兄弟们,腾讯最近开源了一个知识库系统,将大语言模型集成到了文档理解和语义检索框架,能够为结构复杂、内容异构的文档提供更加专业的检索。 今天来一起看看这个知识库系统吧,并在飞牛 NAS上部署一下玩玩。  一、介绍WeKnora(维娜拉)是一款基于大语言模型(LLM)的文档理解与语义检索框架,专为结构复杂、内容异构的文档场景而打造。 该框架采用模块化架构,融合了多模态预处理、语义向量索引、智能召回与大模型生成推理等技术,构建起高效、可控的文档问答流程。  其核心检索流程基于RAG(Retrieval - Augmented Generation)机制,能将上下文相关片段与语言模型结合,从而实现更高质量的语义回答。 二、功能特性WeKnora拥有诸多强大的功能特性,使其在文档处理领域脱颖而出: - 精准理解:支持 PDF、Word、Txt、Markdown、图片(含 OCR/Caption)等多种文档的结构化内容提取,能统一构建语义视图,即便面对图文混排与图像文字,也能准确提取内容。
 - 智能推理:借助大语言模型理解文档上下文与用户意图,支持精准问答与多轮对话,能进行复杂语义建模、指令控制与链式问答,且可配置提示词与上下文窗口。
 灵活扩展:从解析、嵌入、召回到生成的全流程都进行了解耦,便于灵活集成与定制扩展,支持自定义 embedding 模型,兼容本地部署与云端向量生成接口,也能灵活切换主流向量索引后端。 高效检索:混合了关键词、向量、知识图谱等多种检索策略,支持稠密 / 稀疏召回、知识图谱增强检索等多种方式,可自由组合召回 - 重排 - 生成流程。
