|

ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">在各种网络信息数据爆棚的今天,企业和个人数据安全和隐私保护开始受到大家的重视。随着开源大语言模型LAMA3的全新升级,使得在本地构建私有化服务提供极大的方便。ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">今天给大家带来一点Llama3本地化部署的一点思路,仅作简单演示,希望能抛砖引玉,给各位小伙伴带来一点启发。这次演示的框架不仅融合了先进的搜索引擎功能,更在本地知识库的加持下,为您提供了一个既智能又安全的信息处理平台:ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">?️ 安全为本:本地知识库的深度整合,确保数据安全,隐私无忧。ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">? 智能搜索:搭载先进搜索引擎,精准捕捉信息,提升决策效率。ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">? 文档通读:无缝读取PDF等文档,信息获取更快捷,隐私保护更全面。下面进入正题,首先演示功能比较简单,这里使用一个现成的开源框架,对于有一定编程基础的兄弟,完全可以手撸一个。
准备材料:
ollama:https://ollama.com/download docker :https://www.docker.com/products/docker-desktop/ phidata:https://github.com/phidatahq/phidata 先安装ollama和docker
然后打开CMD窗口拉取phidata项目,使用conda安装虚拟环境
gitclonehttps://github.com/phidatahq/phidata.gitcdphidatacondacreate-nphidatapython=3.9--yespipinstall-Uphidatapipinstall-rrequirements.txtpipinstallollamatavily-pythonstreamlit 环境安装好之后我们使用tavily来调用搜索引擎API获取网络信息推送给Llama3处理。这里只是演示,你可以根据自己需要换其他搜索接口。 https://app.tavily.com/home到这里注册一个账户获取api key,不要钱 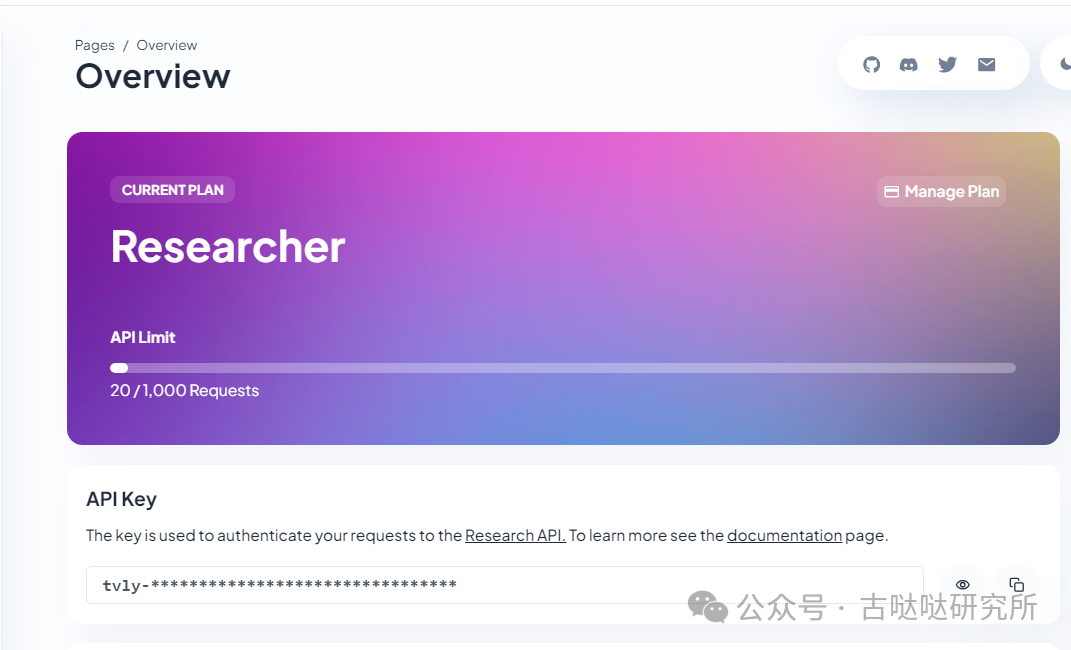
创建一个环境变量,替换成你自己的key win:setTAVILY_API_KEY=tvly-xxxxxxxxxxxlinux:exportTAVILY_API_KEY=tvly-xxxxxxxxxxx 将下面的代码保存到位于项目根目录的python文件中
from phi.assistant import Assistantfrom phi.llm.ollama import OllamaToolsfrom phi.tools.tavily import TavilyTools
