- 什么是 GPU 以及 CUDA 核心和 Tensor 核心的介绍
- 大模型应用中如何选择GPU和云服务厂商,追求最高性价比
- 如何部署自己 fine-tune 的模型,向业务提供高可用推理服务
初识 GPU硬件选型当我们为模型训练及推理做硬件选型时,NVIDIA 几乎是唯一选择。这是一家全球知名的图形处理器(GPU)公司,成立于 1993 年。因为在 GPU 领域,尤其 AI 领域芯片的垄断性优势,其创始人黄仁勋被坊间称为「黄教主」 
什么是 GPUGraphical Processing Units (GPUs) 
CUDA 核心和 Tensor 核心CUDA 核心- 是 NVIDIA 开发的并行计算平台和编程模型,用于 GPU 上的通用计算,就像是万能工人,可以做很多不同的工作
案例 1:视频渲染当一个电影制片公司决定制作一部具有高度视觉效果的 3D 电影时,他们需要大量的计算能力来渲染每一帧。这里,CUDA 核心非常有用,因为它们能够处理大量的细节,如光线追踪、纹理和阴影。例如,当一束光从一个光源反射到一个物体上,然后反射到摄像机上,CUDA 核心可以用来计算这个光线路径上的所有细节,确保最终的图像看起来真实并且美观。
Tensor 核心- 专门设计用于深度学习中的矩阵运算,加速深度学习算法中的关键计算过程
案例 2:面部识别安全系统、智能手机和许多应用程序现在都使用面部识别技术。这需要通过深度学习模型来识别人的面部特征。Tensor 核心在这里发挥关键作用,它们可以迅速地处理神经网络中的大量矩阵乘法和加法,确保面部识别既准确又快速。
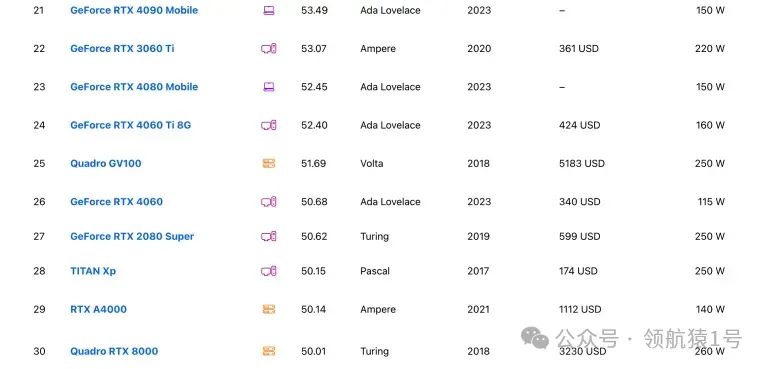
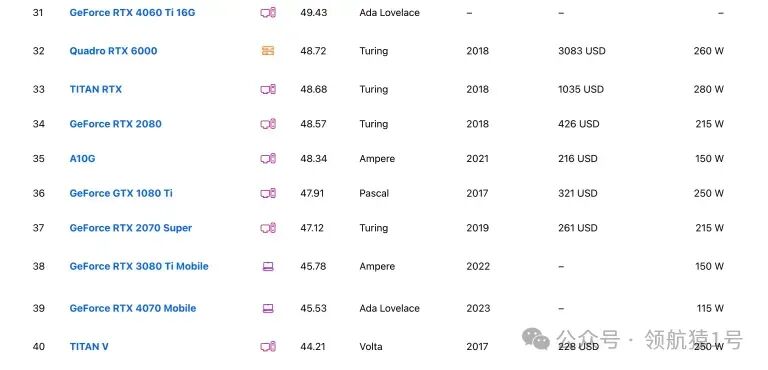
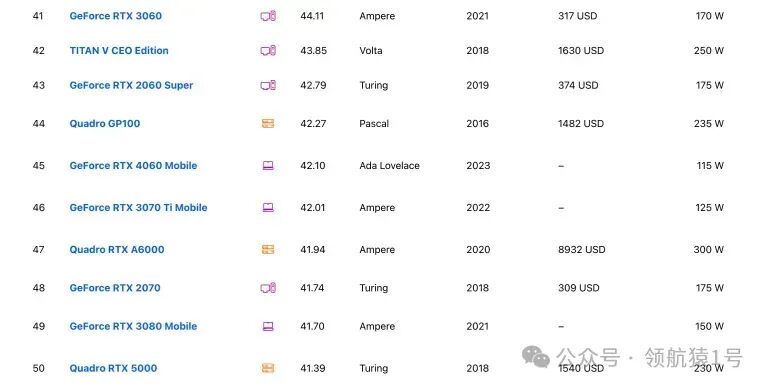
AI 领域常用 GPUAI 常用 GPU 价格排序这个表格依据价格进行排序,价格从低到高。更多排名看后面《NVIDIA显卡排行榜》章节介绍。 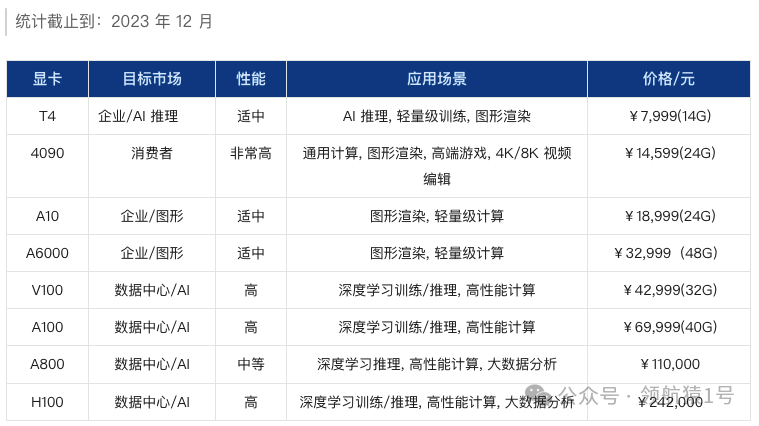
- 美国商务部限制 GPU 对华出口的算力不超过 4800 TOPS 和带宽不超过 600 GB/s,导致最强的 H100 和 A100 禁售。黄教主随后推出针对中国市场的 A800 和 H800。
- 英伟达 A100 和 H100 已被禁止向中国供货
- 50 亿美元,算力芯片迎来狂欢,腾讯字节抢购英伟达 A800 订单
H100 与 A100H100 比 A100 快多少? 16-bit 推理快约 3.5 倍,16-bit 训练快约 2.3 倍。 https://timdettmers.com/2023/01/30/which-gpu-for-deep-learning/ 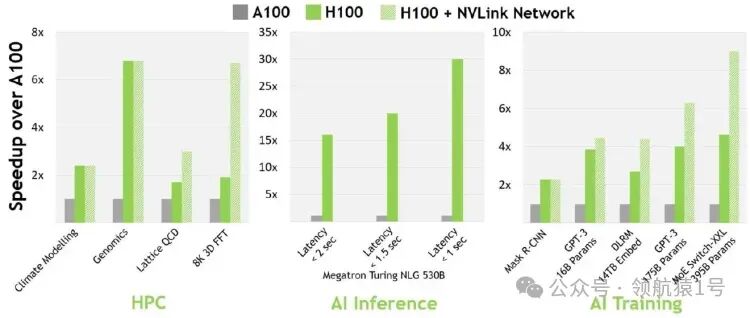