 - 简单易用:提供直观的 Web 界面与标准 RESTful API,适配开发者与业务用户的使用习惯,零技术门槛即可快速上手。
- 安全可控:支持本地化与私有云部署,能满足私有化、离线部署与灵活运维的需求,确保数据完全自主可控。
三、在飞牛 NAS 上部署本文教大家怎么在飞牛 NAS 上部署,主要是通过 Docker 进行部署,理论上在其他支持 Docker 的设备上也可以部署。 首先打开飞牛的SSH 登录功能: 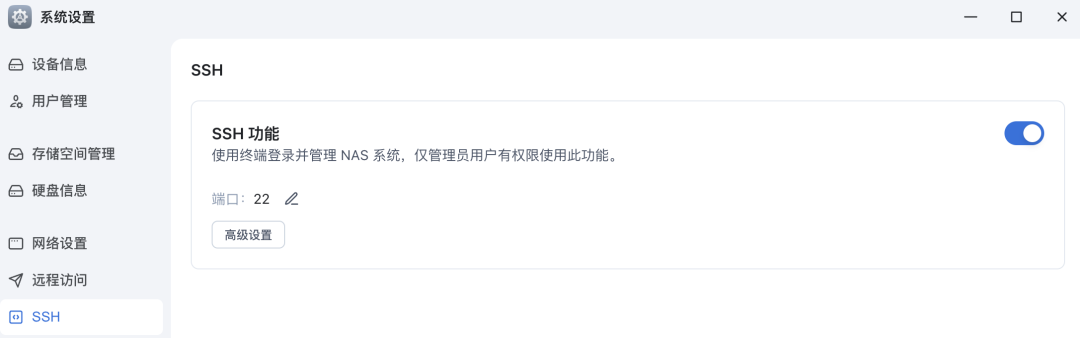 执行下面的命令切换到root账户: sudo -i
然后切换到 NAS 的指定目录(比如我这里创建了一个 docker 目录):  然后执行下面的命令 clone 项目: gitclonehttps://github.com/Tencent/WeKnora.git
然后进入到项目根目录: cdWeKnora
配置环境变量: # 复制示例配置文件
cp .env.example .env
# 编辑 .env,填入对应配置信息
# 所有变量说明详见 .env.example 注释
然后执行下面的命令启动项目: docker compose up -d
中间如果遇到postgres的端口问题,可以在.env中修改postgres的端口。 如果遇到 80 端口的问题,可以在docker-compose.yml中修改80 端口为其他的: 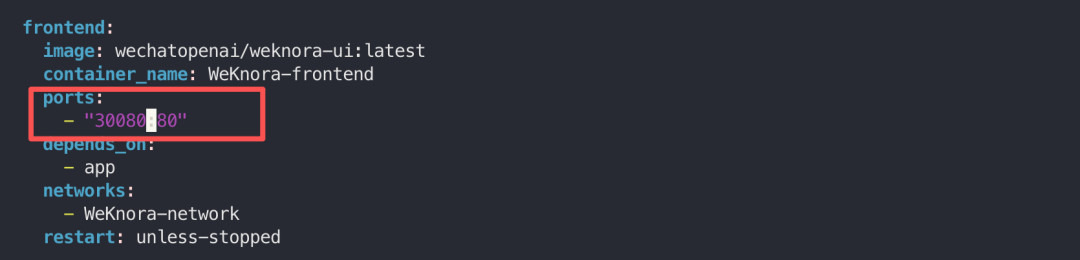 如果出现下面的内容,则表示启动成功:  与此同时,可以在飞牛 OS 的 Docker 管理界面看到运行着的项目:  至此,WeKnora就搭建好了,下面我们一起来体验一下。 