今日AI资讯·阿里云:AI员工001号"通义灵码"上岗
·A800线上租赁价2元/卡时,满足90%算力用户需求
·首个千亿级MoE架构大模型Github开源
· OpenAI:ChatGPT无需注册即可用
·昆仑万维:天工SkyMusic开始邀测
·浪潮云:发布浪潮海若大模型
·支付宝:推出AI就医助理
痛点:PDF文档类型、版式有很多种,解析不准会带来很多噪声,解析内容缺失又造成语义上的丢失。 今天我们将重点探讨针对常见PDF类型的版式解析方案。引入AI技术,例如目标检测和OCR等。我们将从多个角度来研究版式解析,包括多级标题提取、长文本摘要总结、单双栏区分与重排、表格与图片提取以及比例缩放的PDF等。
常见PDF类型文本PDF:最常见的PDF类型,主要包含文本和图像。文本可以被搜索、被选择和复制。 扫描PDF:这种类型的PDF文件通常是通过扫描纸质文档生成的,通常包含的是图像,而不是可搜索或可选择的文本。然而,使用OCR(光学字符识别)技术,可以将扫描PDF转换为文本PDF。
常见版式解析方案今天主要梳理一下常见PDF类型的版式解析方案。 PDF文件可以包含文本、图形、图像和各种其他元素。在处理PDF文件时,有时需要解析PDF的版式以提取其中的信息。以下是几种常见的PDF类型版式解析方案: 文本版式解析:这种情况下,PDF文件主要包含文本内容。可以使用PDF解析库(如Python的PyPDF2、PDFMiner或Apache Tika)来提取文本内容。这种方法通常适用于版面简单、文本内容丰富的PDF文件。 图形版式解析:如果PDF文件包含大量图形和图像,可以使用PDF解析库(如Python的Pillow或报告Lab)来提取这些元素。此外,还可以使用计算机视觉库(如OpenCV)对提取的图像进行进一步处理和分析。 表格版式解析:对于包含表格的PDF文件,可以使用专门的表格提取库(如Python的Tabula-py或Camelot-py)来解析PDF中的表格数据。这些库通常可以将表格数据转换为CSV或其他结构化格式。 复合版式解析:对于包含多种元素(如文本、图像和表格)的PDF文件,可以结合使用上述方法来解析PDF版式。例如,可以先提取文本内容,然后提取图像和表格元素,最后将所有提取的数据整合在一起进行分析。
版式解析主要思路PDF的版式解析主要思路有两种:1.基于规则;2.基于AI-CV; 基于规则:根据文档的组织结构特点去"计算"每部分的样式和内容。因为pdf的类型、排版实在太多了,很难穷举这种方式很不通用。因此一般采用AI-CV的方式:目标检测和OCR AI解析策略及选型- 1、根据不同类型的PDF做特定规则处理。例如:简历、论文、财报、小说、PPT等,都可以根据排版特点做一些专有解析规则设计;
- 2、基于CPU等目标检测模型,建议用PaddlePaddle提供的,速度快;Layout parser框架,目标检测模型和OCR工具可以自由切换;
提出问题引出方案Q1:如何对一本书做摘要?换个问法:如何快速对几十万字内容做摘要?分情况讨论: - 1.文本内容中有标题或目录大纲。比如:(小说)书籍、论文等。摘要策略是把多级标题提取(PyPDF2)出来,适当做语义扩充,或者去向量库检索相关片段,最后输入LLM整合输出即可。
Q2:如何提取多级标题? 首先要明白为什么要提取标题甚至是多级标题,因为提取标题对于LLM阅读理解的重要性很大。 在文档处理时,尤其是大型复杂结构的文档时,按照字数进行分割,总会造成文本段的割裂,导致召回准确率降低;如果能精确的找到文档大纲和目录,从而按照文档的目录的大纲进行处理,则会提升更多的召回准确度。 PyPDF2:获取一级、二级等多级标题,标题所在起始页和结束页位置,以及标题所在行距离当页顶部的距离,可以精确定位。 fromPyPDF2importPdfReader
fromPyPDF2.genericimportDestination
defprocess_outlines(outlines,prefix):
fori,outlineinenumerate(outlines):
ifisinstance(outline,Destination):
start_page=pdf.get_destination_page_number(outline)
