|
本公众号主要关注NLP、CV、LLM、RAG、Agent等AI前沿技术,免费分享业界实战案例与课程,助力您全面拥抱AIGC。
 Deep Research面临的问题- 现有的 QA 数据集大多浅层,无法满足多步推理的需求。需要构建能够反映多样化用户意图和丰富交互上下文的高质量、细粒度浏览数据
- 设计能够使Agent在分布外的网络环境、复杂交互模式和长期目标下表现出鲁棒行为的可扩展和泛化训练策略
WebDancer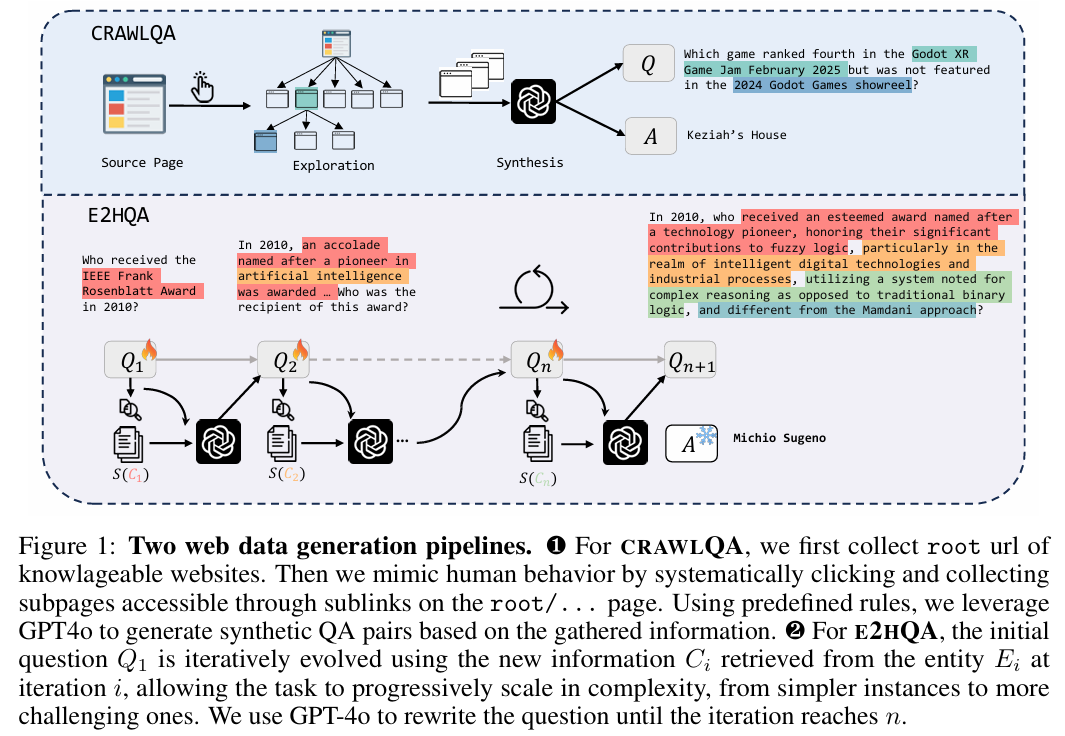 从数据和训练阶段的角度出发,提出了一个端到端的自主信息检索代理构建范式,通过四个关键阶段: - CRAWLQA:通过爬取知识性网站的网页,模仿人类浏览行为,递归访问子页面,并利用 GPT-4o 生成基于收集内容的 QA 对。
- 这种方法能够获取丰富的背景知识,为复杂问题的构建提供基础。
- E2HQA:从简单的 QA 对开始,逐步通过搜索和重写问题,增加问题的复杂性。
- 这种方法能够激励代理从简单任务逐步过渡到复杂任务,提升其推理能力。
- 基于 ReAct 框架,代理通过 Thought-Action-Observation 轮次进行交互。
- 通过拒绝采样,结合短链推理(Short-CoT)和长链推理(Long-CoT)策略,生成高质量的轨迹。
- 采用三阶段过滤框架:有效性控制、正确性验证和质量评估,确保轨迹的高质量。
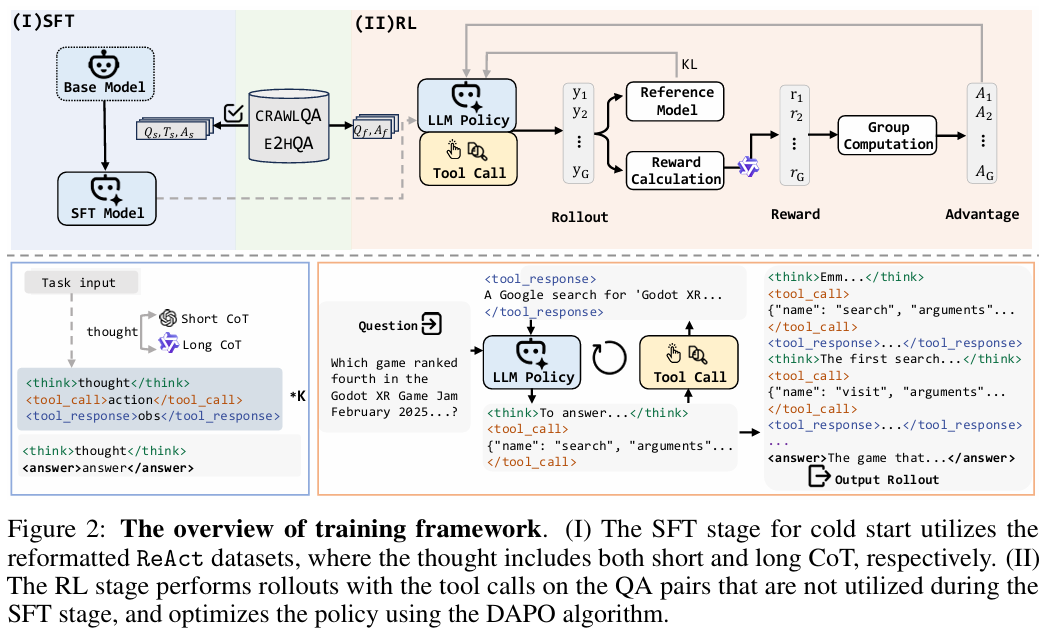 - 利用合成的轨迹数据,对代理进行微调,使其能够适应多步推理任务。
- 通过屏蔽外部反馈的损失贡献,避免学习过程中的干扰,提升性能和鲁棒性。
- 通过强化学习(RL)优化Agent的决策能力和泛化能力
- 采用 DAPO 算法,通过动态采样机制,优化代理的决策过程,提升其在真实世界网络环境中的泛化能力。
实验结果在实验中,WebDancer 在 GAIA 和 WebWalkerQA 两个基准测试中表现出色。 - 在 GAIA 的 Level 1、Level 2 和 Level 3 测试中,WebDancer 分别取得了 41.0%、30.7% 和 0% 的通过率,显著优于其他开源框架。表明 WebDancer 在处理复杂信息检索任务时具有显著优势。
 WebDancer的核心在于通过高质量数据和有效的训练方法,使代理能够在动态多变的网络环境中表现出色。 | 









