|
2025 年 8 月 5 日,OpenAI 在毫无预热的情况下,把首批“开源权重”的推理模型gpt-oss-120b和gpt-oss-20b直接扔了出来。 本以为OpenAI会掏出一个老掉牙的玩意儿,比如gpt4的开源等,没想到还挺有诚意,基本可以说位于开源第一梯队,不输给R1和K2和GLM4.5。 基本上是一套带工具调用、三段推理强度可调、专为 Agentic Workflow 设计的完整前沿方案。 1. 一句话总结:这是目前最接近 o4-mini 的开源模型
2. 技术拆解2.1 架构:经典 MoE 的“细节拉满”版- 120b:128 experts × top-4;20b:32 experts × top-4
- Gated-SwiGLU + 残差连接,激活内存砍半
- GQA(8 KV heads)+ 128 宽窗口与全密集交替
- YaRN 把 8 K 预训练长度硬拉到 131 K
- 只对 MoE weight 做 MXFP4,90 % 参数 4 bit,效果不掉点 (注意,这是整个模型牛逼的地方,当初R1搞定8bit训练就震惊了,OpenAI浓眉大眼漏了一手infra实力,果然大模型时代,infra才是胜负手)
2.2 分词器:新鲜货o200k_harmony开源了- 在 GPT-4o 的 o200k 基础上,新增 Harmony Chat 专用 token
- 总词表 201 K,中文/代码/数学 token 密度肉眼可见提高
2.3 三段式训练 | | |
|---|
| 预训练 | 数 T tokens(STEM+Code 权重高)
CBRN 过滤器提前干活 | | | 后训练 | 与 o3 同源的 CoT RL
支持 low/medium/high 三挡 | | | 工具微调 | | |
3. 一些评测效果“实测表现: - AIME 2025(with tools)97.9 %,打平 o4-mini-high
- SWE-Bench Verified 62.4 %,比 o3-mini 高 5+ 个点
- HealthBench Hard 30 %,直接把 GPT-4o 按在地上摩擦