#跳过中间的子章节,直接获取下一个相同层级的章节
whilei+1<len(outlines)andisinstance(outlines[i+1],list):
i=i+1
ifi>=len(outlines)-1:
#最后一个节点,无法通过跳过中间子章节的方式获取,所以遍历所有子节点,找到最后一个子节点
last_page=outlines[-1]
whileisinstance(last_page,list):
last_page=last_page[-1]
end_page=pdf.get_destination_page_number(last_page)
else:
end_page=pdf.get_destination_page_number(outlines[i+1])
#打印起始页和结束页位置,以及标题所在行距离当页顶部的距离,可以精确定位,
print(f'{prefix}{outline.title}page=({start_page},{end_page}),top={outline.top}')
elifisinstance(outline,list):
process_outlines(outline,'|----'+prefix)
else:
print(f"Invalidoutlinesformat.outlinetypeis{type(outline)}")
if__name__=='__main__':
pdf=PdfReader('xxx.pdf')
outlines=pdf.outline
print(outlines)
#遍历大纲
process_outlines(outlines,'')
提取效果: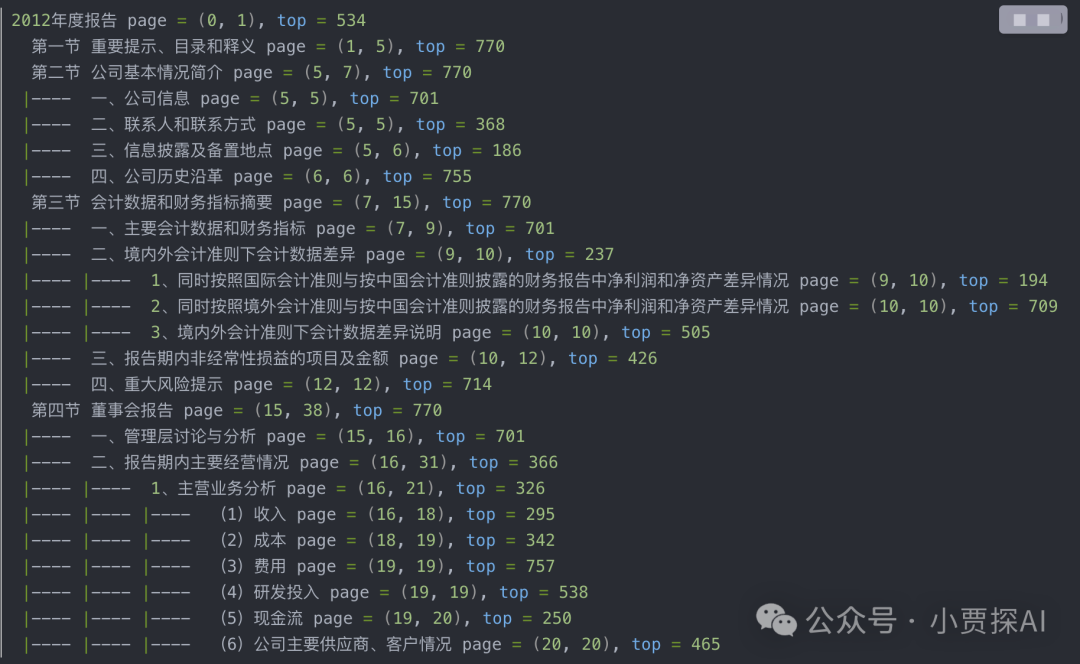 1.正如Q1问题,标题是快速做长文本摘要最核心的关键点; 2.对于一些多跳嵌套多问题,没有标题很难得到用户满意的结果。 第一步:使用工具将PDF转换为图片,开源工具:fitz,速度很快(毫秒级)。 第二步:如何在图片中识别出标题、文本、表格、图片、列表等元素。如下图:
这一步就要采用目标检测模型,可选开源工具:Layout-parser(https://github.com/Layout-Parser/layout-parser)、PaddlePaddle-ppstructure、unstructured。 OCR工具对比:Layout-parser、PaddlePaddle-ppstructure和unstructured | 工具 | 优点 | 缺点 |
|---|
| Layout-parser | 精度高、功能全面 | 速度较慢 | | PaddlePaddle-ppstructure | 模型较小、效果较好 | 功能相对单一 | | unstructured | 处理速度快 | 识别效果有限 |
##Layout-parser
###优点
-精度高:Layout-parser的最大模型(约800MB)精度非常高,能够有效地识别论文PDF中的标题和内容。
-功能全面:Layout-parser可以完成对PDF文档的解析、分割和识别等多种任务。
###缺点
-速度较慢:Layout-parser在处理大量数据时速度相对较慢,需要考虑使用GPU加速。
##PaddlePaddle-ppstructure
###优点
-模型较小:相比Layout-parser,PaddlePaddle-ppstructure的模型较小,易于部署和使用。
-效果较好:虽然模型较小,但PaddlePaddle-ppstructure的效果仍然不错,能够满足一般需求。
###缺点
-功能相对单一:PaddlePaddle-ppstructure主要针对版面分析,功能相对较少。
##unstructured
###优点
-处理速度快:unstructured在处理大量数据时速度较快。
###缺点
-识别效果有限:unstructured的fast模式效果较差,会将很多公式也识别为标题。其他模式或许可行,但需要进一步尝试。
#总结
Layout-parser在精度上有优势,但速度较慢;PaddlePaddle-ppstructure模型较小,效果较好;unstructured处理速度快,但识别效果有限(fast模式效果很差,公式识别为标题)。具体选择哪个工具,需要根据实际需求和场景进行权衡。
