ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">OpenAI 发布的 GPT-OSS 是自六年前 GPT-2 之后,其最主要的开源 LLM 发布。ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">过去这些年里,LLM 的能力发生了显著提升。ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">能力跃迁而言,GPT-OSS 本身未必明显超越已有的开源强模型(例如 DeepSeek、Qwen、Kimi 等),但它为我们回顾这段时间 LLM 如何演进提供了很好的契机。ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;display: table;padding: 0.3em 1em;color: rgb(255, 255, 255);background: rgb(15, 76, 129);border-radius: 8px;box-shadow: rgba(0, 0, 0, 0.1) 0px 4px 6px;">与以往GPT 开源模型的区别ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">GPT-OSS 与以往模型相似:它仍然是逐次生成 token 的自回归 Transformer。ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">到 2025 年中期,LLM 的主要差别在于它们所生成的 token 可以用于解决更复杂的问题,主要体现在以下几方面:ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;color: rgb(63, 63, 63);" class="list-paddingleft-1">ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">•ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: inherit;color: rgb(15, 76, 129);">使用工具下图展示了主要的架构特征——这些并不是对现有优秀开源模型的重大颠覆。与 GPT-2 最大的架构差别是, GPT-OSS 采用了MoE 模型结构。 GPT-OSS 的 Transformer 模块在下图中呈现为如下形式: 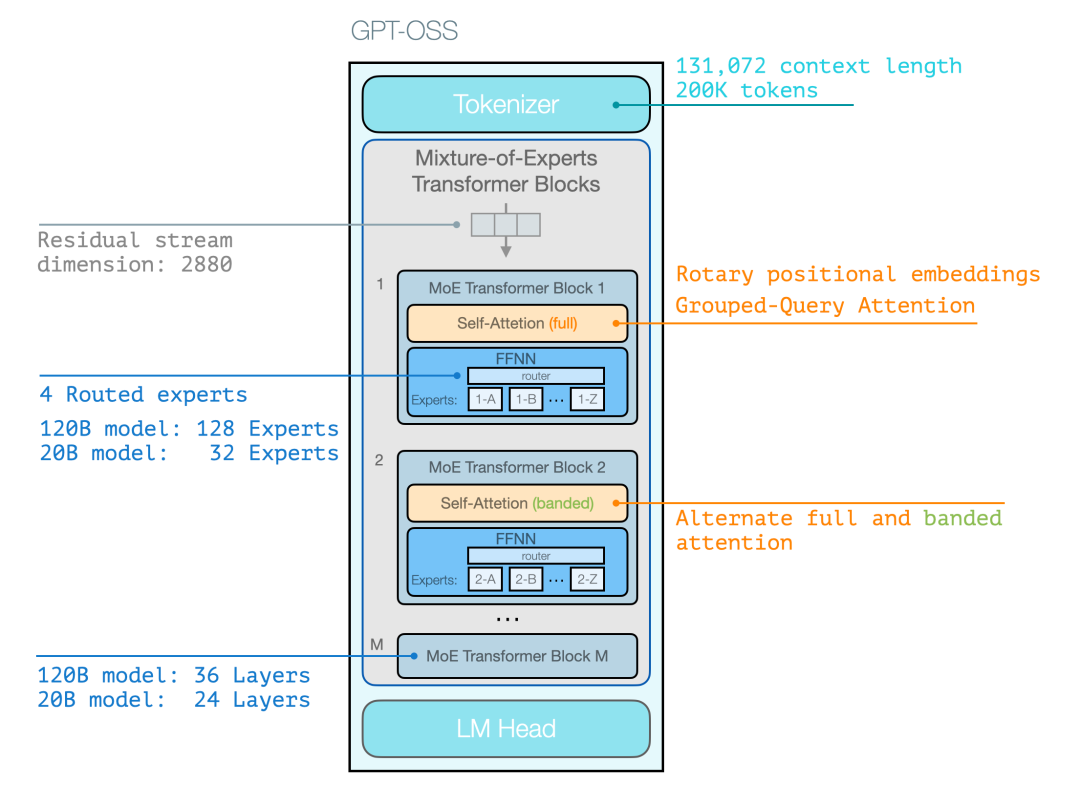
注意:这些架构细节本身并不特别新颖,通常与最新的开源的 SoTA 模型相近。 
消息格式化对更多用户来说,模型在推理与工具调用时的行为细节与消息格式,比架构细节更为重要。 下图可以看到模型输入与输出的形态。 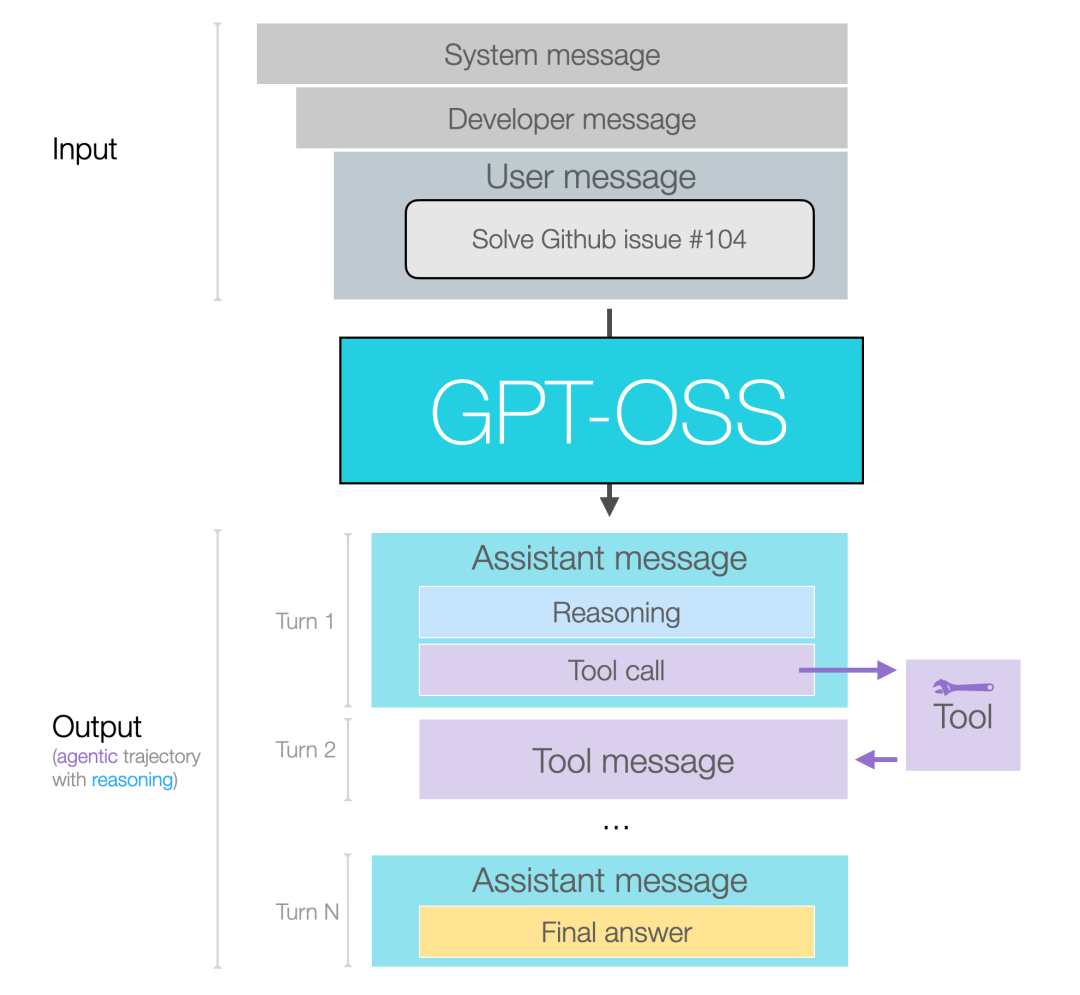
