIA NeMo-Aligner:https://github.com/NVIDIA/NeMo-Aligner
DeepSpeed Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales:https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-chat
最后
希望ROLL能给大家在学术研究、业务使用与前沿探索上带来收益!
大家一起ROLL起来吧!!!
ROLL!!