用上述工具都可以对标题区块提取文字。提取出一个List集合存储所有标题,然后根据标题区块的高度(即字号)判断哪些是一级、二级、...、N级标题。但是目标检测模型提取的区块并不是严格按照文字的边去切。unstructured的fast模式是按照文字的边切的,同一级标题的区块高度误差在0.001之间,因此我们只需要用unstructured(毫秒级)获取标题的高度值即可。 Q3:如何区分PDF单栏、双栏还是是三栏?怎么重新区块排序? 常用目标检测模型识别区块后并不是顺序返回,需要根据坐标重新排序。单栏PDF直接按照中心点纵坐标排序即可。双栏PDF会复杂一些,顺序如图红色箭头所示: 3.1 如何区分单、双栏PDF? 首先获取所有区块的中心点的横坐标,用这一组横坐标的极差来判断即可,双栏论文的极差远大于单栏论文,因此可以设定一个极差阈值; 3.2 双栏论文如何确定区块的先后顺序? 先找到中线,将左右栏的区块分开,中线横坐标是上述求极差的两个横坐标和的一半;区分左右栏后,对每一栏区块按照纵坐标排序即可,最后将右栏拼接到左栏之后; 3.3 三栏同双栏理论基础进行计算即可Q4:如何提取表格和图片中的数据? 目标检测和OCR。无论是layoutparser还是PaddleOCR都有识别表格和图片的目标检测模型,而表格的数据可以直接OCR导出为excel形式数据,非常方便。
- PaddlePaddle的[PP structure]效果示例:
- https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/ppstructure/table/README_ch.md
提取出表格之后,嵌入prompt,输入LLM进行问答。 Q5:如何处理跨页(跨栏)内容? 对于跨页情况,如果是一段文本被隔开,我们可以利用NSP(Next Sentence Prediction)技术来判断是否需要拼接。然而,如果是表格,我们目前的做法是强制合并,因为两个独立的表格分别占据两页的首尾部分的情况较为罕见。尽管这种方法并不完美,但仍然具有实用性。 Q6:如何处理无线端采用版式数据进行等比例缩小的版式排版PDF? 无线端的屏幕尺寸普遍较小,如果将版式数据等比例缩小后排版,整个版面中的文字、公式较小,如下图所示: 比较理想的方案是将版式数据转换成流式数据,根据不同的无线端屏幕尺寸,进行重排版。区别于版式数据中每个元素都有当前版面的坐标信息,流式数据没有坐标信息,有的是章节、栏、段落、公式和表格等结构化信息,大量的数据结构信息将最基础的文本、图片关联起来,形成结构化的文档内容,适合各种屏幕尺寸的自适应重排版。 Q7:基于AI的文档解析有什么优缺点?基于AI的文档解析具有以下优缺点: 优点: - 高准确性:AI技术可以有效识别和解析文档中的文本、图像和其他元素,提高解析的准确性。
- 高效性:AI可以快速处理大量文档,提高工作效率,节约人力资源。
- 通用性:AI-based文档解析可以应用于各种类型的文档,具有较强的适应性。
- 自动化:基于AI的文档解析可以实现自动化处理,减少人工干预,降低错误率。
缺点: - 消耗资源:AI-based文档解析需要较高的计算资源,可能需要GPU等加速设备来提高处理速度。
- 对特殊格式文档处理能力有限:对于一些特殊格式的文档,AI-based解析可能无法完全识别和解析所有元素。
- 需要持续优化和更新:随着文档格式和内容的变化,AI模型可能需要不断优化和更新以保持良好的解析效果。
- 对非结构化数据处理能力有限:AI-based文档解析主要针对结构化数据,对于非结构化数据的处理能力相对较低。
总结 今天我们将重点探讨了针对常见PDF类型的版式解析方案。通常情况下,规则解析方法可能无法充分满足需求,因此我们需要引入AI技术,例如目标检测和OCR等。我们从多个角度来研究了版式解析,包括多级标题提取、长文本摘要总结、单双栏区分与重排、表格与图片提取以及PDF比例缩放等。我们希望大家能够辩证地看待这些方法和策略。显然,底层模型的能力对上层检测和识别结果有着至关重要的影响。为了追求更好的效果,我们还可以考虑从微调CV视觉模型这一侧入手。 | 