四、体验在浏览器输入http://IP ort ort,其中 IP 是飞牛 OS 的 IP,Port 是上面修改的 30080 端口,比如我的是:http://192.168.66.6:30080:  在进入首页之后,首先会让设置一些信息,比如:大模型配置、Embedding 模型配置、Rerank 模型配置、多模态配置、文档分割配置。 其中大模型配置可以实用本地的 Ollama 模型,或者远程的大模型:  Embedding 模型也是,可以选择用本地或者远程的: 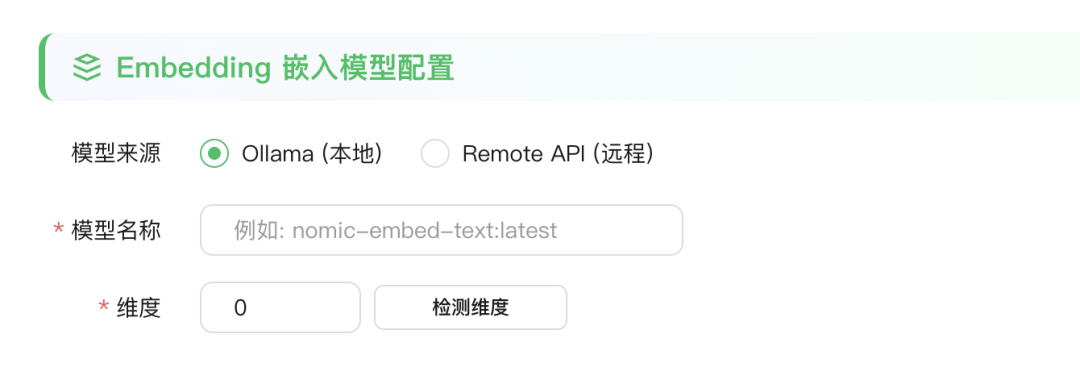 设置好之后,保存进入主页面: 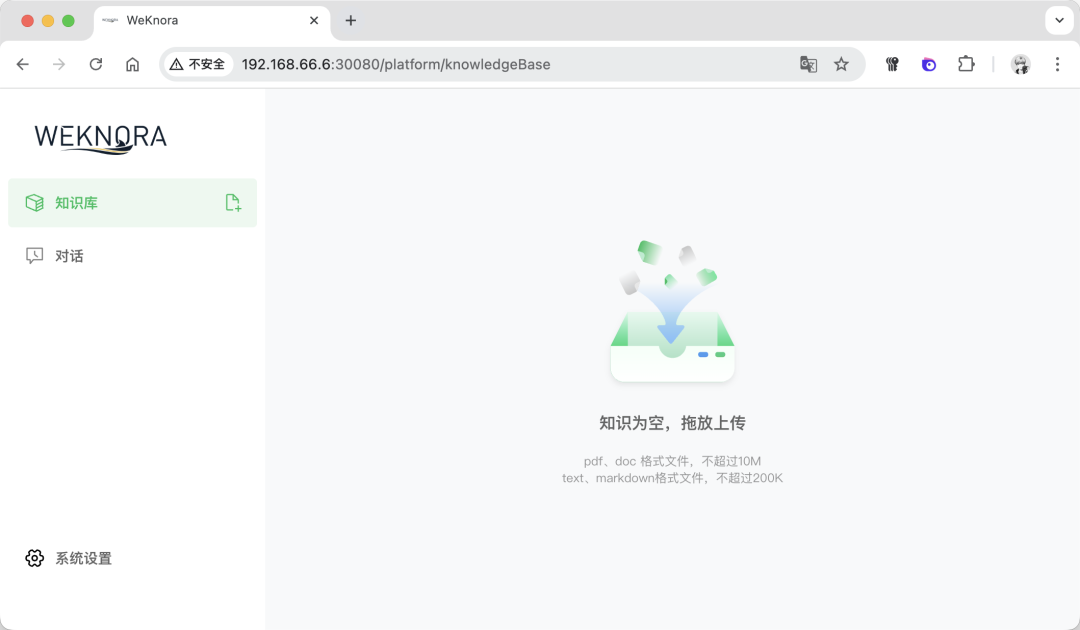 上传几个文档看看,可以看到知识库自动分析了文档的内容,并进行了总结: 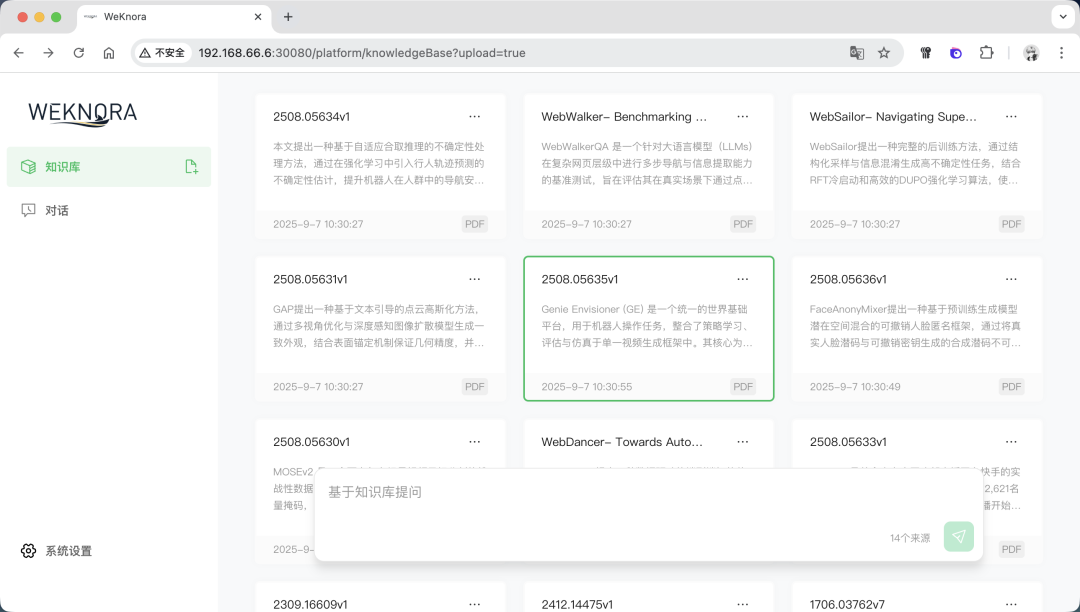 下面提问下看看:  可以看到知识库参考了一些文档内容,并进行了总结回答:  好了,今天的介绍就到这里了,大家感兴趣的话快去试试吧! 五、总结WeKnora 作为一款基于大模型的文档理解检索框架,凭借其精准的文档理解能力、智能的推理功能、灵活的扩展特性、高效的检索机制以及简单易用和安全可控等优势,在企业知识管理、科研文献分析、产品技术支持、法律合规审查、医疗知识辅助等众多场景中都能发挥重要作用。 | 