1-消息与输出通道我们按三类主要的开源 LLM 使用者来分解说明: 1.LLM 应用的终端用户(End-users of an LLM app) 示例:ChatGPT 应用的用户。 这些用户主要关注自己发送的用户消息和最终看到的答案。在某些应用中,他们也可能看到部分中间推理痕迹。 2. LLM 应用的构建者(Builders of LLM apps) 示例:Cursor 或 Manus。 输入消息:这类构建者可以自定义系统消息与开发者消息——用以定义模型的预期行为与指令、所选的安全策略、推理深度,以及模型可用工具的定义。他们还需要在用户消息中做大量的提示工程(prompt engineering)与上下文管理。 输出消息:构建者可以选择是否向用户展示推理痕迹;他们也会定义工具、并设定模型应执行多少推理。 3. 模型的后期训练团队(Post-trainers of LLMs) 对模型做微调(fine-tune)的高级用户需要与所有类型的消息交互,并将数据按正确的形态格式化,包含用于推理、工具调用与响应的数据格式。 后两类(即 LLM 应用构建者与后期训练者)会从理解 assistant messages 的通道概念中获益。该概念在 OpenAI 的 Harmony 代码仓库中有实现。 2-消息通道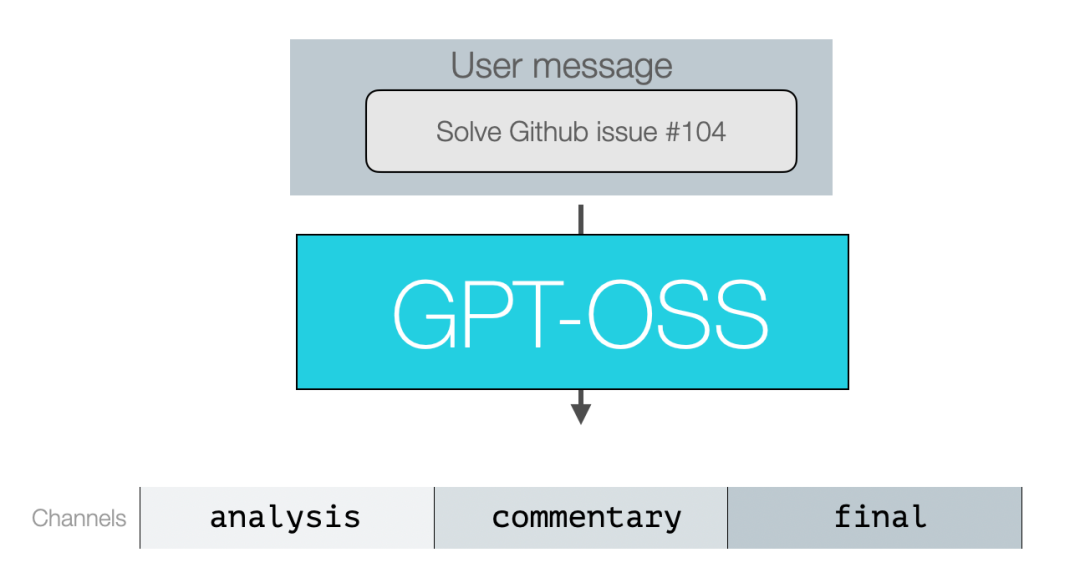
