|
信息提取(IE)旨在从非结构化文本中提取结构化信息。关系抽取作为IE的一个子领域,目的是识别出实体(S和O)之间特定的关系(P)。现有的基于神经学习的方法在精确度上表现良好,但存在召回率(即识别出所有相关实体的能力)有限的问题。此外,这些方法大多只能处理单个段落,而无法从长篇文本中提取信息。因此,提出了从长文本(如整本书或多个网页)中提取与特定主题相关的长对象列表的问题。 从长文本中提取长列表的示例。以主题‘哈利·波特’为例,目标是提取整个系列书籍中出现的57位朋友。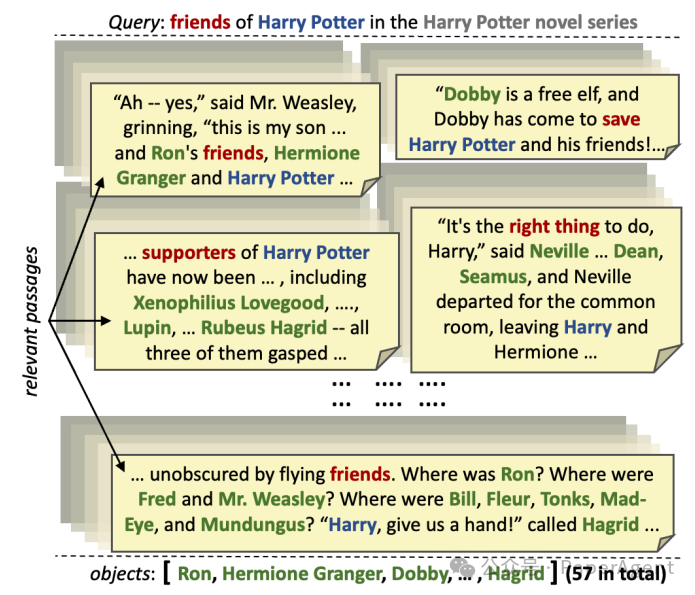
L3X(LM-based Long List eXtraction,基于语言模型的长列表抽取)方法包含两个阶段:召回导向的生成:使用当前主题和关系提示大型语言模型(LLM),并要求其使用多种提示表述生成一个完整的对象列表。利用信息检索(IR)系统从长文本中找到有前景的候选段落,并将它们输入到LLM的提示中。与以往关于检索增强型LLM的工作不同,检索了大量这样的段落(例如,对于给定的SPO对可能有500个),并谨慎地选择最佳的段落进行提示。还会迭代地重新对段落进行排名,并对LLM重新提示,以改进对象的初始生成。精确导向的审查:在生成了高召回率的对象候选列表之后,使用保守技术来验证或修剪这些候选对象。这包括使用技术来识别高置信度的对象及其支持段落,并重新评估低置信度的候选对象。通过在新构建的数据集上进行实验,该数据集包含10本书籍和8种关系类型 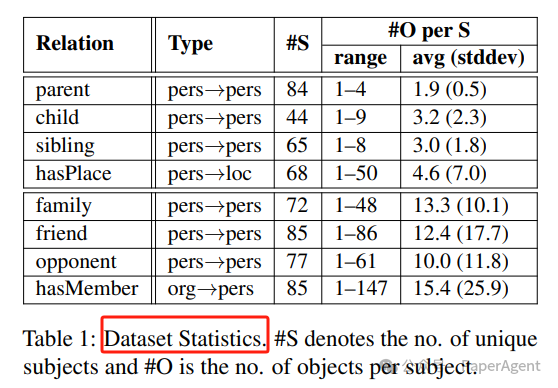
L3X方法在召回率和R@P指标上显著优于仅使用LLM生成的方法。L3X方法能够有效地从长文本中提取长对象列表,并且通过不同的提示、段落排名和批处理技术,可以进一步提高性能。 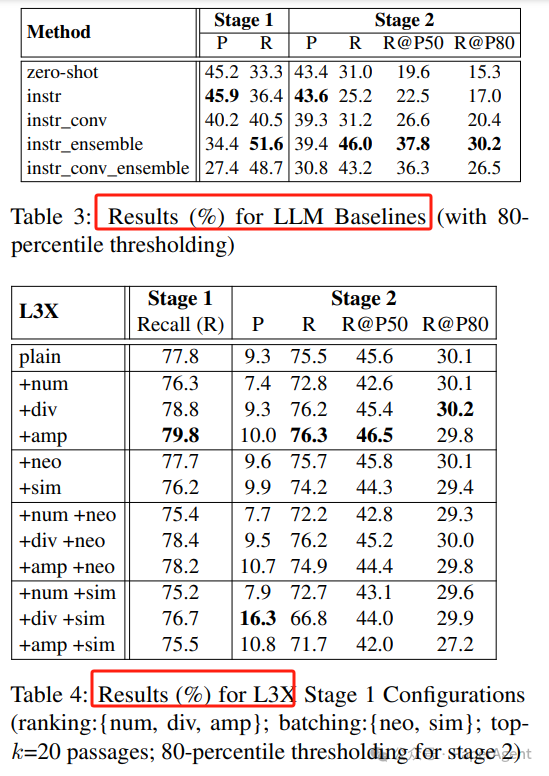
RecallThemAll:Retrieval-AugmentedLanguageModelsforLongObjectListExtractionfromLongDocumentshttps://arxiv.org/pdf/2405.02732 推荐阅读 | 









