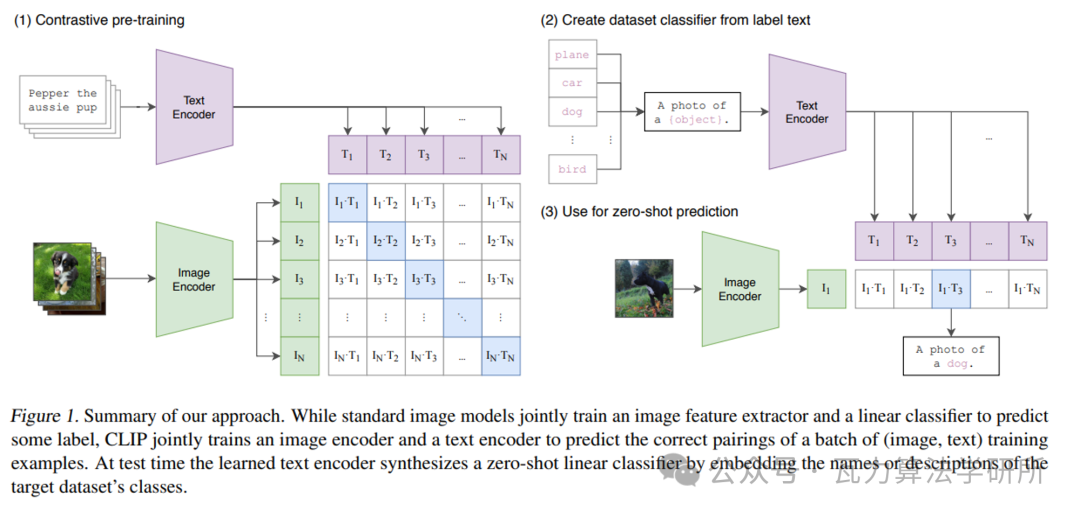
上图为CLIP模型的前向训练的过程,需要将N个标签文本和N个图片的两两组合预测出N对可能的文本-图片对的余弦相似性,即上图所示的矩阵。这里共有N个正样本,即真正匹配的文本和图片(矩阵中的对角线元素),而剩余文本-图片对为负样本,这时CLIP模型的训练目标就是最大N个正样本的余弦相似性(每个格子上对应的向量点积),同时最小化负样本的余弦相似性。
完成CLIP的训练后,输入配对的图片和标签文本,则Text Encoder和Image Encoder可以输出相似的embedding向量,计算余弦相似度就可以得到接近1的结果。同时对于不匹配的图片和标签文本,输出的embedding向量计算余弦相似度则会接近0。以下为代码实现:
# cosine similarity as logitslogit_scale = self.logit_scale.exp()logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scalelogits_per_image = logits_per_text.t()
loss = Noneif return_loss: loss = clip_loss(logits_per_text)
if not return_dict: output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs) return ((loss,) + output) if loss is not None else output










