|
上下文工程:智能体系统的认知优化引擎文/智能系统架构观察者 当工业级AI应用突破玩具原型阶段,决定智能体效能的关键已从指令设计转向上下文装配——这便是上下文工程的战略价值。
一、概念定义:超越提示工程的新范式核心差异对比| 维度 | 提示工程 (Prompt Engineering) | 上下文工程 (Context Engineering) |
|---|
| 焦点对象 | | | | 信息源 | | | | 核心挑战 | | | | 典型工具 | | |
技术本质: 正如Andrey Karpathy所言:工业级LLM应用的核心在于将有限上下文窗口转化为高价值信息矩阵的精密装配过程。
二、上下文构成的九大要素 关键创新点: - 全局状态管理:LlamaIndex的
Context对象实现跨步骤数据共享 - 输出侧:表格数据节省Token消耗(比文本节省40%空间)
三、四大核心技术策略1. 智能源选择机制# 多知识库路由示例
@tool
defselect_knowledge_base(query: str)-> str:
"""根据问题语义选择知识库"""
if"财务"inquery:
returnsearch_finance_db(query)
elif"技术"inquery:
returnsearch_tech_docs(query)
决策逻辑:工具描述本身构成初始上下文,引导智能体资源选择 2. 上下文压缩技术3. 记忆系统设计架构# LlamaIndex记忆模块配置
memory = MultiMemoryBlock(
blocks=[
VectorMemoryBlock(vector_store), # 向量记忆
FactMemoryBlock(key_facts=["用户偏好"]), # 关键事实存储
StaticMemoryBlock(policy="退货政策V3") # 静态规则
]
)
4. 工作流引擎优化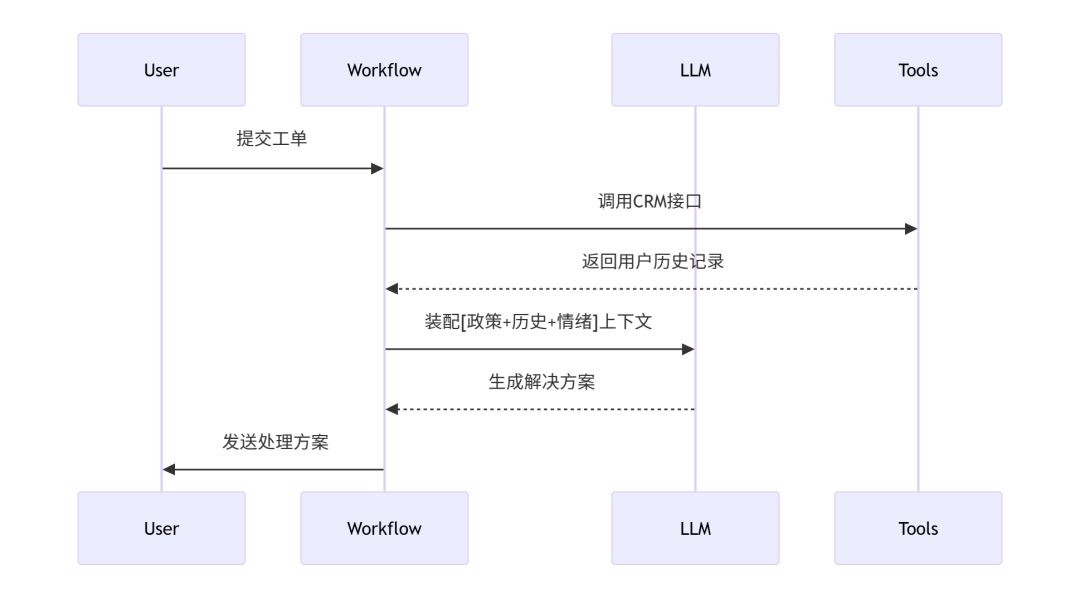 技术优势: - 错误处理链路:自动重试 → 人工接管 → 日志分析
四、工程实践案例:客户支持系统上下文装配流程defbuild_support_context(user_query: str):
# 1. 获取基础上下文
context = get_base_context()
# 2. 动态添加资源
context += memory.retrieve(user_id) # 长期记忆
context += crm.get_case_history(user_id) # 历史工单
context += policy_db.search("退货条款") # 政策文件
# 3. 空间压缩
iflen(context) >8000:
context = summarize(context, ratio=0.3)
returncontext
性能对比数据
五、未来挑战与应对1. 上下文窗口悖论当Claude 3支持200K token时,实验显示: - 信息密度下降60% → 推理准确率降低34%
解决方案:分层加载策略(核心数据+按需扩展)
2. 冷启动优化方案3. 多模态上下文融合# 多模态上下文处理
defprocess_multimodal(context):
text_ctx = text_processor(context.text)
image_ctx = vision_model(context.images)
table_ctx = tabular_parser(context.tables)
returnfuse_modalities([text_ctx, image_ctx, table_ctx])
六、结语:从工具到架构的范式升级当GPT-5突破百万级上下文,信息蒸馏能力将成为核心竞争力。上下文工程本质是:
行动指南: 1.立即体验:
-LlamaCloud免费版(10K文档)搭建带记忆客服系统
2.技术验证:
-Kaggle测试TextRank vs LLM摘要的压缩效率
3.关注前沿:
-神经符号系统(Nero-Symbolic)的上下文融合进展
-上下文感知计算国际会议(ICCAC'25)
技术迭代从不等待观望者:当同行还在调优提示词时,领先者已在构建认知引擎的底层架构。
(本文代码基于LlamaIndex 1.2+,测试环境:Python 3.10, RTX 4090)
| 









