ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 17px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: 0.544px;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;visibility: visible;">
谷歌 Gemma 3 上线刚刚过去一个月,现在又出新版本了。
该版本经过量化感知训练(Quantization-Aware Training,QAT)优化,能在保持高质量的同时显著降低内存需求。

比如经过 QAT 优化后,Gemma 3 27B 的 VRAM 占用量可以从 54GB 大幅降至 14.1GB,使其完全可以在 NVIDIA RTX 3090 等消费级 GPU 上本地运行!
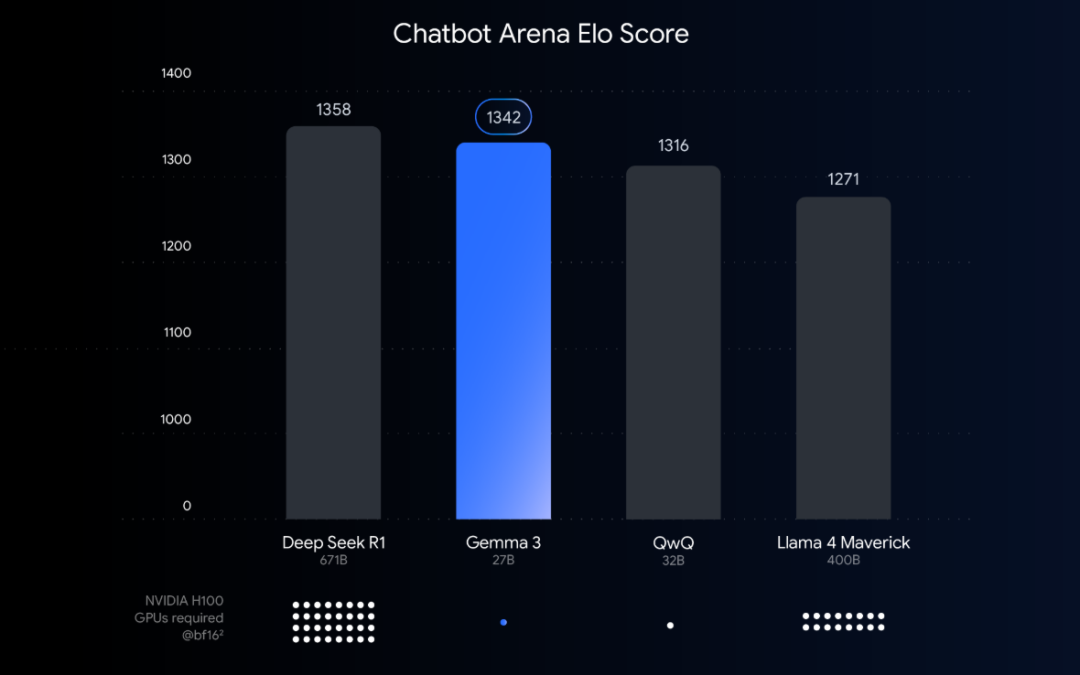
Chatbot Arena Elo 得分:更高的分数(最上面的数字)表明更大的用户偏好。点表示模型使用 BF16 数据类型运行时所需的 NVIDIA H100 GPU 预估数量。
机器之心在一台配备了 RTX 3070 的电脑上简单测试了其中的 12B 版本,可以看到虽然 Gemma 3 的 token 输出速度不够快,但整体来说还算可以接受。
基于量化感知训练的 Gemma 3
在 AI 模型中,研究者可以使用更少的位数例如 8 位(int8)甚至 4 位(int4)进行数据存储。
采用 int4 量化意味着每个数值仅用 4 bit 表示 —— 相比 BF16 格式,数据大小缩减至 1/4。
但是,这种量化方式通常会导致模型性能下降。
那谷歌是如何保持模型质量的?答案是采用 QAT。
与传统在模型训练完成后才进行量化的方式不同,QAT 将量化过程直接融入训练阶段 —— 通过在训练中模拟低精度运算,使模型在后续被量化为更小、更快的版本时,仍能保持准确率损失最小化。
具体实现上,谷歌基于未量化的 checkpoint 概率分布作为目标,进行了约 5,000 步的 QAT 训练。当量化至 Q4_0(一种常见的量化格式) 时,困惑度下降了 54%。
这样带来的好处之一是加载模型权重所需的 VRAM 大幅减少:
Gemma 3 27B:从 54 GB(BF16)降至仅 14.1 GB(int4) Gemma 3 12B:从 24 GB(BF16)缩减至仅 6.6 GB(int4) Gemma 3 4B:从 8 GB(BF16)精简至 2.6 GB(int4) Gemma 3 1B:从 2 GB(BF16)降至仅 0.5 GB(int4)
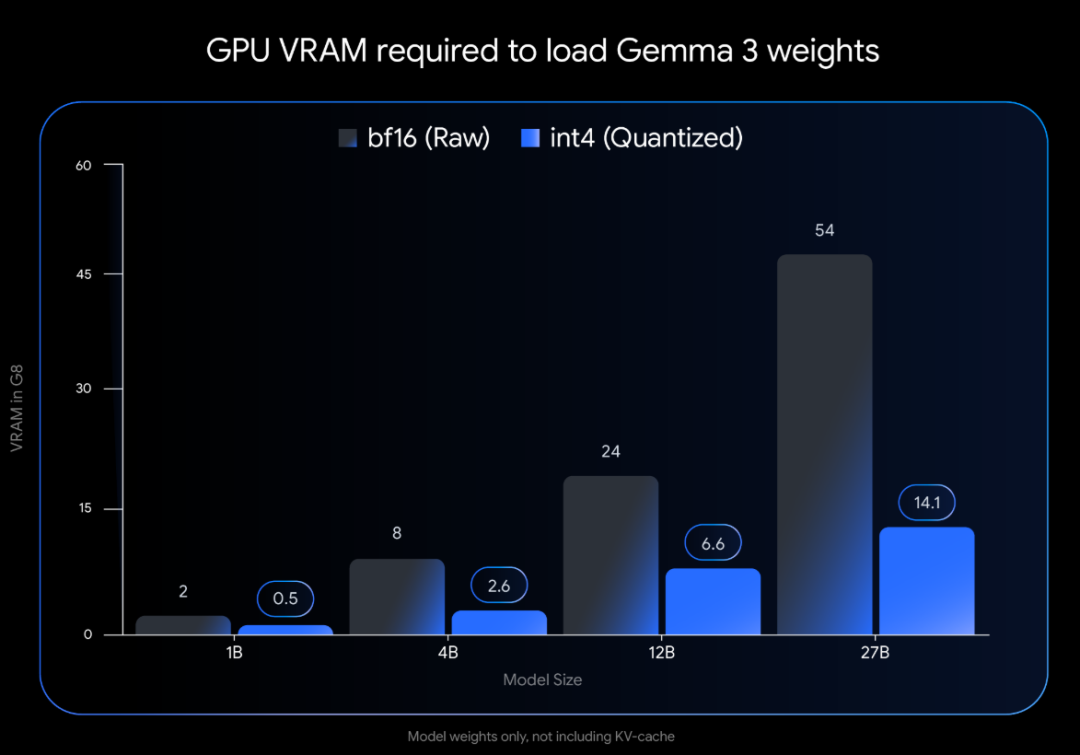
此图仅表示加载模型权重所需的 VRAM。运行该模型还需要额外的 VRAM 用于 KV 缓存,该缓存存储有关正在进行的对话的信息,并取决于上下文长度。
现在看来,用户在消费级设备上就能运行更大、更强的 Gemma 3 模型,其中:
Gemma 3 27B (int4):现在可以轻松安装在单张 NVIDIA RTX 3090(24GB VRAM)或类似显卡上,本地就能运行最大的 Gemma 3 版本; Gemma 3 12B (int4):可在 NVIDIA RTX 4060 GPU(8GB VRAM)等笔记本电脑 GPU 上高效运行,为便携式设备带来强大的 AI 功能; 更小的型号(4B、1B):为资源较为有限的系统(包括手机和烤面包机)提供更强大的可访问性。