# 创建一个Assistant实例,配置其使用OllamaTools中的llama3模型,并整合Tavily工具assistant = Assistant(llm=OllamaTools(model="llama3",host="127.0.0.1:11434"),#使用OllamaTools的llama3模型tools=[TavilyTools()],show_tool_calls=True,# 设置为True以展示工具调用信息)
# 使用助手实例输出请求的响应,并以Markdown格式展示结果assistant.print_response("Search tavily for 'GPT-5'", markdown=True)
保存之后运行python文件
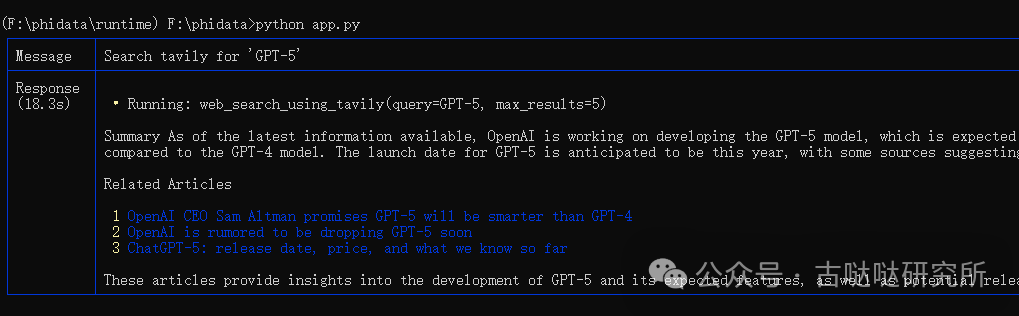
窗口返回了查询结果,一段GPT-5的介绍和几个相关的网页链接,这就为Llama3提供了实时联网过去最新信息的能力。框架提供多种联网查询的工具这里就不每个介绍了,有兴趣的可以看项目文档,功能十分丰富,三天三夜讲不完。 
由于这是一个国外的开源项目,提供的接口对墙内不太友好,需要自备网络环境,也可以自己动手封装国内搜索接口,项目提供了详细的开发文档,非常的Nice。
接下来,再来看一看项目中如何使用Ollama和PgVector进行完全本地文档的检索增强生成(RAG) 所有操作在项目根目录下完成 安装Embeddings模型和依赖: ollamapullnomic-embed-textpipinstall-rcookbook/llms/ollama/rag/requirements.txt 使用Docker运行PgVector dockerrun-d-ePOSTGRES_DB=ai-ePOSTGRES_USER=ai-ePOSTGRES_PASSWORD=ai-ePGDATA=/var/lib/postgresql/data/pgdata-vpgvolume:/var/lib/postgresql/data-p5532:5432--namepgvectorphidata/pgvector:16streamlitruncookbook/llms/ollama/rag/app.py 然后打开浏览器:http://localhost:8501/ 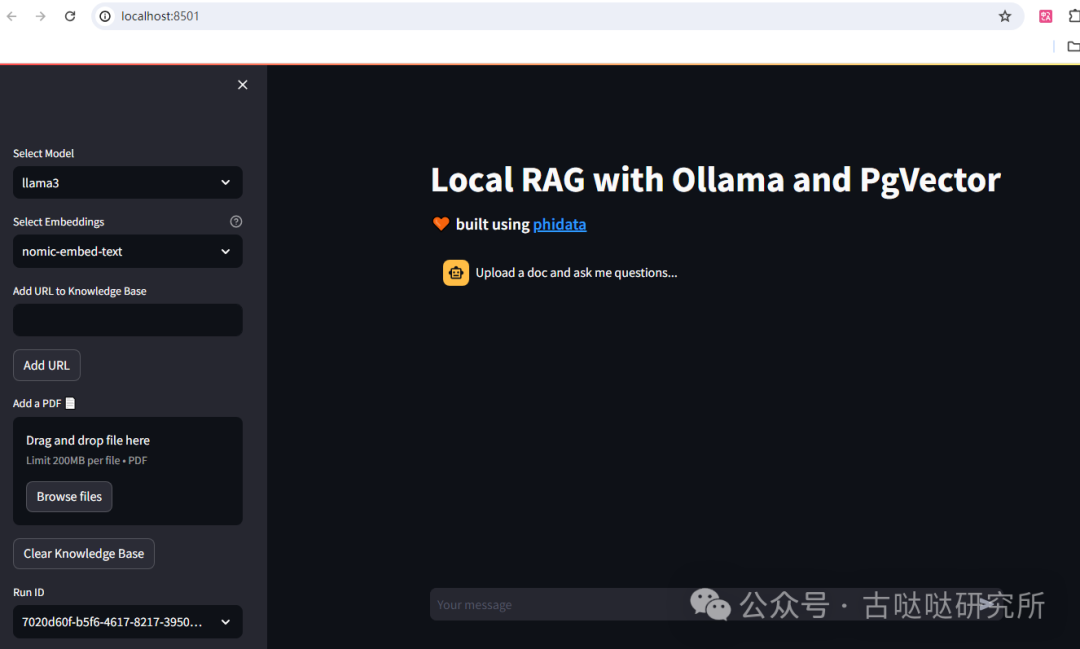
现在就可以上传PDF文档生成向量数据库供Llama3调用了。
以上只是使用了项目中两个小模块做演示。 强烈推荐读一下项目的cookbook目录中提供了大量编写好的示例代码,需要的时候可以拿来直接用 
兼容大部分的模型接口框架,模型随便换,一切你说了算。
推荐使用linux系统,windows也可以用,但是随时出现各种坑都需要自己解决。
免费GPT3.5:把网页版 ChatGPT 封装成 API
ChatDev:虚拟软件公司的多AI角色(CEO、CTO、码农、测试)可协作完成软件开发,可接入Ollama和国产大模型一键申请大模型API,支持国内信用卡,解决API难题!
Kimi等六家国产大模型API免费用,Llama3瞬间不香了
SuperDuperDB:一行代码将任何AI模型与公司业务数据库集成
Chat-GPT一站式解决方案:从注册到使用免翻墙 & 免接码
Perplexity AI:平替GPT4 New Bing,真的很好用
影刀RPA+Chat-GPT = 知乎自动答题机器人
| 