 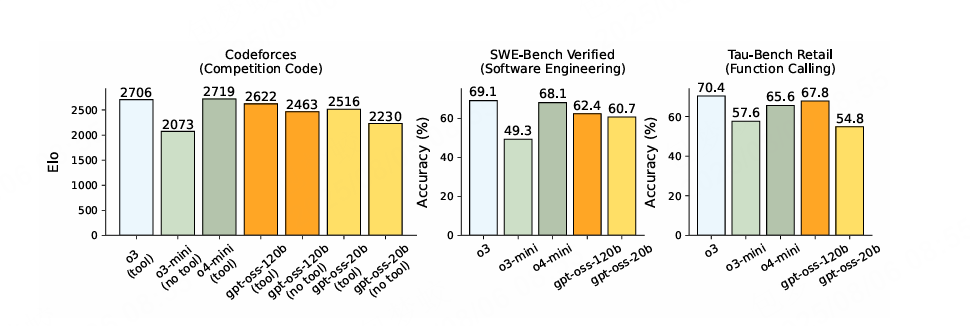 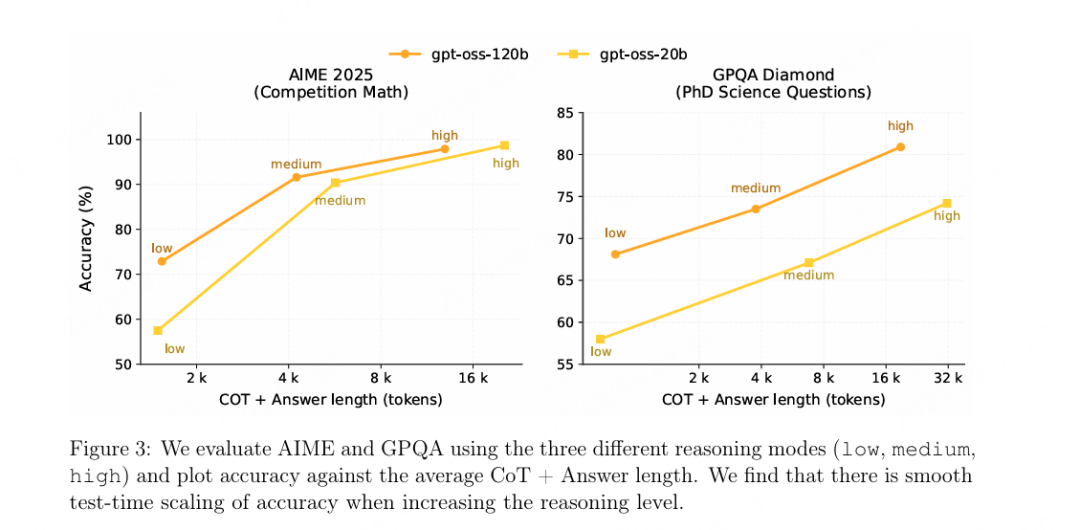 openAI把整个模型在医疗化学领域的表现作为一个核心卖点,特地评估了Heath领域。 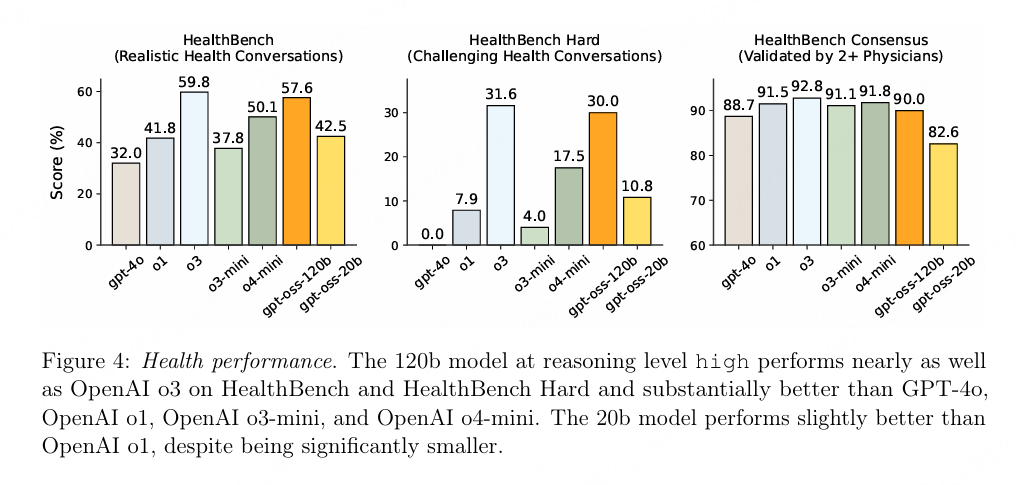 4. 快速上手:3 条命令跑起来# 1. 一键下载(已量化)
gitclonehttps://github.com/openai/gpt-oss
cdgpt-oss
pip install -r requirements.txt
# 2. 120b 单卡推理
python -m gpt_oss.cli \
--model gpt-oss-120b \
--quantize mxfp4 \
--reasoning high \
--tools browser,python
# 3. 20b 低资源模式
python -m gpt_oss.cli \
--model gpt-oss-20b \
--gpu-mem 16 \
--reasoning medium
Harmony Chat 的 JSON 模板直接照抄附录,LangChain / LlamaIndex 已连夜适配。
5. 写在最后:它到底改变了什么? | | |
|---|
| 免费拿到 o4-mini 90 % 能力 + 全套 Agent 脚手架 | 可复现的 RL + Tool 训练流水线 | 开源权重首次通过生物/网络红队 | | Apache 2.0,可商用,可微调 | CoT 无隐藏,方便做监控与对齐研究 | 给闭源厂商一次“降维打击” |
如果你正在做: gpt-oss-120b/20b 值得立刻拉分支实测。
毕竟,上一次开源圈这么热闹,还是 Llama 2 发布的时候。
“引用
[1] OpenAI. gpt-oss-120b & gpt-oss-20b Model Card, 2025-08-05
[2] 知乎问答:如何看待 OpenAI 开源 MoE 模型 gpt-oss-120b & gpt-oss-20b? | 