来自 Two Minute Papers 频道的玩笑
官方 int4 和 Q4_0 非量化 QAT 模型已在 Hugging Face 和 Kaggle 上线。谷歌还与众多热门开发者工具合作,让用户无缝体验基于 QAT 的量化 checkpoint:
Ollama:从今天起,只需一个简单命令即可原生支持 Gemma 3 QAT 模型。 LM Studio:通过用户友好界面,轻松下载并在桌面上运行 Gemma 3 QAT 模型。 MLX:利用 MLX 在苹果芯片上对 Gemma 3 QAT 模型进行高效推理。 Gemma.cpp:使用专用的 C++ 实现,直接在 CPU 上进行高效推理。 llama.cpp:得益于对 GGUF 格式 QAT 模型的原生支持,可轻松集成到现有工作流程中。
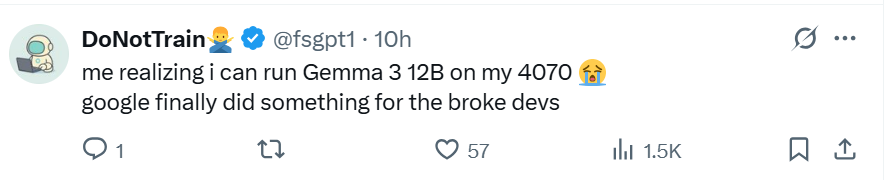
激动的网友已经无法抑制内心的喜悦:「我的 4070 就能运行 Gemma 3 12B,这次谷歌终于为即将破产的开发者做了一些事情。」
「希望谷歌朝着 1bit 量化使使劲。」

这个可以本地运行的 Gemma 3 你用了吗,效果如何,欢迎大家评论区留言。 | 