模型的所有输出都属于 assistant messages,模型会把这些输出归类到不同的“通道”以指示消息类型: - •Commentary:用于功能性调用(以及大多数工具调用)
假设我们给模型一个需要推理并调用若干工具的提示,下图展示了一段对话,其中同时使用了这三种消息类型。 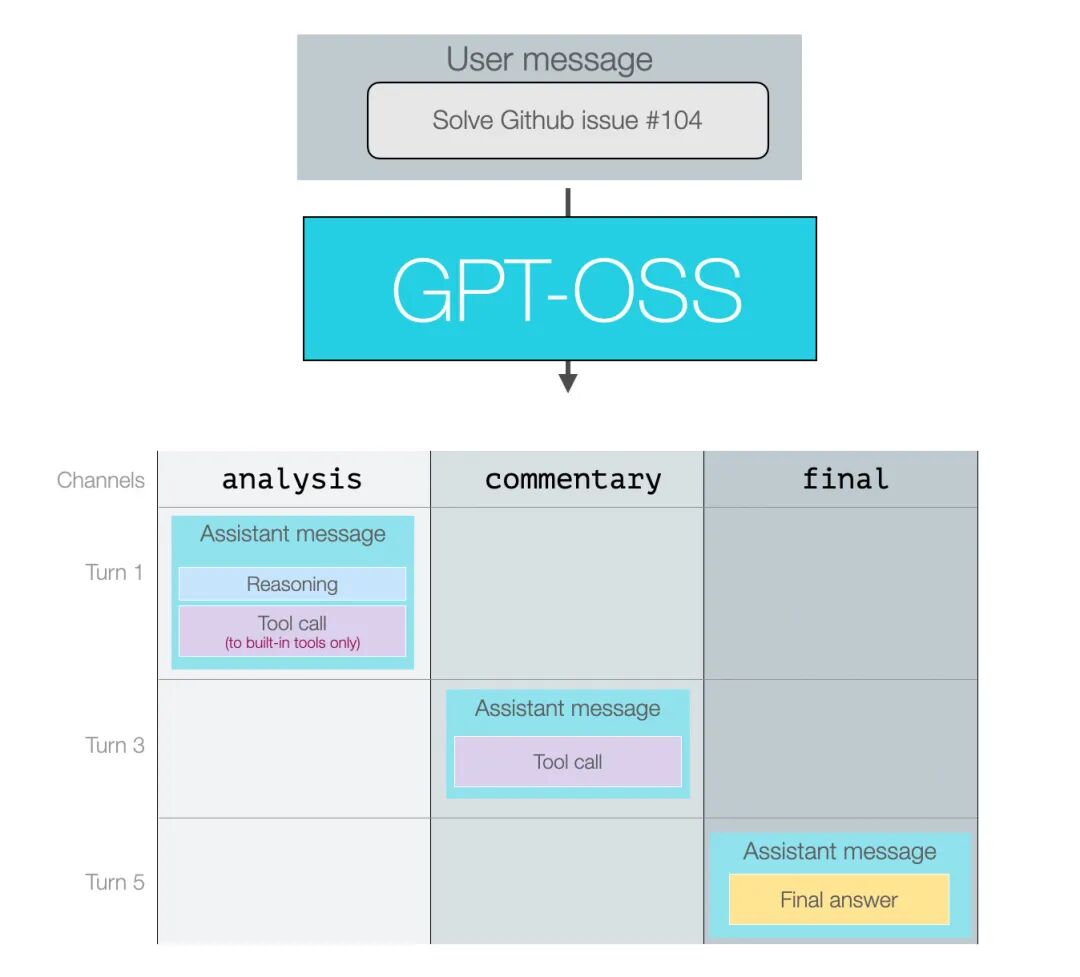
之所以把它们标为回合 1、3、5,是因为第 2 与第 4 回合分别是那些工具调用的返回。最终答案就是终端用户会看到的内容。 3-推理(Reasoning)推理有权衡,进阶用户在使用时需要做出权衡决策。一方面,更多的推理会给模型更多时间和计算资源来思考问题,从而帮助其解决更难的问题;但另一方面,这也会带来延迟和计算成本。正因为如此,出现了“擅长深度推理的 LLM”与“非推理型 LLM”两类模型——它们各自最适合处理不同类型的问题。 一种折衷的做法是使用按“推理预算”(reasoning budget)响应的推理模型。GPT-OSS 就属于这一类: 
它允许在系统消息中设置推理模式(低 / 中 / 高)。模型卡中的图 3 展示了这对基准分数的影响,以及推理痕迹中包含多少 token 的变化。 我们可以把这与 Qwen3 的推理模式对比:Qwen3 的模式是二元的——思考 / 非思考(thinking / non-thinking)。在其“思考”模式下,它确实提供了一种在超过某个 token 阈值后停止继续“思考”的方法,并报告了这如何影响各类推理基准的得分。 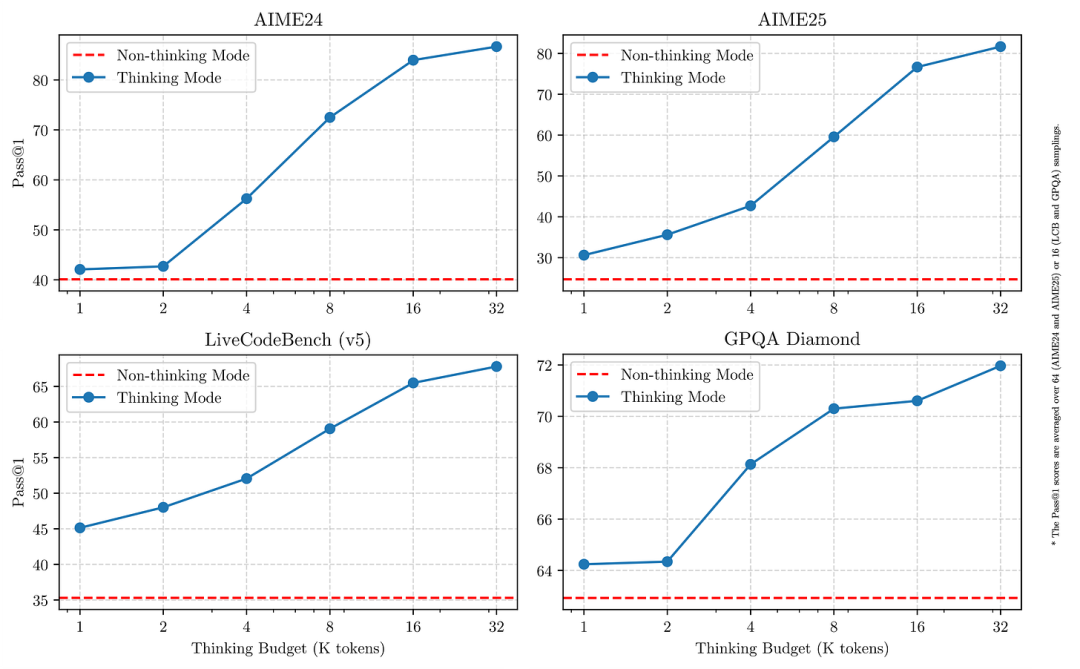