根据场景选择GPU以下是我们为您提供的,基于显卡 4090 上的 chatglm 和 chatglm2 模型的 Fine tuning 实验数据概览: 模型 | 数据条数 | 时长 | 技术 | chatglm | 9999 | 1:42:46 | pt2 | chatglm | 39333 | 6:45:21 | pt2 | chatglm | 9999 | 1:31:05 | Lora | chatglm | 39333 | 5:40:16 | Lora | chatglm2 | 9999 | 1:50:27 | pt2 | chatglm2 | 39333 | 7:26:25 | pt2 | chatglm2 | 9999 | 1:29:08 | Lora | chatglm2 | 39333 | 5:45:08 | Lora |
llm-utils 上一些选型的建议根据不同的使用情境,以下是使用的建议GPU: 模型 | 显卡要求 | 推荐显卡 | Running Falcon-40B | 运行 Falcon-40B 所需的显卡应该有 85GB 到 100GB 或更多的显存 | See Falcon-40B table | Running MPT-30B | 当运行 MPT-30B 时,显卡应该具有80GB的显存 | See MPT-30B table | Training LLaMA (65B) | 对于训练 LLaMA (65B),使用 8000 台 Nvidia A100 显卡。 | Very large H100 cluster | Training Falcon (40B) | 训练 Falcon (40B) 需要 384 台具有 40GB 显存的 A100 显卡。 | Large H100 cluster | Fine tuning an LLM (large scale) | 大规模微调 LLM 需要 64 台 40GB 显存的 A100 显卡 | H100 cluster | Fine tuning an LLM (small scale) | 小规模微调 LLM 则需要 4 台 80GB 显存的 A100 显卡。 | Multi-H100 instance |
不同情况推荐- 对于本地个人研发项目,GeForce RTX 4090 等消费级 GPU 足以满足中等规模的需求。
- 对于公司的大规模数据和复杂模型,推荐使用如 NVIDIA A100 的高性能 GPU。
- 数据规模小时,可考虑预算内的 A10 或 T4 型号。
- 如果追求性价比,可以选择把 4090 显卡搭建服务器使用,也可以选择市面的第三方服务,比如:AutoDL 的 4090 服务
1、大模型内存选择 大模型训练需要高性能的计算机硬件来保证训练的效率和速度。建议选择具有高速的ECC或DDR5内存。现在训练时一般在 GLM 、 LLaMA 等大模型的基础上进行训练,国内会选择 A800/H800 x 8 的 GPU 配置,与此同时内存一般会选择相似大小以提升效率,常规选择 512 内存。 2、大模型所需磁盘 大模型训练需要存储大规模的数据集和模型参数,因此需要足够的存储资源来保证数据能够快速地被读取和处理。建议选择具有大容量、高速的存储设备,如 SSD 或 NVMe 固态硬盘。一般 4T-8T 不等。 3、推荐配置参考 GPU算力平台:大模型训练、自动驾驶、深度学习解决方案。 - CPU:2*8358(32核心,铂金版,2.6GHz 超频 3.4GHz)