推理模式(低 / 中 / 高)展示推理模式差异的一个好办法是拿一个难题来测试。从 AIME25 数据集中选了一个题目,用 120B 规模的模型在三种推理模式下分别测试。 
该题的正确答案为 104。结果显示中等(medium)和高(high)推理模式都答对了。但高推理模式为了得到该答案,耗费了大约两倍的计算/生成时间。 这强调了前面提到的:为你的用例选择合适推理模式非常重要: - • 要执行具代理性的任务(Agentic tasks)吗?如果任务轨迹可能跨越大量步骤,那么 high(甚至 medium)推理模式可能太慢。
- • 实时与离线——要考虑哪些任务可以离线完成,在那种场景下用户不会实时等待结果。
一个例子是搜索引擎:因为在查询时间之前已经做了大量的处理与系统设计准备,查询时可以得到非常快速的响应。
分词器(Tokenizer)该分词器与 GPT-4 的分词器相似,但感觉略微更高效——尤其是在处理非英语 token 时更为节省。例如可以注意到 emoji 与中文字符各自被标为两个 token 而不是三个,阿拉伯文的若干片段被合并为单个 token 而非按字母拆开。 尽管在这方面分词器可能更优,但模型的大部分训练数据仍以英语为主。 代码(以及在 Python 中用于缩进的 tab)在行为上看起来基本相同。数字的词元化也类似:三位及以内的数字通常作为单个 token,被分配为一个词元;更大的数字则会被拆分成多个 token。 
|