- GPU:NVIDIA HGX A100/A800(80G SXM)
- CPU:2*8468(48核心,铂金版,2.1GHz 超频 3.8GHz)
- GPU:NVIDIA HGX H100/H800(80G SXM5)
物理机 vs. 云服务云服务厂商对比国内主流- 阿里云:https://www.aliyun.com/product/ecs/gpu
- 腾讯云:cloud.tencent.com/act/pro/gpu…
- 火山引擎:www.volcengine.com/product/gpu
国外主流TPU 是 Google 专门用于加速机器学习的硬件。它特别适合大规模深度学习任务,通过高效的架构在性能和能源消耗上表现出色。 它的优点和应用场景 - 高性能和能效: TPU 可以更快地完成任务,同时消耗较少的能源,降低成本。
- 大规模训练: TPU 适用于大规模深度学习训练,能够高效地处理大量数据。
- 实时推理: 适合需要快速响应的任务,如实时图像识别和文本分析。
- 云端使用: Google Cloud 提供 TPU 服务,允许用户根据需求使用,无需购买硬件。
适用于图像处理、自然语言处理、推荐系统等多个领域。在国外,科研机构、大公司和初创企业普遍使用 TPU。 NVIDIA GPU 在主流厂商的价对比下面是对两款 NVIDIA GPU 在火山引擎、阿里云、腾讯云的价格进行对比: NVIDIA A100: 云服务提供商 | GPU 型号 | CPU 核心数 | 内存(GiB) | 价格(元/小时) | 火山引擎 | A100 | 14 核 | 245 | 40.39 | 阿里云 | A100 | 16 vCPU | 125 | 34.742 | 腾讯云 | A100 | 16 核 | 96 | 28.64 |
NVIDIA T4: 云服务提供商 | GPU 型号 | CPU 核心数 | 内存(GiB) | 价格(元/小时) | 阿里云 | T4 | 4 vCPU | 15 | 11.63 | 火山引擎 | T4 | 4 核 | 16 | 11.28 | 腾讯云 | T4 | 8 核 | 32 | 8.68 |
算力平台主要用于学习和训练,不适合提供服务。 Colab:谷歌出品,升级服务仅需 9 美金。colab.google.com Kaggle:免费,每周 30 小时 T4,P100 可用。www.kaggle.com AutoDL:价格亲民,支持 Jupyter Notebook 及 ssh,国内首选。www.autodl.com
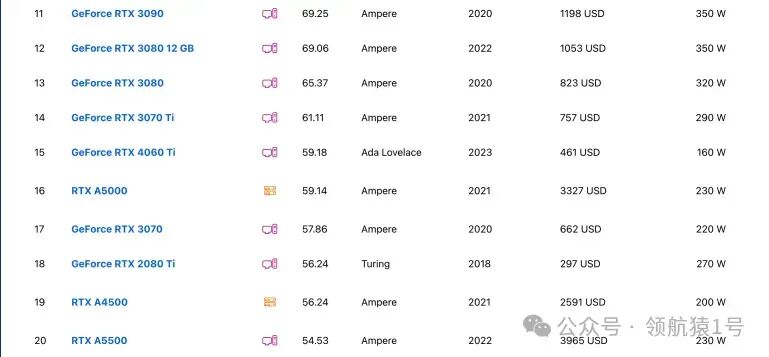
建议:若需高速下载,尤其依赖于 GitHub 或 Docker 官方镜像,建议选择国外服务器。 NVIDIA显卡排行榜此网站能实时对比各种型号显卡 https://technical.city/zh/video/nvidia-rating Top 100下面截图给大家 Top 100,详细请看原文链接。 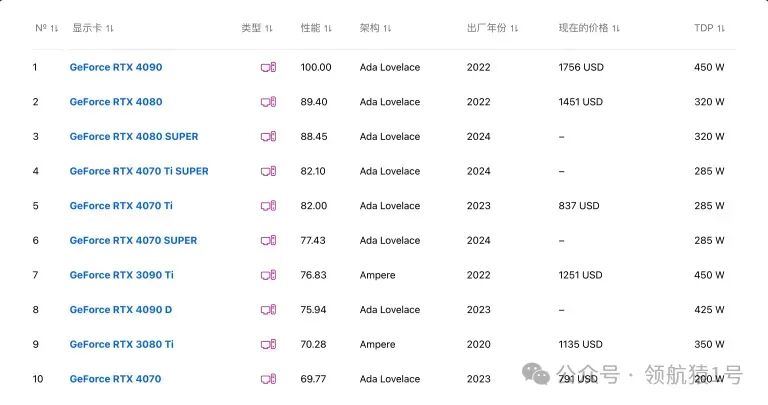
| 









